百度飞桨深度学习实践笔记(一):使用Python语言和Numpy库来构建神经网络模型
零基础入门深度学习
- 机器学习与深度学习综述
-
- 人工智能-机器学习-深度学习
- 深度学习的历史与现状
- 波士顿房价预测-Python与Numpy库构建神经网络模型的实践
-
- 处理数据
- 模型设计
-
- 前向传播算法
- 损失函数设置
- 梯度下降算法
-
- 梯度计算
- 梯度更新
- 随机梯度下降
- 模型训练
- 总结
机器学习与深度学习综述
人工智能-机器学习-深度学习
目前人工智能、机器学习、深度学习都是十分火热的话题,那么这三者之间是什么关系呢?

机器学习是实现人工智能的其中一个具体可行方法,而深度学习则是机器学习当中的神经网络方法,由于神经网络往往是多层,有深度,因此叫做深度学习。
深度学习的历史与现状

为何神经网络到2010年后才焕发生机呢?这与深度学习成功所依赖的先决条件:大数据涌现、硬件发展和算法优化有关。
深度学习改变了很多领域算法的实现模式。在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的“人工”理解沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)。而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务
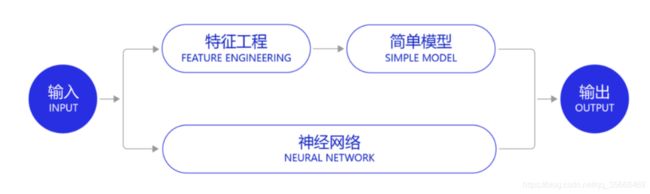
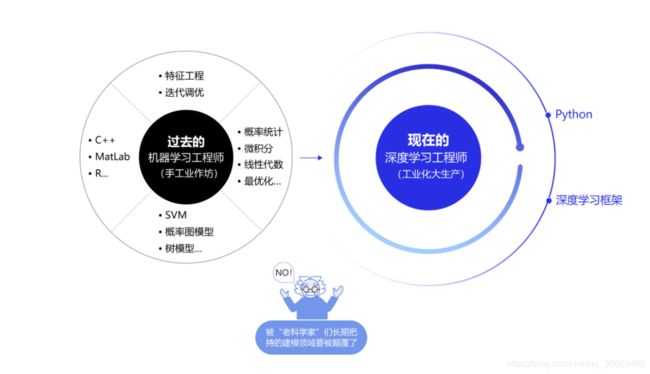
在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。而今,“深度学习工程师”进入了工业化大生产时代。只要掌握深度学习必要但少量的理论知识,掌握Python编程即可以在深度学习框架实现非常有效的模型,甚至与该领域最领先的模型不相上下。建模这个被“老科学家”们长期把持的建模领域面临着颠覆,也是新入行者的机遇。
波士顿房价预测-Python与Numpy库构建神经网络模型的实践
接下来以“房价预测”为例,演示使用Python实现神经网络模型的细节。【本文出现的代码在python3环境下即可跑通,数据集:house.data 可自行在网上搜索下载】
对于预测问题,根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
处理数据
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
# 数据导入
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
data
>>>array([6.320e-03, 1.800e+01, 2.310e+00, ..., 3.969e+02, 7.880e+00,1.190e+01])
#数据形状变换
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
#数据集划分
#将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
#数据归一化处理
## 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理,用训练集的最大值、最小值对测试集进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
前向传播算法
前向计算的过程是:输入含有13个特征的数据x,输出1个预测的房价y。
y = x ⋅ w + b y=x\cdot w+b y=x⋅w+b
x为每一条数据shape:[1,13]
则权值矩阵w的shape:[13,1]
b为偏置,是一个标量
计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数www和bbb。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
损失函数设置
用损失函数可以衡量实际房价y和通过模型输出预测房价z的差距,从而衡量模型的好坏,对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
L o s s = ( y − z ) 2 Loss=(y-z)^2 Loss=(y−z)2
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数N。
L o s s = 1 N ∑ i = 1 N ( y i − z i ) 2 Loss=\frac{1}{N} \sum_{i=1}^{N}(y_i-z_i)^2 Loss=N1i=1∑N(yi−zi)2
在Network类下面添加损失函数的计算过程如下:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)#对向量取均值操作
return cost
注:为什么选择均方误差而不选择绝对值误差?
答:因为均方误差损失函数曲线呈现出“圆滑”的坡度
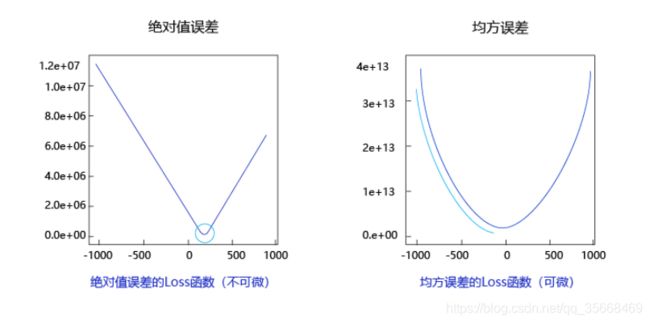
由此可见,均方误差表现的“圆滑”的坡度有两个好处:
1.曲线的最低点是可导的。
2.越接近最低点,曲线的坡度逐渐放缓,有助于通过当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而这两个特性绝对值误差是不具备的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
梯度下降算法
梯度计算
模型的训练的目的是使损失函数的值不断减小,而函数值下降最快的方向是沿着梯度的反方向。
将损失函数改写为梯度计算更方便的形式:
L o s s = 1 2 N ∑ i = 1 N ( y i − z i ) 2 Loss=\frac{1}{2N} \sum_{i=1}^{N}(y_i-z_i)^2 Loss=2N1i=1∑N(yi−zi)2
其中 z i z_i zi是网络对第i个样本的预测值

梯度的定义:
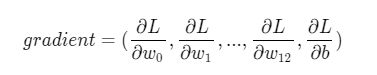
可以计算出L对w和b的偏导数:

基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用 ( z 1 − y 1 ) ∗ x 1 (z_1−y_1)∗x_1 (z1−y1)∗x1 ,得到的是一个13维的向量,每个分量分别代表该维度的梯度。下面代码计算样本1时w的梯度值:
gradient_w = (z1 - y1) * x1
print('gradient_w_by_sample1 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
'''
[output]
gradient_w_by_sample1 [ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363
-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.62581917
2.12068622], gradient.shape (13,)
'''
对于3个样本,可同时实现w梯度计算:
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)
gradient_w = (z3samples - y3samples) * x3samples
print('gradient_w {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
'''
[output]
gradient_w [[ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363
-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.62581917
2.12068622]
[ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277
-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.79236081
2.11028056]
[ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.93302947
0.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.46695229
2.39363651]], gradient.shape (3, 13)
'''
计算b的梯度的代码也是类似原理:
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
# 此处b是一个数值,所以可以直接用np.mean得到一个标量
gradient_b
'''
[output]
-1.0918438870293816e-13
'''
将上面计算w和b的梯度的过程,写成Network类的gradient函数,实现方法如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
梯度更新
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1
# 定义移动步长 eta
eta = 0.1
# 更新参数w5和w9
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
# 重新计算z和loss
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
将上面的循环计算过程封装在train和update函数中,对所有参数w和b求解,实现逻辑:“前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值”四个部分反复执行,直到到达参数最优点。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, graident_w5, gradient_w9, eta=0.01):
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
随机梯度下降
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗地说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
1.mini-batch:每次迭代时抽取出来的一批数据被称为一个mini-batch。
2.batch_size:一个mini-batch所包含的样本数目称为batch_size。
3.epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
第一层循环,代表样本集合要被训练遍历几次,称为“epoch”,代码如下:
for epoch_id in range(num_epoches):
第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”,代码如下:
for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数,这与大家之前所学是一致的,代码如下:
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x) #前向计算
loss = self.loss(a, y) #计算损失
gradient_w, gradient_b = self.gradient(x, y) #计算梯度
self.update(gradient_w, gradient_b, eta) #更新参数
将两部分改写的代码集成到Network类中的train函数中,最终的实现如下。
import numpy as np
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
#np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z-y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z-y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epoches, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epoches):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
模型训练
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
总结
本节我们详细介绍了如何使用Numpy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
1.构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
2.随机选择初始点,建立梯度的计算方法和参数更新方式。
3.从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。