python导入鸢尾花数据集_数据可视化——鸢尾花数据集的分析与散点图的绘制
**
数据可视化——鸢尾花数据集的分析及散点图的绘制
话不多说,直接上代码。
我们先来看一下鸢尾花数据集。

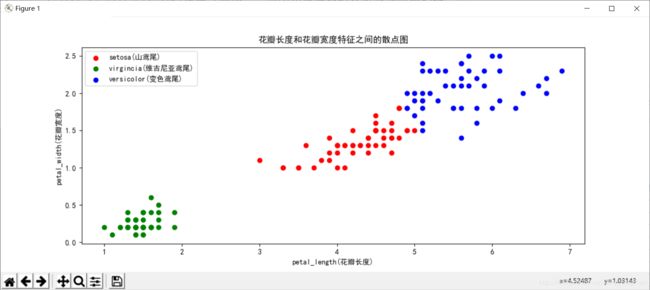
#读取鸢尾花卉数据集,绘制“花瓣长度”和“花瓣宽度”特征之间的散点图。
在导入如下几个库之前,请首先检查pip list,即个人PC是否已经安装了对应的第三方库。
安装命令:pip install
如果遇到安装超时的情况,可以使用清华的源:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
更换为要下载的第三方库
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans#K-means算法
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]#用来正常显示中文
iris_data=pd.read_csv(r’./iris.csv’)
X=iris_data[[‘petal_length’,‘petal_width’]]
print(X.shape)#这里看一下有没有数据缺失
#绘制数据分布图
estimator=KMeans(n_clusters=3)#构造聚类器
estimator.fit(X)#聚类
label_pred=estimator.labels_#获取聚类标签
#开始绘制K-means结果
x0=X[label_pred==0]#对应setosa
x1=X[label_pred==1]#对应vigincia
x2=X[label_pred==2]#对应versicolor
#这里使用了df.values,因为操作的是一个dataframe类型,所以应该转换成ndarry
plt.scatter(x0.values[:,0],x0.values[:,1],c=‘r’,marker=‘o’,label=‘setosa(山鸢尾)’)
plt.scatter(x1.values[:,0],x1.values[:,1],c=‘g’,marker=‘o’,label=‘virgincia(维吉尼亚鸢尾)’)
plt.scatter(x2.values[:,0],x2.values[:,1],c=‘blue’,marker=‘o’,label=‘versicolor(变色鸢尾)’)
plt.xlabel(‘petal_length(花瓣长度)’)
plt.ylabel(‘petal_width(花瓣宽度)’)
plt.title(‘花瓣长度和花瓣宽度特征之间的散点图’)
plt.legend(loc=2)#把图例放到左上角
plt.show()
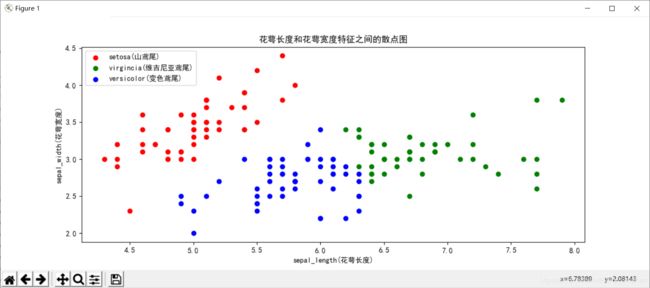
#读取鸢尾花卉数据集,绘制“花萼长度”和“花萼宽度”特征之间的散点图。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans#K-means算法
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]#用来正常显示中文
iris_data=pd.read_csv(r’./iris.csv’)
X=iris_data[[‘sepal_length’,‘sepal_width’]]
print(X.shape)#这里查看一下有没有数据缺失
#绘制数据分布图
estimator=KMeans(n_clusters=3)#构造聚类器
estimator.fit(X)#聚类
label_pred=estimator.labels_#获取聚类标签
#开始绘制K-means结果
x0=X[label_pred==0]#对应setosa
x1=X[label_pred==1]#对应vigincia
x2=X[label_pred==2]#对应versicolor
#这里使用了df.values,因为操作的是一个dataframe类型,所以应该转换成ndarry
plt.scatter(x0.values[:,0],x0.values[:,1],c=‘r’,marker=‘o’,label=‘setosa(山鸢尾)’)
plt.scatter(x1.values[:,0],x1.values[:,1],c=‘g’,marker=‘o’,label=‘virgincia(维吉尼亚鸢尾)’)
plt.scatter(x2.values[:,0],x2.values[:,1],c=‘blue’,marker=‘o’,label=‘versicolor(变色鸢尾)’)
plt.xlabel(‘sepal_length(花萼长度)’)
plt.ylabel(‘sepal_width(花萼宽度)’)
plt.title(‘花萼长度和花萼宽度特征之间的散点图’)
plt.legend(loc=2)#把图例放到左上角
plt.show()
就是这么多了,不会的可以私聊。
祝大家学习愉快。
原文链接:https://blog.csdn.net/Harry_Stephen/article/details/106696230