Python库pandas对Excel文件的常用处理操作
常用小tip
1.如果存在文件则删除文件
import os
if (os.path.exists(path+filename)):
os.remove(path+filename)
2.复制文件
import shutil
shutil.copy(file_path_y, file_path_m)
3.json文件的读取与保存
import json
#读取json数据
with open(json_filepath) as file_obj:
names = json.load(file_obj)
#导出json数据
with open(json_filepath, 'w') as file_obj:
json.dump(names, file_obj)
4.写入Excel文件如何避免覆盖已有Sheet
4.1全新文件的写入方法
import pandas as pd
# 假定你已经有两个DF数据块:df1和df2
writer = pd.ExcelWriter('test_new.xlsx')
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
writer.save()
4.2已有文件增加Sheet的方法
import pandas as pd
# data = pd.DataFrame(columns=["class", "entity"])
data = pd.read_excel("song.xlsx", sheet_name = "Sheet1")
writer = pd.ExcelWriter("song.xlsx",mode = "a")
data.to_excel(writer , sheet_name = "Sheet5", index=False)
writer.save()
5.导入指定的列数据
data = pd.read_excel(r'D:/source.xlsx', usecols='A:D,H')
# 或者
data = pd.read_excel(r'D:/source.xlsx', usecols=[0,1,2,3,7])
6.预设pandas一次性显示行数
pd.options.display.max_rows = 100
7.全表范围替换指定数据
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
###替换shuju
res = data.replace(to_replace = 10,value = "new")
print(res)
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 new 11 12
# 3 13 14 15 16
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
8.打包为两两对应的列表套元祖数据(zip函数)
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
9.统计数据个数(Counter库)
from collections import Counter
a = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
res = Counter(a)
print(res)
print(dict(res))
# Counter({'l': 9, ';': 6, 'h': 6, 'f': 5, 'a': 4, 'j': 3, 'd': 3, 's': 2, 'k': 1, 'g': 1, 'b': 1})
# {'k': 1, 'j': 3, 'a': 4, 'l': 9, 'f': 5, ';': 6, 'd': 3, 's': 2, 'h': 6, 'g': 1, 'b': 1}
一,创建/读取/保存 Excel文件
- 创建空白excel(实质是创建空白的DataFrame,还没保存的情况下)
import pandas as pd
file = pd.DataFrame()
#构建有连个列标签的DataFrame数据
file1 = pd.DataFrame(columns=["class", "entity"])
print(file)
# Empty DataFrame
# Columns: []
# Index: []
- 读入excel文件
import pandas as pd
#读入excel数据转换为DataFrame数据,并指定读入的sheet
data_sum = pd.read_excel(filename, sheet_name = "Sheet1")
- 保存excel文件
data为要输出的DataFrame数据
writer = pd.ExcelWriter(path+filename)
#输出时可以指定输出的sheet
data.to_excel(writer, 'Sheet1', index=False)
writer.save()
writer.close()
二,sheet表单操作(pandas一次只能读取一个sheet)
1.行遍历数据(每个行都是Series类型)
import pandas as pd
data = pd.read_excel("song.xlsx", sheet_name = "Sheet1")
for index, row in data.iterrows():
print(index,list(row))
# 0 [1, 2, 3, '一', '二']
# 1 [2, 3, 4, '二', '三']
# 2 [3, 4, 5, '三', '四']
# 3 [4, 5, 6, '四', '五']
# 4 [5, 6, 7, '五', '六']
# 5 [6, 7, 8, '六', '日']
# 6 [7, 8, 9, '日', '一']
# 7 [8, 9, 10, '一', '二']
# 8 [9, 10, 11, '二', '三']
# 9 [10, 11, 12, '三', '四']
2.获取某些行/列数据
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
#获取某行数据
#方法一:标签获取
res1 = data.loc[1]
print(res1)
# sn 5
# Uplink 6
# Downlink 7
# file 8
# Name: 1, dtype: int64
#方法二:下标获取
res2 = data.iloc[1]
print(res2)
# sn 5
# Uplink 6
# Downlink 7
# file 8
# Name: 1, dtype: int64
#获取某列数据
#方法一:标签获取
res3 = data.loc[:,"Uplink"]
print(res3)
# 0 2
# 1 6
# 2 10
# 3 14
# Name: Uplink, dtype: int64
#方法二:下标获取
res4 = data.iloc[:,1]
print(res4)
# 0 2
# 1 6
# 2 10
# 3 14
# Name: Uplink, dtype: int64
3.删除某些行/列数据
- axis = 0 代表操作行
- axis = 1 代表操作列
- inplace 代表是否原地操作,如果设置为True那么就会对原表进行修改
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
###删除某行数据
res1 = data.drop(["Uplink"],axis = 1,inplace = False)
print(res1)
print(data)
# sn Downlink file
# 0 1 3 4
# 1 5 7 8
# 2 9 11 12
# 3 13 15 16
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
###删除某列数据
res2 = data.drop([1],axis = 0,inplace = False)
print(res2)
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 2 9 10 11 12
# 3 13 14 15 16
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
4.在特定行插入数据(直接对原表操作)
- ignore_index=True,表示不按原来的索引,从0开始自动递增
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
###1.向表末尾追加数据
#全量给值
data = data.append({"sn": "new","Uplink":"new","Downlink": "new","file":"new"},ignore_index=True)
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
# 4 new new new new
#给部分值
data = data.append({"sn": "new","Uplink":"new","Downlink": "new"},ignore_index=True)
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4.0
# 1 5 6 7 8.0
# 2 9 10 11 12.0
# 3 13 14 15 16.0
# 4 new new new NaN
#末尾插入行数据同时,设置自定义索引
new=pd.DataFrame({'sn':'lisa',
'Uplink':'F',
'Downlink':'北京',
'file':19},
index=[0])
data = data.append(new,ignore_index=False)
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
# 0 lisa F 北京 19
###2.向表指定行索引处插入数据(自定义)
def insert_row(origin_data,insert_data,index,):
import pandas as pd
#将数据按索引分成两份(水平)
t1 = origin_data.iloc[:index,:]
t2 = origin_data.iloc[index:,:]
#插入新数据到前段数据
t1 = t1.append(insert_data,ignore_index=True)
#将后段数据拼接到前端shuju
res = t1.append(t2,ignore_index=True)
return res
#需提前定好要插入的数据格式
insert_data = {"sn": "new","Uplink":"new","Downlink": "new"}
print(insert_row(data,insert_data,2))
# sn Uplink Downlink file
# 0 1 2 3 4.0
# 1 5 6 7 8.0
# 2 new new new NaN
# 3 9 10 11 12.0
# 4 13 14 15 16.0
5.在特定下标插入新列数据(直接对原表操作)
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
###特定下标插入列数据(可空)
#分别给定数据
insert_data = [0,0,0,0]
data.insert(1, 'd', insert_data)
print(data)
# sn d Uplink Downlink file
# 0 1 0 2 3 4
# 1 5 0 6 7 8
# 2 9 0 10 11 12
# 3 13 0 14 15 16
#统一设置值
insert_data = [0,0,0,0]
data.insert(1, 'd', None)
print(data)
# sn d Uplink Downlink file
# 0 1 None 2 3 4
# 1 5 None 6 7 8
# 2 9 None 10 11 12
# 3 13 None 14 15 16
6.对特定行列数据进行修改
import pandas as pd
data = pd.read_excel("ceshi.xlsx", sheet_name = "Sheet1")
# print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 11 12
# 3 13 14 15 16
# ###1.对指定行数据进行修改*************************************
index = 2
data.iloc[index:index+1,:] = ["new","new","new","new"]
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 new new new new
# 3 13 14 15 16
# ###2.对指定列数据进行修改**************************************
#指定列名
index = "Downlink"
data.loc[:,index] = ["new","new","new","new"]
print(data)
# sn Uplink Downlink file
# 0 1 2 new 4
# 1 5 6 new 8
# 2 9 10 new 12
# 3 13 14 new 16
#指定列下标索引
index = 3
data.iloc[:,index] = ["new","new","new","new"]
print(data)
# sn Uplink Downlink file
# 0 1 2 3 new
# 1 5 6 7 new
# 2 9 10 11 new
# 3 13 14 15 new
# ###3.对指定行列数据进行修改**********************************
index_x = 2
index_y = 2
data.iloc[index_x,index_y] = ["new"]
print(data)
# sn Uplink Downlink file
# 0 1 2 3 4
# 1 5 6 7 8
# 2 9 10 new 12
# 3 13 14 15 16
三,格式样式设置
1.使用XlsxWriter方法
- 使用pandas修改excel的样式,本质上整合了XlsxWriter模块,实现的excel样式修改
- pip install xlsxwriter
- 样式
header_format = workbook.add_format({undefined
'bold': True, # 字体加粗
'text_wrap': True, # 是否自动换行
'valign': 'bottom', # 垂直对齐方式
'align': 'center', # 水平对齐方式
'fg_color': '#D7E4BC', # 单元格背景颜色
'border': 1, # 边框
'top':2, # 上边框
'left':2, # 左边框
'right':2, # 右边框
'bottom':2, # 底边框
'num_format': 'yyyy-mm-dd',# 格式
})
或者
header_format .set_font_size(10)
header_format .set_bold()
header_format .set_bg_color('#101010')
header_format .set_font_color('#FEFEFE')
header_format .set_align('center')
header_format .set_align('vcenter')
header_format .set_bottom(2)
header_format .set_top(2)
header_format .set_left(2)
header_format .set_right(2)
1.1 使用方法
workbook.add_format({}) # 为表格添加样式,参数为一个字典,字典内容{'bold': True, 'align': 'center' }
worksheet.set_column("A:A", 15, header_format) # 设置A列的宽度为15,使用header_format样式(header_format样式 <====> header_format = workbook.add_format({}) ),当然你也可以设置A列到D列"A:D"
worksheet.set_default_row(90) # 默认设置所有行高的高度
worksheet.set_row(0,15,header_format) # 设置指定行
worksheet.merge_range('B4:D4', 'Merged Range', merge_format) # 合并单元格方法,合并B列到D列的第四行
# 或者
worksheet.merge_range('B4:D5', 'Merged Range', merge_format) # 合并B列到D列的第四行到五行
1.2 案例演示一
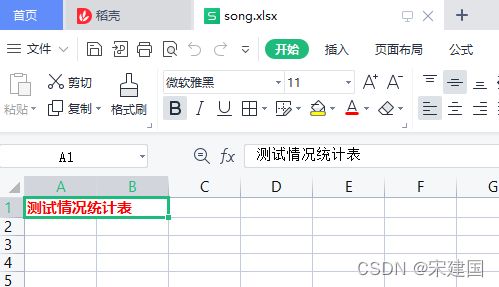
import pandas as pd
data = pd.read_excel("song.xlsx", sheet_name = "Sheet1")
writer = pd.ExcelWriter("song.xlsx", engine="xlsxwriter")
data.to_excel(writer, 'Sheet1', index=False)
note_fmt = writer.book.add_format({'bold': True, 'font_name': u'微软雅黑', 'font_color': 'red', 'align': 'left', 'valign': 'vcenter'})
writer.sheets['Sheet1'].merge_range('A1:B1', u'测试情况统计表', note_fmt)
#输出时可以指定输出的sheet
writer.save()
writer.close()
1.3 案例演示二
import pandas as pd
import numpy as np
data = np.arange(1,17).reshape(4,4)
# list转dataframe
df = pd.DataFrame(data, columns=['sn', 'Uplink','Downlink','file'])
writer = pd.ExcelWriter("ceshi.xlsx", engine='xlsxwriter')
# 保存到本地excel
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
header_format = workbook.add_format({
'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
})
header_format1 = workbook.add_format({
'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
'text_wrap': True
})
worksheet.set_column("A:A", 15, header_format)
worksheet.set_column("B:C", 60,header_format1)
worksheet.set_column("D:D", 45,header_format)
worksheet.set_default_row(90)# 设置所有行高
worksheet.set_row(0,15,header_format)#设置指定行
writer.save()
writer.close()
2.使用openpyxl方法
- 暂时用不到,用到再整理吧
- 先给个参考直通车
直通车1
直通车2