(七) 深度学习笔记 |pytorch官方demo(LeNet-5)下
一、前言
- 此前我们对LeNet进行讲解https://blog.csdn.net/weixin_45579930/article/details/112277024
- 并对我们接下来要使用的model.py进行讲解https://blog.csdn.net/weixin_45579930/article/details/112323167
- 下面有需要用到的代码我已经将其放入我的githubhttps://github.com/Viviana-0/Deeplearning
- 以上内容有需要的可以自行食用
二、pytorch官方demo实现一个分类器(LeNet)
2.1.实现demo的流程
- model.py ——定义LeNet网络模型
- rain.py ——加载数据集并训练,训练集计算loss,测试集计算accuracy,保存训练好的网络参数
- predict.py——得到训练好的网络参数后,用自己找的图像进行分类测试
三、关于model.py
# 使用torch.nn包来构建神经网络.
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # super函数继承父类的构造函数,就是调用基类的构造函数
self.conv1 = nn.Conv2d(3, 16, 5) # 第一个参数代表输入特征矩阵的深度,16个卷积核,大小是5*5
self.pool1 = nn.MaxPool2d(2, 2) # 采用池化核大小2*2,步长stride=2
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 正向传播过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
四、关于train.py
- 首先我们先导入所需要的包
import torch
import torchvision
import torch.nn as nn
from deeplearning.model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
4.1数据集的介绍
此处我们可以利用torchvision.datasets函数可以在线导入pytorch中的数据集,包含一些常见的数据集如MNIST等
我们使用的是CIFAR10数据集,也是一个很经典的图像分类数据集,由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集,一共包含 10 个类别的 RGB 彩色图片。
可以通过pytorch官网进行查看:https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html#sphx-glr-beginner-blitz-cifar10-tutorial-py
- 1.我们首先下载我们需要用到的数据集
def main():
# 使用transform将我们需要使用的函数打包进行预处理
# 在这里我们使用到了两个预处理方法
# 1.ToTensor
# 2.Normalize
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集,train=True会导入CIFAR10的训练集样本
download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
batch_size=36, # 每批训练的样本数。我们将刚刚的训练集导入进来,把它分成一个批次批次。batch_size每一批随机拿出36张图片进行训练
shuffle=true, # 是否打乱训练集,shuffle=true是将其进行打乱
num_workers=0) # 使用线程数,在windows下设置为0
- 2.下载完成后,会生成CIFAR10对应的数据集
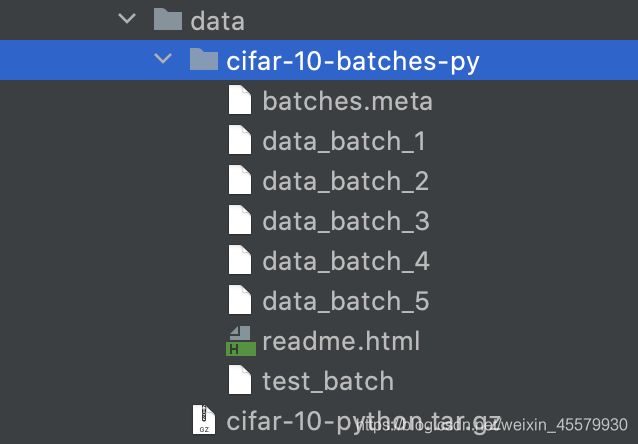
4.1.1查看ToTensor义释
- 我们对上方使用到的ToTensor进行查看它的义释
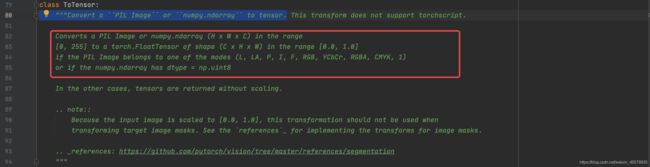
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.-
1.将PIL图像或numpy数据转换为tensor
-
2.从如上图,可以看到我们导入的原始图像不管是通过PIL或者是numpy进行导入一般显示的数据图像是是(H x W x C)的排列顺序,每一个纬度的像素值都是[0,255]
-
3.我们通过tensor函数之后将(H x W x C)变为(C x H x W),并且像素值变为[0,1]直接
-
4.1.2查看Normalize义释
-
我们对上方使用到的Normalize进行查看它的义释
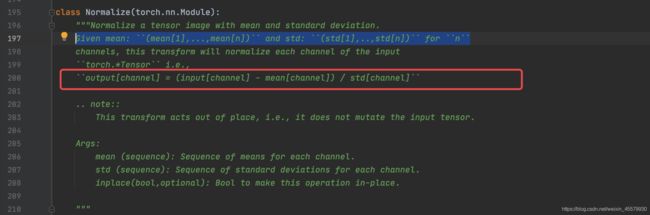
Normalize a tensor image with mean and standard deviation- 使用均值或标准差来标准化我们的tensor
- 提供的参数有均值和标准差
- 计算是:output[channel] = (input[channel] - mean[channel]) / std[channel]
4.2进行训练
我们可以观察到我们在model.py最后一层并没有使用softmax函数
4.2.1查看CrossEntropyLoss义释
- 我们对下方使用到的Normalize进行查看它的义释
This criterion combines :func:nn.LogSoftmax and :func:nn.NLLLoss in one single class.- 准则包含nn.logsoftmax和nn.NLLLoss这两个函数,所以我们就不需要在网络的输出加上softmax函数
net = LeNet() # 定义训练的网络模型
loss_function = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
# 传入的第一个参数就是我们所需要训练的参数,net就是我们定义的 LeNet()
# parameters()表示我们将LeNet()可训练的参数都进行训练
# lr表示学习率
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器Adam(训练参数,学习率)
4.2.2关于 optimizer.zero_grad()清除历史梯度
在这里我们可能会思考为什么我们需要对历史梯度进行清除,原因是因为:如果我们不将历史梯度进行清除,就会对计算的历史梯度进行累加(通过这个特性你能够变相实现一个很大batch数值的训练)
我们设置batch_size是根据我们硬件设备进行设置的,一般设置越大一般训练效果会越好。但是一般由于我们的硬件设备受限,比如内存不足,我们不可能使用很大的batch进行训练,所以我们可以一次性计算小的batch。
# 将我们的训练集迭代多少轮 5进行迭代五次
for epoch in range(5): # 一个epoch即对整个训练集进行一次训练
# 用来累加训练过程中的损失
running_loss = 0.0
# 遍历训练集,step从0开始计算
for step, data in enumerate(train_loader, start=0):
inputs, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
# forward + backward + optimize
outputs = net(inputs) # 正向传播
loss = loss_function(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印耗时、损失、准确率等数据
running_loss += loss.item()
4.2.3关于torch.no_grad()
- torch.no_grad()的作用就是在接下来的计算中不要去计算每个节点的误差损失梯度
- 如果不用这个函数的话,即使是在测试过程中也会去计算他的损失误差梯度,这样的话有两个缺点:
- 1.占用更多的算力,消耗更多的资源
- 2.由于要存储每个节点的损失梯度会占用更多的内存
- 使用这个函数 在他范围内都不会去计算他的误差梯度了
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad(): # 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
outputs = net(val_image) # 测试集传入网络 running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
# 寻找输出最大的index,网络预测最可能在哪个类别的
# torch.max对应网络的输出
# 得到预测的最大值predict_y
# dim=1对应的是在纬度1中,寻找最大值[1]代笔只需要index=1
predict_y = torch.max(outputs, dim=1)[1]
# 将预测的标签列别与真实的标签列别进行比较 在相同的地方返回true=1,不相同的地方返回false=0
# 进行求和函数,预测对了的多少个样本
# 需要通过item()获取他的数值/测试样本的数目得到准确率
accuracy = (predict_y == val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
# epoch代表迭代到第几轮
# step某一轮的多少步
# 训练过程中累加的误差/500 500步中平均的误差
# 准确率
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
4.3完整代码
我们可以使用完整代码进行训练:
我们可以看到我们迭代了5个epoch之后,达到了最终的准确率是0.758,由于这个模型是在1998年提出的,所以准确率可能没有那么高。
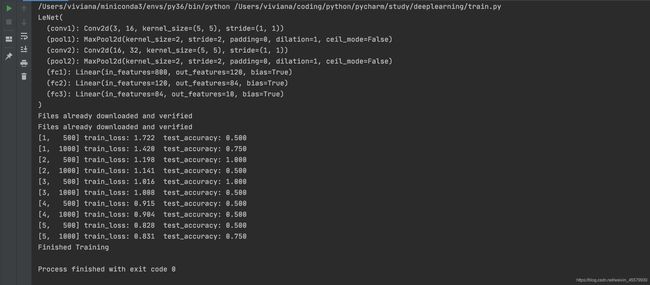
并且在我们目录下自动生成了模型权重文件
![]()
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
五、关于predict.py
下图是我们所需要用到的1.py

# 导入包
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
# 数据预处理
transform = transforms.Compose(
# 进行缩放成一个32*32的大小
[transforms.Resize((32, 32)), # 首先需resize成跟训练集图像一样的大小
# 在将它转换为tensor
transforms.ToTensor(),
# 接着我们对他进行一个标准化处理
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入要测试的图像(自己找的,不在数据集中),放在源文件目录下
im = Image.open('horse.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # 对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
# 实例化网络,加载训练好的模型参数
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
# 预测
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 通过这个函数载入我们的权重文件
net.load_state_dict(torch.load('Lenet.pth'))
# 载入我们的图像
im = Image.open('1.jpg')
# 放入网络进行正向传播
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].data.numpy()
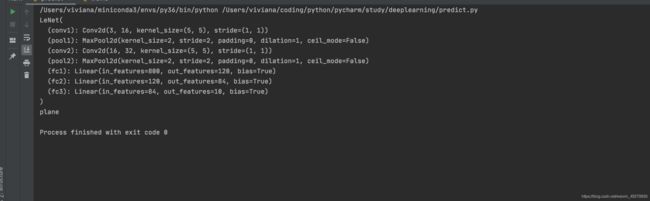
print(classes[int(predict)])
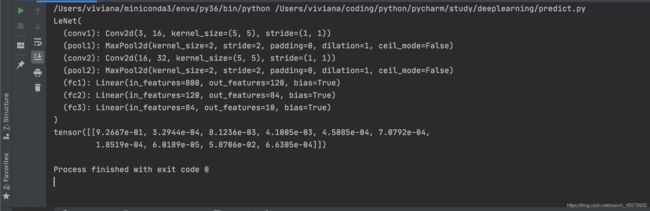
通过输出结果是plane,说明预测结果是正确的
5.1使用softmax进行预测
预测结果也可以使用softmax进行预测表示,则会输出10个概率
with torch.no_grad():
outputs = net(im)
predict = torch.softmax(outputs, dim=1)
print(predict)
输出结果中最大概率只对应的索引即为预测标签的索引:
tensor([[9.2667e-01, 3.2944e-04, 8.1236e-03, 4.1005e-03, 4.5085e-04, 7.0792e-04,
1.8519e-04, 6.0189e-05, 5.8706e-02, 6.6305e-04]])