spark-sql字段级血缘关系实现
1.背景:
血缘关系非常重要,因为有了字段间的血缘关系,便可以知道数据的来源去处,以及字段之间的转换关系,这样对数据的质量,治理有很大的帮助。
Spark SQL 相对于 Hive 来说通常情况下效率会比较高,对于运行时间、资源的使用上面等都会有较大的收益。所以考虑将采用MapReduce引擎执行的sql进行迭代,以spark引擎执行。但同时也需要实现字段血缘的功能。hive血缘关系实现较为简单,攻略也比较多,这spark血缘关系攻略较少,这里提供一种解析思路。
2.需求:
在使用spark引擎执行sql时,将表与表,字段与字段的血缘信息解析出来,可视化展示。
3.思路:
使用QueryExecutionListener对spark进行监听,读取出sparkplan(物理计划),解析其中包含的血缘关系,将血缘关系导入neo4j,spring-boot写接口,前端请求返回表的血缘关系。
4.实现:
QueryExecutionListener:监听和用于分析spark-sql执行过程中的的一些指标
The interface of query execution listener that can be used to analyze execution metrics.
trait QueryExecutionListener {
@DeveloperApi
def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit
@DeveloperApi
def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit
}class SparkListenerTest extends QueryExecutionListener{
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {
}
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
val sparkPlanJson: String = qe.sparkPlan.prettyJson
}
}了解一下整个sql在spark中的解析过程
sql —(ANTLR4) —> AST —(Spark AstBuilder) —> Unresolved LogicalPlan — (Catalog) —> Resolved LogicalPlan — (Optimizer) —> Optimized LogicalPlan — (SparkPlanner) —> PhysicalPlan(SparkPlan) —(prepareForExecution) —> ExecutionPlan(PhysicalPlan)
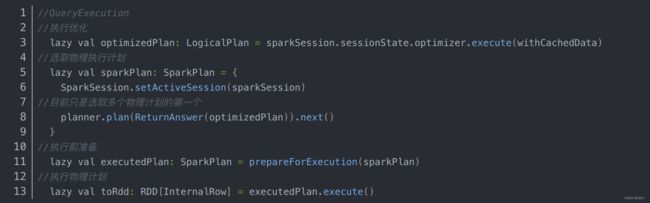
QueryExecution可以获取到的信息如下:

logicalPlan: 逻辑计划并不知道如何执行,比如不知道表的类型(hive还是hbase),如何获取数据(jdbc还是读取hdfs),数据分布是什么样的(bucketed还是hashDistrobuted),这时就需要将逻辑计划树转换成物理计划树,获取真实的物理属性
sparkPlan:就是刚刚提到的物理计划树,这里我们监听获取sparkplan的Json信息
这段JSON获取目标表的所有信息

table和database

第一个Project包含了目标表的信息和血缘信息(下面说),其中projectList就是表中的字段信息,第一个Project就是insert into xxx 的 xxx(目标表target)

spark会给每个字段打上一个唯一自增的id(logicalPlan打上的),我们将信息存放在map里(id -> database.table.column)
这里很重要,因为就是使用id将字段和字段之间关联的

LogicalRelation包含了源头表的所有信息,output中包含了字段信息,catalogTable中包含了表名和库名(多个源头表就会有多个LogicalRelation)

字段信息和id 
表名和库名

上面说的第一个Project非常重要,因为第一个Project不仅仅包含了目标表的字段信息,还包含了这些字段来自哪个字段,去刚刚存放的map里匹配,将结果放入新map(sourcecolumn -> targetcolumn)

代码:
class SparkListenerTest extends QueryExecutionListener{
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {
}
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
// println(qe.analyzed.prettyJson)
// println("-------------------------------")
// println(qe.logical.prettyJson)
// println("-------------------------------")
// println(qe.optimizedPlan.prettyJson)
// println("-------------------------------")
// println(qe.sparkPlan.prettyJson)
// println("-------------------------------")
// println(qe.executedPlan.prettyJson)
val sparkPlanJson: String = qe.sparkPlan.prettyJson
//获取数据写入的相关的json信息,其中可以将血缘关系解析出来
val dataWritingCommandExec = JSON.parseArray(sparkPlanJson).get(0)
//id与字段的对应关系
val allTableInfo = new util.HashMap[String, String]()
//目标表
var targetDatabaseTable = ""
//源头表
val sourceDatabaseTables = new util.ArrayList[String]()
//目标表与源头表中字段与字段的对应关系
val allColumnRelation = new util.HashMap[String, String]()
//判断一下是否为insert语句,不是的话不需要解析
if(JSON.parseObject(dataWritingCommandExec.toString).getString("class").contains("DataWritingCommandExec")) {
val cmd = JSON.parseObject(dataWritingCommandExec.toString).getJSONArray("cmd").toArray()
for (c <- cmd) {
//这里只写了目标表为hive表的情况 获取目标表
if (JSON.parseObject(c.toString).getString("class").contains("InsertIntoHiveTable")) {
//table的所有信息
val tableInfo = JSON.parseObject(c.toString).getString("table")
val identifier = JSON.parseObject(tableInfo).getString("identifier")
//table name
val table = JSON.parseObject(identifier).getString("table")
//database
val database = JSON.parseObject(identifier).getString("database")
targetDatabaseTable = database + "." + table //目标表
// println(targetDatabaseTable)
}
//获取源头表
if (JSON.parseObject(c.toString).getString("class").contains("LogicalRelation")) {
//catalog
val catalogTable = JSON.parseObject(c.toString).getString("catalogTable")
val identifier = JSON.parseObject(catalogTable).getString("identifier")
//table name
val table = JSON.parseObject(identifier).getString("table")
//database
val database = JSON.parseObject(identifier).getString("database")
//将源头表加入list中
sourceDatabaseTables.add(database + "." + table)
val output = JSON.parseObject(c.toString).getJSONArray("output").toArray()
//获取字段信息
for (o <- output) {
val detail = JSON.parseObject(JSON.parseArray(o.toString).get(0).toString)
//clomun name
val column = (database + "." + table) + "." + detail.getString("name")
//唯一id信息
val columnId = JSON.parseObject(detail.getString("exprId")).getString("id")
allTableInfo.put(columnId, column)
}
}
}
// println("allTableInfo:" + allTableInfo)
//相当于java的 break 因为我们只需要第一个Project的信息,只有第一个Project的中才包含血缘信息;
var loop = new Breaks;
loop.breakable {
for (c <- cmd) {
if (JSON.parseObject(c.toString).getString("class").contains("logical.Project")) {
val projectList = JSON.parseObject(c.toString).getJSONArray("projectList").toArray()
for (p <- projectList) {
val project = JSON.parseArray(p.toString)
val length = project.size()
//目标表和源头表字段名字不一样(roleId -> role_id)
if (length > 1) {
//获取目标表的字段名
val targetColumn = targetDatabaseTable + "." + JSON.parseObject(project.get(0).toString).get("name")
// println(targetColumn)
for (p <- project.toArray()) {
if (JSON.parseObject(p.toString).getString("class").contains("AttributeReference")) {
//获取与目标表字段对应的源头表字段的字段id,通过字段id获取源头表字段
val sourceColumn = allTableInfo.get(JSON.parseObject(JSON.parseObject(p.toString).getString("exprId")).getString("id"))
if (!allColumnRelation.containsKey(sourceColumn)) {
//放入字段关系map中
allColumnRelation.put(sourceColumn, targetColumn)
}
}
}
//目标表和源头表字段名字一样(role_id -> role_id)
} else {
val targetColumn = targetDatabaseTable + "." + JSON.parseObject(project.get(0).toString).get("name")
val sourceColumn = allTableInfo.get(JSON.parseObject(JSON.parseObject(project.get(0).toString).getString("exprId")).getString("id"))
allColumnRelation.put(sourceColumn, targetColumn)
}
}
loop.break()
}
}
}
// println("allColumnRelation:" + allColumnRelation)
// println("targetDatabaseTable:" + targetDatabaseTable)
// println("sourceDatabaseTables" + sourceDatabaseTables)
}
//下面就是 neo4j的语句拼接了 将血缘信息导入到图数据库
if(!targetDatabaseTable.equals("")) {
val session: Session = SparkListenerTest.driver.session
//创建目标表
if (session.run(s"match (t:Table {name:'${targetDatabaseTable}'}) return t").list().size() == 0) {
session.run(s"CREATE (n:Table {name:'${targetDatabaseTable}'}) RETURN n")
println(s"CREATE (n:Table {name:'${targetDatabaseTable}'}) RETURN n")
// println(s"CREATE (n:Table {name:'${TargetTable}'}) RETURN n")
}
//创建源头表并创建目标表表与源头表的关系
for(sourceDatabaseTable <- sourceDatabaseTables) {
if (session.run(s"match (t:Table {name:'${sourceDatabaseTable}'}) return t").list().size() == 0) {
session.run(s"CREATE (n:Table {name:'${sourceDatabaseTable}'}) RETURN n")
println(s"CREATE (n:Table {name:'${sourceDatabaseTable}'}) RETURN n")
}
session.run(s"MATCH (a:Table {name:'${sourceDatabaseTable}'}),(b:Table {name:'${targetDatabaseTable}'}) MERGE (a)-[:Derived]->(b)")
println(s"MATCH (a:Table {name:'${sourceDatabaseTable}'}),(b:Table {name:'${targetDatabaseTable}'}) MERGE (a)-[:Derived]->(b)")
}
//判断是否有目标表的列节点,如果没有则创建
for(targetColumn <- allColumnRelation.values()) {
if (session.run(s"match (c:Column {name:'${targetColumn}'}) return c").list().size() == 0) {
session.run(s"CREATE (n:Column {name:'${targetColumn}'}) RETURN n")
// println(s"CREATE (n:Column {name:'${TargetColumn}'}) RETURN n")
}
val targeTable = targetColumn.split("\\.")(0)+"."+targetColumn.split("\\.")(1)
session.run(s"MATCH (a:Column {name:'${targetColumn}'}),(b:Table {name:'${targeTable}'}) MERGE (a)-[:Belongs]->(b)")
println(s"MATCH (a:Column {name:'${targetColumn}'}),(b:Table {name:'${targeTable}'}) MERGE (a)-[:Belongs]->(b)")
}
//判断是否有源头表的列节点,如果没有则创建并创建列关系
for(sourceColumn <- allColumnRelation.keySet()) {
if (session.run(s"match (c:Column {name:'${sourceColumn}'}) return c").list().size() == 0) {
session.run(s"CREATE (n:Column {name:'${sourceColumn}'}) RETURN n")
// println(s"CREATE (n:Column {name:'${TargetColumn}'}) RETURN n")
}
val sourceTable = sourceColumn.split("\\.")(0)+"."+sourceColumn.split("\\.")(1)
session.run(s"MATCH (a:Column {name:'${sourceColumn}'}),(b:Table {name:'${sourceTable}'}) MERGE (a)-[:Belongs]->(b)")
println(s"MATCH (a:Column {name:'${sourceColumn}'}),(b:Table {name:'${sourceTable}'}) MERGE (a)-[:Belongs]->(b)")
session.run(s"MATCH (a:Column {name:'${sourceColumn}'}),(b:Column {name:'${allColumnRelation.get(sourceColumn)}'}) MERGE (a)-[:Derived_column]->(b)")
println(s"MATCH (a:Column {name:'${sourceColumn}'}),(b:Column {name:'${allColumnRelation.get(sourceColumn)}'}) MERGE (a)-[:Derived_column]->(b)")
}
}
}
}
//创建伴生类,可以理解为java的静态变量,同一个session只需要建立一次driver,不需要每个sql都建立一次
object SparkListenerTest{
val driver = GraphDatabase.driver(url, AuthTokens.basic(database, password))
}提交的时候要修改配置文件
spark-submit
--master xxx --deploy xxx
--executor-cores xxx --executor-memory xxx --num-executor xxx
--conf spark.sql.queryExecutionListeners="xxx.SparkListenerTest"
或者直接修改spark的conf文件 spark.sql.queryExecutionListeners= "xxx.SparkListenerTest"
导入neo4j后的效果 neo4j browser
