智能音箱语音交互系统简介与测试初探
随着AI技术的发展,智能语音交互技术也得到了巨大的发展和应用。由于语音是最自然的交互形态之一,有着输入效率高、门槛低、方便解放双手以及能有效进行情感交流的优势,使得智能音箱成为语音交互的典型应用产品。智能音箱的背后是一套智能语音交互系统平台,由于笔者最近参与了公司内的智能语义平台与智能音箱的测试开发项目,对这一系统有了基本的认知和理解,本文就语音交互平台的相关概念和基本测试指标进行一下讲解和介绍。
![]()
一个完整的语音交互流程
![]()
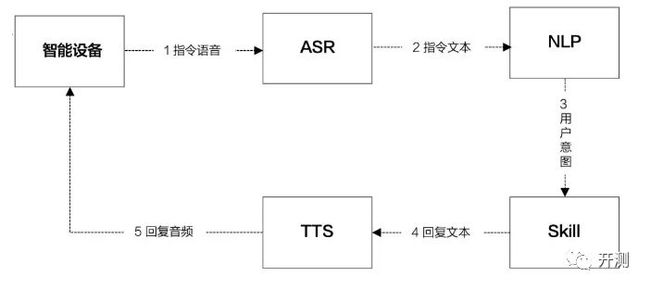
如下图所示,一次完整的语音交互,包含:唤醒→ASR→NLP→TTS→Skill的流程。
下面主要对系统中的主要流程进行讲解。
唤醒
唤醒即激活音箱设备,智能音箱有别于智能手机的语音交互,需要先激活音箱,激活的办法有两类。
传统的方式是**:**通过按键激活,例如:锤子的大卫和Siri音箱,增加了外设的按钮,可以点击按钮激活音箱进行说话。
业界的普遍做法是**:**通过设置激活词来唤醒音箱,例如:“小宝小宝”,“小爱同学”,“小雅小雅”。
为什么唤醒词普遍是4音节,而不是中国人更习惯的3音节或者2音节?
这是因为音节越短,误唤醒的问题就会越严重。
**误唤醒是指:**设备被环境音错误激活。
误唤醒的压制是行业难题,除了模型优化,还有几种普遍的做法:
01
云端2次校验——即将用户的语音上传到云端进行2次确认,再决定本地是否响应,但是带来的弊端就是唤醒响应时间被拉长。
一般设备的唤醒检测模块都是放在本地的,这是为了可以快速响应,本地响应可以将响应时间控制在300-700ms之间。如果进行云端2次确认,这个识别降低唤醒的响应时长,会被延长到900ms~1.2S之间,如果网络环境差,这个时间可能更久。
02
从产品策略入手。一般白天偶尔的误唤醒用户都是可以理解的,或者说习以为常了。但是,如果是晚上睡觉时发生误唤醒,用户都是零容忍。
因此,一种做法是压制晚上的误唤醒,带来的问题是晚上唤醒的敏感度也同步降低,但是整体来看还是可以接受的。
唤醒词还承载了另外一个功能那就是声纹检测。业内的普遍做法是基于唤醒词的校对来判断用户身份,当然也有基于用户指令语句来识别的。
但是,目前业内普遍声纹识别的准确率不是特别高,当用户感冒、变音调,声纹识别就会失效,因此声纹在智能音箱的应用就非常受限。除了声纹支付,只能应用于对召回率要求不高的应用场景。
首先绍下语音唤醒(Voice Trigger,VT)的相关信息。
A、语音唤醒的需求背景
近场识别时,比如使用语音输入法时,用户可以按住手机上siri的语音按钮,直接说话(结束之后松开);近场情况下信噪比(Signal to Noise Ratio, SNR)比较高,信号清晰,简单算法也能做到有效可靠。
但是在远场识别时,比如在智能音箱场景,用户不能用手接触设备,需要进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
B、语音唤醒的含义
简单来说是“喊名字,引起听者(AI)的注意”。如果语音唤醒判断结果是正确的唤醒(激活)词,那后续的语音就应该被识别;否则,不进行识别。
C、语音唤醒的相关指标
1.唤醒率。叫AI的时候,ta成功被唤醒的比率。
2.误唤醒率。没叫AI的时候,ta自己跳出来讲话的比率。如果误唤醒比较多,特别是比如半夜时,智能音箱突然开始唱歌或讲故事,会特别吓人的……
3.唤醒词的音节长度。一般技术上要求,最少3个音节,比如“OK Google”和“Alexa”有四个音节,“Hey Siri”有三个音节;国内的智能音箱,比如小雅,唤醒词是“小雅小雅”,而不能用“小雅”——如果音节太短,一般误唤醒率会比较高。
4.唤醒响应时间。一般1.5s到3s。超过3s就不能容忍了。
5.功耗(要低)。看过报道,说iPhone 4s出现Siri,但直到iPhone 6s之后才允许不接电源的情况下直接喊“Hey Siri”进行语音唤醒;这是因为有6s上有一颗专门进行语音激活的低功耗芯片,当然算法和硬件要进行配合,算法也要进行优化。
以上1、2、3相对更重要
D、其他
涉及AEC(语音自适应回声消除,Automatic Echo Cancellation)的,还要考察WER(词错误率,Word Error Rate)相对改善情况。
语音识别ASR
语音识别ASR(Automatic Speech Recognition)一般简称ASR,是将声音转化为文字的过程,相当于人类的耳朵。用于将声学语音进行分析,并得到对应的文字或拼音信息。
语音识别系统一般分为:训练和解码两阶段。
训练
通过大量标注的语音数据训练数学模型,通过大量标注的文本数据训练语言模型。
市场上主流的声学训练模型有:时序连接分类(CTC)和卷积递归神经网络(CRNN)。
解码
通过声学和语言模型将语音数据识别成文字。
声学模型可以理解为是对发生的建模,它能够把语音输入转换成声学表示的输入,更准确的说是给出语音属于某个声学符号的概率。
语言模型的作用可以简单理解为消解多音字问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
为了提供特定内容的识别率,一般都会提供热词服务,配置的热词内容实时生效,并且会提升ASR结果的识别权重,在一定程度上提高ASR识别的准确率。
ASR还有一些其他的技术细节在实际应用中起着关键作用:
**寻向/声源定位:**一般音箱的设计都是多麦克风,例如:4麦、6麦,呈线性或环形布局。寻向的作用就是判断用户方向,然后用用户方向的麦克风采集语音数据,保证语音的数据是最清晰的。
**降噪:**当有环境音时,需要对环境音进行消除,提高算法识别准确率。
**AEC:**回音消除,如果当前设备既在使用Player进行播放,同时又使用Mic进行拾音,那Mic就会将自己播放出去的声音给重拾回来。这时为了避免影响算法识别结果,需要对回音进行消除。
**VAD:**语音端点检查,使用音频特征等进行分析,确定人声的开始和结束时间点。
自然语言处理(理解)NLP(NLU)
自然语言理解就是将人的语言形式转化为机器可理解的、结构化的、完整的语义表示,通俗来讲就是让计算机能够理解和生成人类语言。
将用户的指令进行Domain(领域)→Intent(意图)→Slot(词槽)三级拆分。
以“帮我设置一个明天早上8点的闹钟”为例:该指令命中的领域是“闹钟”,意图是“新建闹钟”,词槽是“明天8点”。
这样,就将用户的意图拆分成机器可以处理的语言。
在NLU领域中涉及到两个重要概念,也是评测系统好坏的重要指标。
在这里简单介绍一下:准确率和召回率。
**准确率:**识别为正确的样本数/识别出来的样本数
**召回率:**识别为正确的样本数/所有样本中正确的数
举个栗子:全班一共30名男生、20名女生。需要机器识别出男生的数量。本次机器一共识别出20名目标对象,其中18名为男性,2名为女性。则
准确率=18/(18+2)=0.9
召回率=18/30=0.6
再补充一个图来解释

技能Skill
Skiil,技能,也即AI时代的APP。
Skill的作用就是:处理NLP界定的用户意图,做出符合用户预期的反馈。
语音skill的设计与产品APP差别很大,笔者经过一段时间的积累,总结了一下测试原则供参考:
测试
原则
1
增加回复的多样性——高频的指令尽可能增加多的回复TTS语句,避免用户反复听到相同的回复;
2
重要信息后置——一般语音回复尤其是当用户在开车的过程中,需要将重要信息放在后面,因为心理学上有个“时近效应”,听觉刺激往往排在后面的影响力更大;
3
合理的简洁——用户可感知时简洁回复,用户不可感知时完整回复。;
假如用户指令“停止播放”,这时候只需一个提示音或者一个简答的回复“好的”。但是,如果用户的指令是“帮我设置一个明天早上8点的闹钟”,回复就需要是完整的,例如:“已帮你设置好明天早上8点的闹钟”,否则用户会没安全感,不知道你设置的到底对不对,如果不对,那带来的风险是很大的,所以一定要完整回复。
语音合成TTS
语音合成(Text-To-Speech),一般简称TTS,是将文字转化为声音(朗读出来),类比于人类的嘴巴。大家在Siri等各种语音助手中听到的声音,都是由TTS来生成的,并不是真人在说话。
TTS业内普遍使用两种做法:一种是拼接法,一种是参数法。
- 拼接法
从事先录制的大量语音中,选择所需的基本发音单位拼接而成。
**优点:**语音的自然度很好。
**缺点:**成本太高,费用成本要上百万。
- 参数法
使用统计模型来产生语音参数并转化成波形。
**优点:**成本低,一般价格在20万~60万不等。
**缺点:**发音的自然度没有拼接法好。
但是随着模型的不断优化,现在参数法的效果已经非常好了,因此业内使用参数法的越来越多。
对TTS的测试主要分主观测试和客观测试:
主观测试
1.MOS(Mean Opinion Scores),专家级评测(主观);1-5分,5分最好。
2.ABX,普通用户评测(主观)。让用户来视听两个TTS系统,进行对比,看哪个好。
主观测试以MOS为主。
客观测试
1.对声学参数进行评估,一般是计算欧式距离等(RMSE,LSD)。
2.对工程上的测试:实时率(合成耗时/语音时长),流式分首包、尾包,非流式不考察首包;首包响应时间(用户发出请求到用户感知到的第一包到达时间)、内存占用、CPU占用、3*24小时crash率等。
以上便是对智能音箱系统交互流程和测试指标的简单介绍,希望对大家有所帮助。
哈喽,喜欢这篇文章的话烦请点个赞哦!万分感谢(^▽^)PS:有问题可以联系我们哦v ceshiren001
复制“下方链接”,提升测试核心竞争力!
更多技术文章分享和免费资料领取