【机器学习】朴素贝叶斯算法(Naive Bayes,NB)

作者:田志晨
来源:小田学Python
贝叶斯分类算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Naïve Bayes,NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。
01
贝叶斯
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
首先讲一下概率论中的知识,引用宇哥的一个经典例子。
现在,有三个小偷,小张、小政、小英,分别记为A1、A2、A3,去一个村子偷东西。分为两个阶段:
(一)选人:小张、小政、小英
(二)去偷:村子失窃,记为B
全概率公式
三个小偷都有可能去该村子偷东西,那么这个村子失窃的可能性就要考虑这三个小偷去偷东西的总概率。
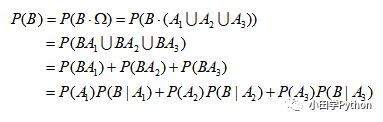
解释一下上述推导过程,P(B|A) 表示在 A 的情况下 B 发生的概率。结合题意理解为,任意一个小偷去偷,偷窃成功的情况;P(A) 表示其中一个小偷准备去这个村子行窃的概率。下面总结出一个通用的公式:
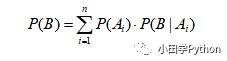
贝叶斯公式
有了全概率公式,现在可以看看贝叶斯公式了。
贝叶斯公式是在 B 已经发生的情况下,执果索因。也就是本例中,已经得知该村子失窃,现在要判断是谁行窃的可能性最大。可以表示为:
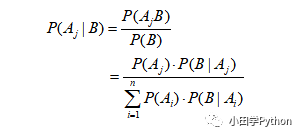
这样,我们就把已知每个人作案成功的概率转化为已知失窃,判别是谁作案的问题。这样的问题是很常见的,先验概率一般是已知的,通过它来求得后验概率。上面的公式也许有人看不太明白,这里写一个简单的贝叶斯公式:
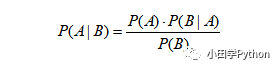
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
后验概率 = 先验概率 x 调整因子
02
朴素贝叶斯
朴素贝叶斯是贝叶斯分类算法中的一种,是对贝叶斯的一个改进。朴素贝叶斯与贝叶斯显著的不同之处在于,朴素贝叶斯进行了独立性假设,假设各个特征之间相互独立不相关。
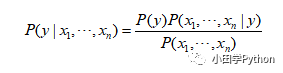
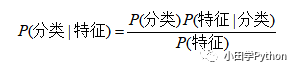
下面说一下为什么需要朴素贝叶斯,引用一个例子来解释一下。现在有一个女生,她的择偶标准做了以下说明:
| 帅? |
性格好? |
身高? |
上进? | 嫁与否? |
| 帅 |
不好 |
矮 |
不上进 |
不嫁 |
| 不帅 |
好 | 矮 | 上进 |
不嫁 |
| 帅 |
好 | 矮 | 上进 | 嫁 |
| 不帅 |
好 | 高 | 上进 | 嫁 |
| 帅 |
不好 |
矮 | 上进 | 不嫁 |
| 不帅 |
不好 | 矮 | 不上进 | 不嫁 |
| 帅 |
好 | 高 | 不上进 | 嫁 |
| 不帅 |
好 | 高 | 上进 | 嫁 |
| 帅 |
好 | 高 | 上进 | 嫁 |
| 不帅 |
不好 |
高 |
上进 | 嫁 |
| 帅 |
好 | 矮 | 不上进 |
不嫁 |
| 帅 |
好 | 矮 | 不上进 | 不嫁 |
现在有一对情侣,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
首先,既然有了标准,那么对照着表格找一下好了,然而不巧的是,表中没有该男生的形象,四个特征的各种组合有很多种,目前只得到12组数据,那其他情况的概率即为0,根据贝叶斯公式可以计算得,该女生不可能嫁给他。

显然这样无法计算了,而且,当特征较多时,其组合形式会特别多。因此,出现了朴素贝叶斯,对特征值进行独立性假设。这样每个特征值对结果的影响互不相关,则有下面两个等价公式。
P(不帅、性格不好、矮、不上进)=P(嫁)P(不帅|嫁)P(性格不好|嫁)P(矮|嫁)P(不上进|嫁)+P(不嫁)P(不帅|不嫁)P(性格不好|不嫁)P(矮|不嫁)P(不上进|不嫁)
P(不帅、性格不好、矮、不上进|嫁)=P(不帅|嫁)P(性格不好|嫁)P(矮|嫁)P(不上进|嫁)
这两个公式中现有的概率均可以通过上面的表格计算得到。例如P(不帅|嫁)可以找到表格中所有“嫁”的一栏中“不帅”占多少比重,表格显示嫁有六种情况,在这六种情况中,不帅的有三个,因此 P(不帅|嫁)=3/6=0.5。其他数据同理,带入即可计算出嫁与不嫁的概率。
03
朴素贝叶斯代码实现
这部分使用的sklearn自带的数据集——鸢尾花。数据包含三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm)。
# 导入数据集
import sklearn.datasets as datasets
iris = datasets.load_iris()
X = iris['data']
y = iris['target']利用sklearn中的方法,将数据划分为数据集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)查看一下该数据集中的一些特征值。
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(X[:,0], bins=20)
plt.hist(X[:,1], bins=20)
plt.hist(X[:,2], bins=20)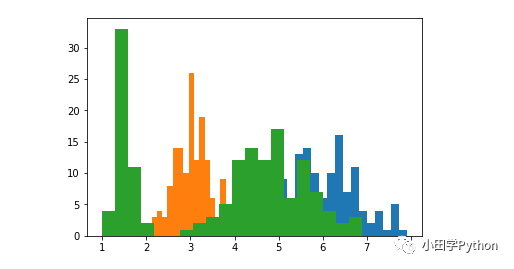
可以从上图看到,鸢尾花的特征值整体服从正态分布。下面就看一下利用贝叶斯来分类的效果。
1 高斯分布朴素贝叶斯(Gaussian Naive Bayes)
数据分布满足高斯分布(正态分布)
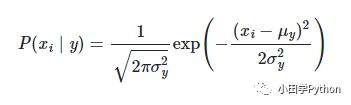
# 导入包,后续进行训练、测试,输出分类正确率
from sklearn.naive_bayes import GaussianNB
gNB = GaussianNB()
gNB.fit(X_train, y_train) # 训练模型
gNB.score(X_test, y_test) # 测试
[out] 0.962 多项式分布朴素贝叶斯(Multinomial Naive Bayes)
MultinomialNB实现了用于多项分布数据的朴素贝叶斯算法,并且是文本分类中使用的两个经典朴素贝叶斯变体之一。
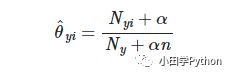
from sklearn.naive_bayes import MultinomialNB
mNB = MultinomialNB()
mNB.fit(X_train, y_train) # 训练模型
mNB.score(X_test, y_test) # 测试
[out] 0.94666666666666673 伯努利分布朴素贝叶斯(Bernoulli Naive Bayes)
BernoulliNB对根据多元Bernoulli分布分布的数据实施朴素的贝叶斯训练和分类算法; 也就是说,可能有多个特征,但每个特征都假定为一个二进制值(伯努利,布尔值)变量。 因此,此类要求将样本表示为二进制值特征向量。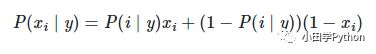
from sklearn.naive_bayes import BernoulliNB
bNB = BernoulliNB()
bNB.fit(X_train, y_train) # 训练模型
bNB.score(X_test, y_test) # 测试
[out] 0.3204
手写数字实战演练
手写数字的内容【机器学习】K-近邻算法(KNN)(点击直接跳转哦)中已经提到了,为了做个对比以及加深印象,用贝叶斯计算一下。
import pandas as pd
# 训练集
data = pd.read_csv('mnist_dataset/mnist_train.csv', header=None)
X_train = data.iloc[:,1:]
y_train = data[0]
# 测试集
test_data = pd.read_csv('mnist_dataset/mnist_test.csv', header=None)
X_test = test_data.iloc[:,1:]
y_test = test_data[0]上面是获取数据集,接下来利用贝叶斯进行分类并测试准确性。下面是利用多项式分布朴素贝叶斯计算得结果。准确率0.8365,耗时 Wall time: 669 ms 。其他形式以图片形式展示,可以自己尝试一下。
%%time
from sklearn.naive_bayes import MultinomialNB
mNB = MultinomialNB()
mNB.fit(X_train, y_train)
mNB.score(X_test, y_test)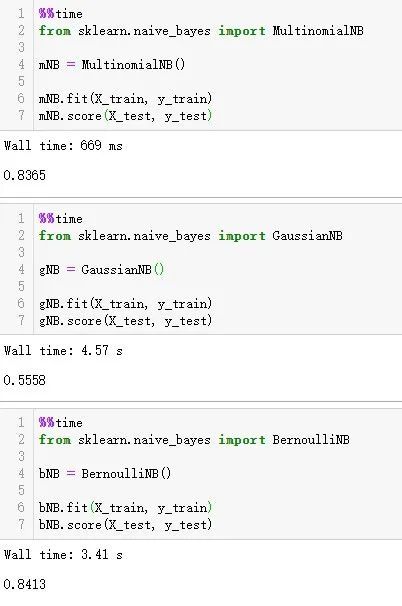
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 笑死人不偿命的知乎沙雕问题排行榜● 用Python扒出B站那些“惊为天人”的阿婆主!● 全球股市跳水大战,谁最坑爹!● 上万条数据撕开微博热搜的真相!● 你相信逛B站也能学编程吗?