新闻文本分类(课程设计)
目 录
一 课程设计的目的 3
二 课程设计的内容和要求 3
三 详细设计 3
- 算法介绍 3
- 实验及分析 3
2.1数据集介绍 3
2.2数据预处理 4
2.3 模型介绍 6
2.4 模型评估 8 - 结论 8
四 课程设计总结 9
一 课程设计的目的
在大数据时代,网络上的文本数据日益增长。采用文本分类技术对海量数据进行科学地组织和管理显得尤为重要。文本作为分布最广、数据量最大的信息载体,如何对这些数据进行有效地组织和管理是亟待解决的难题。文本分类是自然语言处理任务中的一项基础性工作,其目的是对文本资源进行整理和归类,同时其也是解决文本信息过载问题的关键环节。文本分类按照任务类型的不同可划分为问题分类、主题分类以及情感分类,常用于数字化图书馆、舆情分析、新闻推荐、邮件过滤等领域,为文本资源的查询、检索提供了有力支撑,是当前的主要研究热点之一。
二 课程设计的内容和要求
本次课程设计我们主要研究新闻文本分类,新闻文本分类技术是从预定义的新闻类目集合中,通过有监督分类模型,从源文本中提取出代表该文本的相关特征,最终自动将其划分到该主题标签下,达到新闻有序归类的目的。
三 详细设计
先收集数据集对其进行jieba分词并去除停用词以达到数据预处理的目的,再将其数据进行划分成训练集和测试集,使用词袋模型和TF-IDF两种模型对文本提取特征,并使用分类器进行分类,并计算最后的准确率。在分类器的选择上,我们选择了朴素贝叶斯算法,基于贝叶斯定理与特征条件独立性假设的分类方法,使用多项式模型来进行训练。
1 算法介绍
贝叶斯分类算法是一类分类算法的总和,均以贝叶斯定理为基础,故称之为贝叶斯分类。朴素贝叶斯分类算法就是其中最简单的分类算法,朴素贝叶斯分类算法很简单,就一个公式如下所示:
P(B|A) =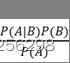
朴素贝叶斯的做法是将一个由[w1,w2,w3…wn]这样一个特征向量转换为分离的特征。
朴素贝叶斯常用的三个模型有:
高斯模型:处理特征是连续型变量的情况;
多项式模型:最常见,要求特征是离散数据;
伯努利模型:要求特征是离散的且为布尔类型,即true和false,或者1和0;
用朴素贝叶斯原理,处理一个分类问题,一般要经过以下几个步骤:
1、准备阶段:
获取数据集。分析数据,确定特征属性,并得到训练样本。
2、训练阶段:
计算每个类别概率P(B)。对每个特征属性,计算每个分类的条件概率P(A|B)。
B 代表所有的类别。
A 代表所有的特征。
3、预测阶段:
给定一个数据,计算该数据所属每个分类的概率P(A|B) * P(B)。最终哪个分类的概率大,数据就属于哪个分类。
2 实验及分析
2.1 数据集介绍
该数据集一共有5000条新闻数据,数据表示为四列,分别为:‘label’‘theme’‘URL’‘content’其中content包含有‘汽车’‘财经’‘科技’‘健康’‘体育’‘教育’‘文化’‘军事’‘娱乐’‘时尚’10类。
2.2 数据预处理
数据预处理是个很重要的过程,我们使用的是中文数据集,中文语料的特点是词与词之间是紧密相连的,这一点不同于英文,因此在分词的时候不能像英文使用空格分词,需要使用特殊的分词方法。
1、数据读取
import numpy as np
import pandas as pd
import jieba
newdata = pd.read_table("data.txt",names=['label','theme','URL','content'],encoding='utf-8')
# 查看数据维度
print(newdata.shape)
# 提取我们要用到的数据
content = newdata['content'].values.tolist()
print(content)
图 1 数据读取
它的运行结果为:
(5000,4)
图 2 运行结果
2、jieba分词
我们使用的是jieba库进行分词。目前常用的分词工具很多,包括盘古分词、Yaha分词、Jieba分词、清华THULAC等,jieba分词精确模式将句子最精确地切开,适合文本分析用jieba.lcut()函数,以精确模式分词,这样的好处在于不存在冗余词语。jieba.lcut() 直接返回分词后的列表。
# jieba分词,中文文本分词,连续的字序列就变成以词为单位的向量
content_S = []
for text in content:
cut_content = jieba.lcut(text)
if len(cut_content)>1 and cut_content != '\r\n':
content_S.append(cut_conte
图 3 jieba分词
3、删除停用词
删除那些没有价值的内容(停用词),引用了“哈工大停用词表”。
# 删除停用词
stopwords = pd.read_csv("哈工大停用词表.txt",sep='t',quoting=3,names=['stopwords'],encoding='utf-8')
def drop_stopwords(contents,stopwords):
content_clearn = []
for line in contents:
line_clearn = []
for word in line:
if word in stopwords:
continue
line_clearn.append(word)
content_clearn.append(line_clearn)
return content_clearn
stopwords = stopwords.stopwords.values.tolist()
content_clearn = drop_stopwords(content_S,stopwords)
df_content = pd.DataFrame({'content_clearn':content_clearn})
# 查看前五行
print(df_content.head())
图 4 删除停用词
4、划分训练集和测试集
先将清洗好的数据转换为pandas支持的DataFrame格式,DataFrame是一个表格型的树结构,含有一组有序的列,每列可以是不同的值,既有行索引也有列索引,它可以被看做由 Series 组成的字典,共同用一个索引。
new_train = pd.DataFrame({'content_clearn':content_clearn,'label':newdata['label']})
print(new_trai.tail())
图 5 转化为DateFrame
它的输出结果为:

图 6 运行结果
查看数据集的标签类别,为了方便查询,利用map函数构建一个映射方法,将label中的每一个元素赋予数值,将new_train中所有的标签进行一一映射,最后将映射后的每个值返回合并,得到一个新的new_train。
print(new_train.label.unique())#查看数据集一共多少标签
print('-----------------------------------------------------------------------------')
label_mapping = {'汽车':1, '财经':2, '科技':3, '健康':4, '体育':5, '教育':6, '文化':7, '军事':8, '娱乐':9, '时尚':0}
new_train['label'] = new_train['label'].map(label_mapping)#构建一个映射方法
print(new_trai.tail())
图7 映射
输出结果如下:
图8 运行结果
利用sklearn.model_selection 模块调用train_test_split 函数 划分训练集和测试集,new_train[‘content_clearn’].values划分样本的特征集,new_train[‘label’].values划分样本的结果,test_size就是训练集样本的占比,random_state=0就是随机数。
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(new_train['content_clearn'].values,new_train['label'].values,random_state=1)
图9 划分训练集和测试集
2.3 模型介绍
1、词袋特征模型
将所有的数据集集中在一起,构建出一个词表words空表,存放所有的数据,每一个词汇对应其出现的顺序,构建出的词向量的每一维都代表这一维对应单词出现的频次,这些词向量组成的矩阵称为频次矩阵。通过CountVectorizer函数提取文本特征,将该文本特征去拟合words词袋,得到词频矩阵,最后利用多项式朴素贝叶斯拟合词频矩阵和训练集标签,并输出预测结果以及的得分。
# 利用词袋模型进行训练
# 首先将训练集中的所有词都存在一起
words = []
for line_index in range(len(x_train)):
try:
words.append(" ".join(x_train[line_index]))
except:
print(line_index)
# 查看有多少个词print(len(words)) 一共有3750个词
# 制作词袋特征模型
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', max_features=max_features=len(words),lowercase=False)
feature = vec.fit_transform(words)
print(feature)
图10 词袋模型
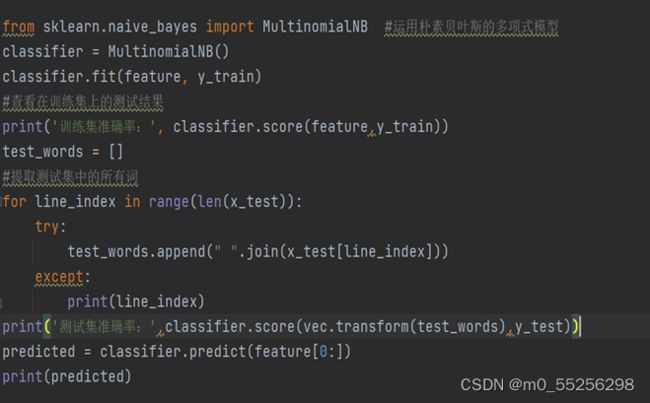
图11 导入朴素贝叶斯模型
输出结果如下:
图12 预测标签
2、TF-IDF训练
与词袋特征模型相似,只不过是利用TfidfVectorizer函数去得到文本特征
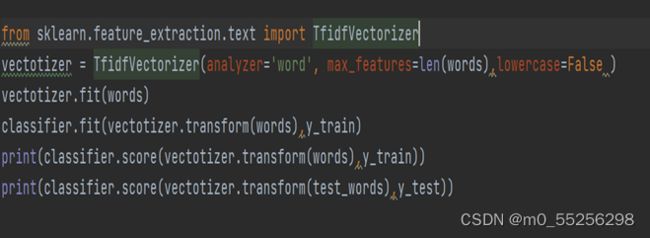
图13 TF-IDF模型
2.4 模型评估

图14 模型准确率
通过预测准确率对比得出TF-IDF模型准确率更高。词袋只创建一组向量,包含文档中的文本出现次数,而TF-IDF模型还包含关于更重要的文本和不重要的文本的信息。虽然词袋向量很容易解释。但是在机器学习模型中,TF-IDF通常表现得更好。
3 结论
机器学习方法万千,具体选择用什么样的方法还是要取决于数据集的规模以及问题本身的复杂度,对于复杂程度一般的问题,看似简单的方法有可能是最好的。
这次课程设计通过运行代码有助于对海量数据的科学地组织和管理。而文本分类是自然语言处理任务中的一项基础性工作,可以对文本资源进行整理和归类,同时其也是解决文本信息过载问题的关键环节。也有利于舆情监测应用和新闻分类。
图15.1-图15.3是本次课设的最终结果
图15.1
图15.2
图15.3
四 课程设计总结
通过本次机器学习的课程设计,我们首先了解到了一些课本上没有的知识,比如词袋模型和TF-IDF模型,也巩固并加深理解了朴素贝叶斯算法的原理以及相关知识,在编写算法的开始,我们对自己选的课设题目模模糊糊,不知道从何下手,于是我们通过查阅网上相关资料,首先对自己的课设题目有了一个大概的了解,知道应该运用什么样的算法来实现,知道大致的步骤,然后在组长的带领下,我们分工合作,互相配合,遇到问题时,及时向老师请教解决问题,也会向其他小组请教一些不懂的知识,只为设计出较完美的课设,就这样,我们一步一步分析代码,一次又一次地解决自己遇到的问题,在两周时间之内,我们完成了自己的课设。
在这次课设中,我们遇到了许多问题,比如如何找到合适的数据集,我们查找了许多相关资料,尝试了许多,最终找到了合适的新闻文本数据集;如何读取数据集,首先在课本上阅读了相关知识,又结合课外知识不断调试代码,最终解决了它;以及如何进行数据预处理,先用jieba分词,分词后还存在许多不重要的词,比如语气词,人称代词等对预测结果并不重要,因此根据停用词表去除它。
这次课设让我们感受到了团队合作的重要性,分工合作也让我们效率大大增加,但感触最深的还是学习到了课本之外的知识——词袋模型,从第一次见到它的陌生到现在的有一些了解,知道它的大概原理,在分析它的代码时,并不像上课理解老师讲解的那么容易,我们有很多代码步骤不懂,总是会遇到卡壳的地方,甚至有时没有头绪,只能一次次去网上查阅,甚至在第一次请教老师的时候,面对老师的提问,还是有一些一问三不知,不能清晰地说出自己的理解,但是我们并没有放弃,我们通过查询各种课外资料,编写各种代码去调试,将问题慢慢的被解决,看着最后的成果,我们的内心有了一种成就感,这让我们对机器学习有了更大的兴趣。
有了这次的课程经验,我们懂得只有把所学的理论知识与实践相结合起来,从理论中得出结论,才是正确的理论,从而才能提高自己实际动手能力和独立思考的能力。在课程设计的过程中,可以说得是困难重重,这毕竟是第一次接触机器学习的课程设计,它的代码语言并不像之前所学的那么通透,所以我们难免会遇到过各种各样的问题,但同时在设计的过程中我们也发现了自己的不足之处,对课本上的知识理解得还不够深刻,掌握得不够牢固,我们决心一定把以前所学过的知识重新温故,并在以后的学习中加以改正,努力练习,提高自己的动手能力。