Pytorch纯新手入门笔记
Pytorch入门笔记(推荐配合B站up主我是土堆食用)
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
视频作者:我是土堆
Pytorch入门
P1
命令行中对anaconda不同环境的控制
进入命令行
win+r,在弹出的窗口中输入cmd,即可进入命令行
在命令行下为anaconda创建新环境
conda create -n 环境名 python=版本号 # 如果没有创建成功,有可能是网络的问题,关了VPN再试试
例:conda create -n pytorch python=3.6,即在anaconda中创建了python为3.6的pytorch环境。
在命令行下查看anaconda有哪些环境
conda info --envs
在命令行下进入anaconda的某个环境
conda activate 环境名 # 如果提示“IMPORTANT: You may need to close and restart your shell after running 'conda init'”,就在命令行中执行conda init,重开命令行再执行conda activate 环境名,即可进入anaconda的某个环境。
例:conda avtivate pytroch,即在命令行中切换到pytorch的环境。
在命令行下查看环境中有哪些包
pip list
pytorch安装教程
- 进入命令行
- 在命令行下进入anaconda的某个环境中
- 进入官网:PyTorch
- 按照下图选择合适的命令并其复制到命令行中执行,执行不成功,看第五步,否则看第六步

- 如果上述命令因为网速等原因执行不成功,在命令行中输入以下命令
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install 包名 -i 国内pip源
#常见国内pip源有:
#清华:https://pypi.tuna.tsinghua.edu.cn/simple
#阿里云:http://mirrors.aliyun.com/pypi/simple/
#中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
#华中理工大学:http://pypi.hustunique.com/
#山东理工大学:http://pypi.sdutlinux.org/
#豆瓣:http://pypi.douban.com/simple/
-
进入pycharm,在file-settings-project:项目名-Python Interpreter中添加pytorch环境

-
进入pycharm的Python Console中,输入
import torch,验证pytorch是否安装成功。
P2
Pycharm使用指南
-
Python Console中可以单命令行执行,

-
jupyter notebook可以实时交互
要改变jupyter的启动位置有两种方式,一种是进入命令行,在命令行中切换到启动位置路径,再输入
jupyter notebook,即可启动;另一种是修改jupyter notebook配置文件中的默认启动地址,推荐前一种,用起来比较方便,不用频繁修改配置文件。
P4
可以在 jupyter notebook 或者 pycharm的 python console中运行下面的命令,查看安装包的具体情况。
-
dir():打开,看见包的情况
如果dir打开的是某个函数,不能加()。
比如:这个是对的:dir(torch.cuda.is_available),但是dir(torch.cuda.is_avaliable())是错误的。
-
help():查看某个函数的说明
如果help打开的是某个函数,不能加()。
比如:这个是对的:dir(torch.cuda.is_available),但是dir(torch.cuda.is_avaliable())是错误的。
P5
Python代码运行方式
Python文件:代码是以所有行为一个块运行 优点:适合大型项目,缺点:需要从头运行。
Python console:代码是以每一行为块运行 优点:显示每个变量的属性,缺点:不利于代码阅读和修改。
Jupyter notebook:代码是以任意行为块运行 有点:有利于代码的阅读和修改,缺点:环境需要配置。
P6
使用Pytorch加载数据
- Dataset:提供一种方式去获取数据及其label,并告诉我们总共有多少的数据。
- DataLoader:为神经网络提供不同的数据形式。换个角度:对得到的数据“打包”,将数据按照一次一个batch_size的大小送入神经网络。
读取单张图片操作
# 1.获取img的地址
img_path = "../数据集/练手数据集/train/ants_image/0013035.jpg"
# 2.读取Image
img = Image.open(img_path)
读取一个文件夹的所有图片
# 1.获取文件夹路径
dir_path = "../数据集/练手数据集/train/ants_image"
# 2.获取文件夹下所有图片的名称,os.listdir()返回一个列表,该列表由文件夹下所有图片的名称组成
img_path_list = os.listdir(dir_path)
print(type(img_path_list))
# 3.获取每一张图片的相对路径
img_path_list2 = []
for img_path in img_path_list:
img_path_list2.append(os.path.join(dir_path, img_path))
for img_path in img_path_list2:
img = Image.open(img_path)
print(img.show())
使用Dataset读取数据集中的数据
class MyData(Dataset):
def __init__(self, root_dir, label_dir): # 主要为后面的方法提供一些类变量,供该类的所有函数使用
self.root_dir = root_dir # 获取当前神经网络训练集的根目录
self.label_dir = label_dir # 我理解为训练集中的数据根据它的label分类保存到各自子文件夹中
self.path = os.path.join(self.root_dir, self.label_dir) # 将上述的路径进行拼接
self.img_path = os.listdir(self.path) # 获得当前神经网络所有图片的名称,返回由这些名称组成的列表
def __getitem__(self, idx): # 读取其中的图片
img_name = self.img_path[idx] # 获取列表中第idx张图片的名称
img_item_path = os.path.join(self.path, img_name) # 将名称和其上级目录进行一个拼接
img = Image.open(img_item_path) # 读取图像
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_path = "../数据集/练手数据集/train"
ants_dir_path = "ants_image"
bees_dir_path = "bees_image"
ants_dataset = MyData(root_path, ants_dir_path) # 调用了MyData类的init函数,返回了ants_dataset对象
bees_dataset = MyData(root_path, bees_dir_path) # 调用了MyData类的init函数,返回了ants_dataset对象
train_dataset = ants_dataset + bees_dataset # 将两个MyData类对象相加,train_dataset对象包含了两个对象的所有数据
img, label = ants_dataset[0] # 调用了MyData类的getitem函数,返回了img及其label
img.show()
P7
tensorboard的使用
打开tensorboard的方式
用anaconda或者pycharm的 terminal 命令行,在其中输入 tensorboard --logdir='目录位置'
例:tensorboard --logdir=logs
add_scalar()的使用:常用于绘制损失函数
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 将事件文件存储在logs当中
# writer.add_image() # 添加图片
for i in range(100):
# 添加数至tensorboard中,参数如下所示:tag表明图表的名称,scale_value对应图的y轴,global step对应图的x轴
writer.add_scalar("y=x", i, i) # y轴是i,x轴也是i,对应y=x这条曲线
writer.close()
P8
add_image()的使用
from torch.utils.tensorboard import SummaryWriter
# 第一步:加载图片
from PIL import Image
image_path = "../数据集/练手数据集/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path) # img的类型是PIL.JpegImagePlugin.JpegImageFile
import numpy as np
img_array = np.array(img_PIL) # 将PIL类型的图片转换为numpy.ndarray类型
print(type(img_array))
writer = SummaryWriter("logs")
# 添加数至tensorboard中,参数如下所示:
# tag表明图表集的名称,
# img_tensor可以是torch.Tensor,numpy.array,或者string/blobname类型,
# global step对应图表集中具体哪一张图片
# 注:并不是任何numpy类型的数据都可以输入,默认是[3,H,W],可以通过修改dataformats参数接收``CHW``, ``HWC``, ``HW``.这几个类型
writer.add_image(tag="test", img_tensor=img_array, global_step=1,
dataformats='HWC') # 创建test图表集,并将img_array放在图表集下标为1的位置
writer.close() # 一定要写着一句,不然tensorboard中即使刷新网页也不会加载图片
P9 P10 P11 P12
alt + enter:快捷查看当前划红线部分的补救办法
ctrl + p:快捷查看当前函数所需参数及其类型
取消大小写匹配:settings - keymap - 搜索框输入case- Code Completion - 取消Match case前面的框框
transform的使用
transforms.ToTensor():输入IMG,输出Tensor
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法 -》 tensor的数据类型
# 通过transform.ToTensor去解决两个问题
# 1. transform该如何使用(python)
# 2. 为什么我们需要Tensor数据类型
img_path = "../数据集/练手数据集/train/ants_image/0013035.jpg"
img = Image.open(img_path) # img是PIL数据类型
writer = SummaryWriter("logs")
# 1.transforms该如何使用(python):将IMG类型转换为Tensor类型
# 第一步:创建ToTensor对象
tensor_trans = transforms.ToTensor() # tensor是返回的ToTensor对象,调用了ToTensor()的init方法,用于后续将PIL类型的图像转化为totensor类的图像
# 第二步:将图片传入ToTensor对象中,返回了Tensor数据类型的图片
tensor_img = tensor_trans(img) # img由PIL类型转换为totensor类型,调用了ToTensor()的call方法
print(tensor_img)
# 2. 为什么我们需要Tensor数据类型:因为Tensorboard记录图片时要求这个类型
writer.add_image(tag="tensor_img", img_tensor=tensor_img)
writer.close()
transforms.Normalize():输入Tensor,输出Tensor
transforms.Resize():输入IMG,输出IMG;输入tensor,输出tensor
transforms.Compose()
transforms.RandomCrop()输入IMG,输出IMG;输入tensor,输出tensor
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("../数据集/练手数据集/train/ants_image/0013035.jpg") # 读取图片,img是PIL格式
print(img)
# totensor的使用
trans_totensor = transforms.ToTensor() # 创建一个ToTensor类型对象
img_tensor = trans_totensor(img) # 将图片转换为torch.Tensor格式
writer.add_image(tag="ToTensor", img_tensor=img_tensor) # 将图片写到tensorboard中
# Normalize的使用
trans_norm = transforms.Normalize([1, 3, 5], [3, 2, 1]) # 创建一个Normalize类型对象,根据图片的channel输入相应长度的均值和方差列表
img_norm = trans_norm(img_tensor) # 输入的图片必须已经转换为tensor类型,将图片归一化
writer.add_image("Normalize", img_norm, 1)
# Resize的使用
print(img.size)
trans_resize = transforms.Resize((512, 512)) # 创建一个Resize类型的对象,图片裁剪为(512,512)
img_resize = trans_resize(img) # 输入的图片必须是PIL类型,得到的img_resize仍然是PIL类型
img_resize = trans_totensor(img_resize) # 再将数据转换成torch.Tensor类型
writer.add_image("Resize", img_resize, 0)
print(img_resize)
# Compose的使用(将transforms的多个操作合并在一起写)
trains_resize_2 = transforms.Resize(512) # 创建一个Resize类型的对象,图片缩放至(512),长宽比不变
# PIL -> PIL -> torch.tensor
trans_compose = transforms.Compose([trains_resize_2,
trans_totensor]) # 创建一个Compose类型,提供transforms对象数组作为参数,注意它是按照数组中元素的顺序依次对图片执行操作,所以后一个数组元素所需要的输入和前一个数组元素的输出要匹配
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
# RandomCrop
trans_random = transforms.RandomCrop((500, 700)) # 创建一个RandomCrop类型对象,随机裁剪出(500,700)的图像,裁剪后返回的图片仍然是PIL类型
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
P13
torchvision的使用
torchvision中的数据集查找路径 python.org - Docs - torchvision - datasets
Torchvision中的Datasets (pytorch.org):包含大量数据集
常用数据集
-
COCO数据集:用于目标检测 、语义分割
-
MNIST数据集:手写文字数据集
-
CIFAR 10 数据集:物体识别
https://pytorch.org/vision/stable/models.html:包含预训练好的model
通过打断点的方式可以获取test_set的属性和方法

# 标准数据集
import torchvision
from torch.utils.data import DataLoader
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
# 四个参数,root指定根目录,train指定是否为训练集,download设为true时会查看本地有无数据,无就从网上下载数据,有就什么事情都不做
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
print(train_set[0]) # (, 6)
# 可以看到train_set与之前我们自定义的Dataset类很像,通过下标获取元素跟我们调用getitem方法类似
img, target = test_set[0]
print(img)
print(img.show()) # 展示图片
print(target)
print(test_set.classes[target]) # 通过classes属性获取具体的类别名称
print(test_set[0])
P14
DataLoader的使用
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
# 从数据集中加载数据
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False,transform=torchvision.transforms.ToTensor())
# DataLoader是PyTorch版本的dataset类,用于分批次从数据集中取数据
# 将数据加载到DataLoader中,dataset指定数据集,batch_size指定每次从数据集抽取的数据量,shuffle指定多个epoch中是否打乱数据读取顺序,num_workers指定加载数据的进程数,drop_last指定剩余的数据小于batch_size时是否还用于训练
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for epoch in range(2):
# 将shuffle设置成false,两轮循环的数据都是相同的,反之,如果设置为true,两轮循环的数据就是相同的
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
P15
nn.Module的搭建(init,forward)
torch.nn官方文档:torch.nn
- containers:给神经网络定义了一些结构,只要往其中添加内容就可以搭建好一个神经网络。
- Module:对所有神经网络提供的基础类,自己搭建的神经网络都要继承该类
- Sequential
- ModuleList
- ModuleDict
- ParameterList
- ParameterDict
- convolution layers:卷积层
- Pooling layers:池化层
- Padding layers
- Non-linear Activation:非线性激活函数
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
def forward(self, input):
output = input + 1
return output
myModule = MyModule() # 调用了MyModule类的init方法,返回一个MyModule对象
x = torch.tensor(1.0)
output = myModule(x) # 调用了MyModule类的forward方法,返回output
print(output)
P16
torch.nn和torch.nn.functional有什么区别?+ conv2d的作用
先看一下torch.nn.Conv2d()与torch.nn.functional.conv2d()的区别
torch.nn.Conv2d()的参数
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
#in_channels:输入图片的通道数
#out_channels:由卷积核数量决定
#kernel_size:卷积核函数的大小
#stride:步长。默认为1
#padding:填充。默认为0
#dilation:核函数元素之间的间隔。默认为1
#groups:对输入的通道进行分组卷积核操作
#bias:偏置,如果为True,向output中添加一个可学习的偏置参数。默认为True
torch.nn.functional.conv2d()的参数
#torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
#input:输入tensor的大小(mini_batch,in_channels,iH,iW)
#weight:权重大小(out_channels,in_channels/groups,kH,kW)
#bias:偏置,tensor数据类型 shape为(out_channels),默认为None
#stride:步长,
#padding:填充
不同点:
- torch.nn.Conv2d()是一个类,而torch.nn.functional.conv2d()是一个函数。
- 用类构造简单计算浪费算力,用函数有时候不能表示清楚神经网络的架构。所以有函数与类两种表达方式
相同点:
- torch.nn.Conv2d()在计算的时候调用了torch.nn.functional.conv2d()。
conv2d的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]]) # 仿照图片格式创建一个二维矩阵
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]
]) # 创建卷积核函数
# torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
# input:输入tensor的大小(mini_batch,in_channels,iH,iW)
# weight:权重大小(out_channels,in_channels/groups,kH,kW)
# bias:偏置,tensor数据类型 shape为(out_channels),默认为None
# stride:步长,
# padding:填充
# input/kernel size = (batch_size,channel,height,width),一因为conv2d函数对参数有形状要求,所以要reshape
input = torch.reshape(input, [1, 1, 5, 5])
kernel = torch.reshape(kernel, [1, 1, 3, 3])
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1) # 对input按照卷积核kernel进行s=1,p=0的卷积操作
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=2, padding=1)
print(output3)
P17
nn.MaxPool2d(最大池化,又称做下采样)
nn.MaxPool2d()的参数
#Parameters
# kernel_size:池化核函数的大小
# stride:步长,默认等于kernel_size
# dilation:控制核函数单元的间隔
# return_indices - if True , will return the max indices along with the outputs
# ceil_mode:True时采用cell型,即如果步长不一致,导致核函数与对应的原图部分大小不一致,仍然保留这一组的池化值,False时采用floor型,就不保留这一组池化值
注意:nn.MaxPool2d()的输入输出要求如下
- Input:(N,C,iH,iW) or(C,iH,iW)
- Output:(N,C,oW,oH) or (C,oW,oH)
m = nn.MaxPool2d(3,stride=2)
input = torch,randn(20,16,50,32)
output = m(input)
池化的作用:有点类似于马赛克,池化之后的图片会更加模糊,但是减少了数据量,降低了计算量。
nn.MaxUnPool2d(上采样)
P18
nn.ReLU(非线性激活函数之一)
nn.ReLU()的参数
# 参数:inplace。如果inplace是True,则为引用传递,会改变实参,若为False,则为值传递,不改实参。
# Input:任意维度
# Output:与Input相同的维度
nn.ReLU()示例:
m = nn.ReLU()
input = torch.randn(2)
output = m(input)
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2)) # -1表示batch_size自己算
print(input.shape)
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.relu1 = ReLU() # inplace可以理解为引用,如果是False,则是值传递,否则,是引用传递,会修改传入的变量
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
myModule = MyModule() # 调用MyModule类的init方法,创建MyModule对象
writer = SummaryWriter("logs_relu")
step = 0
for data in dataloader:
imgs, targets = data # 一次读取64张图片,imgs.shape = (64,3,32,32)
writer.add_images("input", imgs, global_step=step)
output = myModule(imgs) # output.shape = (64,3,32,32) ,对每一个数据做sigmoid操作,不改变input的维度
writer.add_images("output", output, step)
step = step + 1
writer.close()
P19
nn.Linear(线性连接)
nn.Linear的参数
# in_features:输入的size
# out_features:输出的size
# bias:偏置,默认为True
# Input:(*,iH)
# Output:(*,oH)
# 仅对输入tensor的最后一层进行全连接计算,如下所示:
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size()) # torch.Size([128, 30])
nn.BatchNorm2d
nn.transformer
nn.Dropout
nn.Embedding
P20
nn.Sequential(整和神经网络模型的所有操作)
以CIFAR-10网络架构作为示例

检测网络模型是否正确:创建一个tensor对象,输入到模型中,看看能不能正常运行输出结果。(代码见下方代码块中)
如果经过卷积和池化之后不记得当前size,Linear层第一个参数如何填入:注释掉Linear层后面的参数,创建一个tensor对象,输入到模型中,查看输出结果的尺寸,即可求得当前size。
tensorboard中可视化神经网络架构的方法
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torch
from torch.utils.tensorboard import SummaryWriter
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
# 检验模型是否出错,创建一个MyModule对象,传入模型中,看看运行结果是否正确
myModule = MyModule()
input = torch.ones((64, 3, 32, 32))
output = myModule(input)
print(output.shape)
# 使用tensorboard可视化神经网络架构
# writer.add_graph(myModule,input) 第一个参数是模型对象,第二个参数是模型的输入
writer = SummaryWriter("logs_seq")
writer.add_graph(myModule, input)
writer.close()
如图所示,以下是tensorboard中保存的myModule结构:
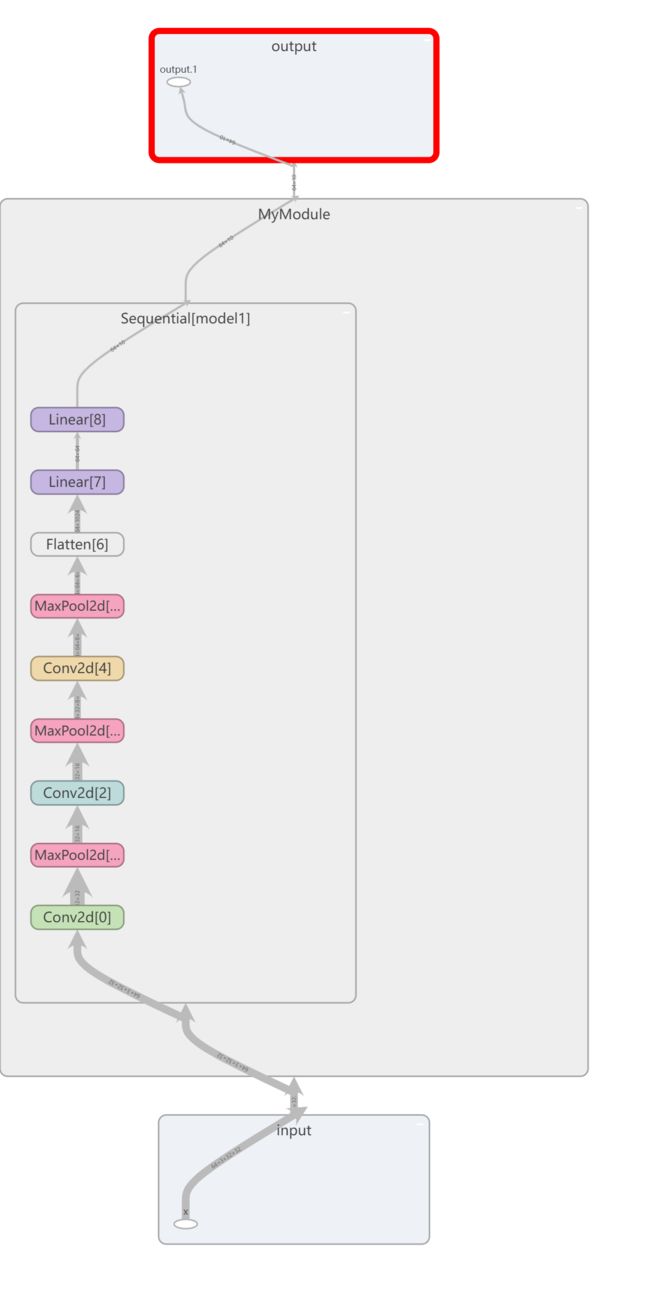
P21
nn.loss(损失函数汇总)
Pytorch官网lossfunction:torch.nn loss functions
-
nn.L1Loss:绝对值损失函数
-
参数
-
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean') size_average: reduce: reduction:
-
-
输入与输出
-
Input: 任意维度 Target: 与Input相同维度
-
-
-
nn.MSELoss:平方差损失函数
-
参数
-
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
-
-
输入与输出
-
Input: 任意维度 Target: 与Input相同维度
-
-
-
nn.CrossEntropyLoss:交叉熵损失函数
-
参数:
-
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0) weight size_average ignore_index reduce reduction label_smoothing
-
-
输入与输出
-
Input:(N,C) or (C) or (N,C,d1,2) Output:(N) or () or (N,d1,d2,d3,...dk)
-
-
在nn中使用loss示例:
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
myModule = MyModule()
for data in dataloader:
imgs, targets = data # img.shape = (64,3,32,32), targets.shape = (1)
outputs = myModule(imgs) # outputs.shape = (1,10)
result_loss = loss(outputs, targets)
result_loss.backward()
# print(outputs)
# print(targets)
# print(result_loss)
P22
torch.optim(优化器)
优化器示例:
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
for input, target in dataset:
optimizer.zero_grad() # 每一个batch梯度都要重置为0
output = model(input) # 前向传播,计算输出值
loss = loss_fn(output, target) # 损失函数计算
loss.backward() # 反向传播,计算梯度
optimizer.step(closure) # 模型参数优化
# 调用step()方法,会利用之前反向传播得到的梯度更新
完整示例:
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
myModule = MyModule() # 创建MyModule类对象
optim = torch.optim.SGD(myModule.parameters(), lr=0.01) # 创建随机梯度下降法优化器
for epoch in range(20):
running_loss = 0.0 # 统计每一个epoch的损失情况
for data in dataloader:
imgs, targets = data # imgs.shape = (64,3,32,32) targets.shape = (1,10)
outputs = myModule(imgs) # 前向传播 outputs.shape = (1),符合loss的参数要求
result_loss = loss(outputs, targets) # 计算损失 reslut_loss.shape = () 它就是一个数
optim.zero_grad() # 将grads设为0,上一批数据的梯度对这一批数据没有影响
result_loss.backward() # 反向传播
optim.step() # 参数优化
running_loss = running_loss + result_loss
print(running_loss)
P23
常见神经网络模型Pytorch网址:Models and pre-trained weights
torchvision.models.vgg16
-
参数:
torchvision.models.vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) # pretrained:如果为True,则返回框架+模型参数,如果为False,仅返回框架 # progress:如果为True,显示下载进度条;否则不显示
迁移学习
import torchvision
# root指定根目录,split指定数据集还是训练集,download指定是否下载该数据集,transform指定数据是否要修改数据类型
# train_data = torchvision.datasets.ImageNet(root="./data_image_net", split="train", download=True,
# transform=torchvision.transforms.ToTensor())
# pretrained为false,没有得到预训练好的模型参数;progress为true,显示进度条,
# 当pretrained为false的时候,它只是加载网络模型(相当于把写好了模型的代码),不会下载对应的数据集,
# 当pretrained为true的时候,它需要下载预训练好的模型参数
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("ok")
# print(vgg16_true)
# 如何利用现有的网络进行迁移学习
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 操作:vgg16在classifier后添加线性层
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
# 操作:vgg在classiffier中添加线性层
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
# 操作:修改vgg中classifier某一神经网络层的结构
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
P24
模型的保存和加载
模型保存
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1
# 保存了模型的结构 + 参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2(官方推荐)
# 将vgg16的状态保存成一种字典形式,保存了模型的参数
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 使用方式一保存和加载模型的陷阱
# class MyModel(nn.Module):
# def __init__(self):
# super(MyModel, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# def forward(self, x):
# x = self.conv1(x)
# return x
# myModule = MyModule()
# torch.save(myModule, 'mymodel_method1.pth')
模型加载
import torch
import torchvision
from torch import nn
# 加载方式1
model = torch.load("vgg16_method1.pth")
# print(model)
# 加载方式2(因为只保存了模型的参数,所以要恢复模型的结构)
vgg16 = torchvision.models.vgg16(pretrained=False) # 获取了网络模型的结构
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) # 通过字典形式加载本地存储的网络模型的参数
# model = torch.load("vgg16_method2.pth")
# print(model)
# print(vgg16)
model = torch.load('mymodel_method1.pth')
print(model)
P25 | P26 | P27
模型的训练套路
第一步:准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True) # root指定根目录,train指定数据是训练集还是数据集,transform是对原始数据进行一些形状调整,方便神经网络读入,download指定是否下载数据集
Pytorch已经内置了常用的数据集和神经网络模型,可以在官网上上找到。附上链接Datasets — Torchvision 0.12 documentation (pytorch.org)
第二步:使用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64,shuffle=True) # 将数据集装入DataLoader中,batch_size设置部分数据用于梯度下降,shuffle指定是否打乱数据集
第三步:搭建/加载神经网络
# 搭建神经网络(仿写搭建CIFAR-10网络结构)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential( #nn.Sequential()简化神经网络编写的过程
nn.Conv2d(3, 32, 5, 1, 2), # nn.Conv2d前五个参数(in_channel,out_channel,卷积核函数,stride,padding)
nn.MaxPool2d(2), # 池化核函数2×2
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(), # 把神经网络拉直
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 加载模型
from 神经网络类所在文件名 import * # 加载模型
一般情况下,神经网络类中编写init和forward函数。
第四步:创建网络模型对象
myModule = MyModule()
第五步:创建损失函数
loss_fn = nn.CrossEntroyLoss()
第六步:创建优化器
config = {
"learning_rate": 1e-2,
"momentum": 0.9
}
optimizer = torch.optim.SGD(myModule.parameters(), lr=config["learning_rate"], momentum=config["momentum"])
第七步:设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train") # tensorboard用于可视化神经网络结构和训练过程,这里的参数指定了tensorboard记录的目录,查看文本的方式是在pycharm的terminal中切换到当前.py文件的目录中,输入命令 tensorboard --logdir=logs_train 会弹出网址,网址中可以实现查看网络结构等操作。
第八步:开始训练
for i in range(epoch):
print("------------------------第{}轮训练开始-----------------------".format(i + 1))
# 训练步骤开始
myModule.train() # 不设置也可以训练
for data in train_dataloader: # 读取train_dataloader中的data
imgs, targets = data # 1.读取data中的imgs,targets
outputs = myModule(imgs) # 2.前向传播
loss = loss_fn(outputs, targets) # 3. 损失函数计算
# 优化器优化模型
optimizer.zero_grad() # 4.重置梯度值
loss.backward() # 5.反向传播
optimizer.step() # 6.模型优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) # 不加item是tensor类型,加了item是数据
writer.add_scalar("train_loss", loss.item(), total_train_step) # 这里用上了add_scalar(),第一个参数train_loss是可视化的图表的名称,第二个参数loss.item()指定了y轴,第三个参数指定了x轴。
# 测试步骤开始(使用tensorboard可以实时查看损失函数走势,使用argmax可以求出outputs中各行的最大值,再与targets比较,进而得出正确率)
myModule.eval() # 不设置也可以测试
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader: # 读取test_dataloader中的data
imgs, targets = data # 1.读取data中的imgs,targets
outputs = myModule(imgs) # 2.前向传播
loss = loss_fn(outputs, targets) # 3,损失函数计算
total_test_loss = total_test_loss + loss # 统计损失值
accuracy = (outputs.argmax(1) == targets).sum() # 计算准确率
total_accuracy = total_accuracy + accuracy # 统计准确率
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step) # 这里用上了add_scalar(),第一个参数test_loss是可视化的图表的名称,第二个参数total_test_loss指定了y轴,第三个参数指定了x轴。
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step) # 这里用上了add_scalar(),第一个参数test_accuracy是可视化的图表的名称,第二个参数total_accuracy / test_data_size 指定了y轴,第三个参数指定了x轴。
total_test_step = total_test_step + 1
# 模型保存的方式一
torch.save(myModule, "mymodule_{}.pth".format(i))
# 模型保存的方式二
torch.save(myModule.state_dict(), "mymodule_{}.pth".format(i))
print("模型已经保存")
writer.close()
tensorboard训练结果展示

myModule.train()和myModule.eval()对特定的层(dropout,batchNorm)有作用,如果自己的网络结构中没有这些层,加不加这两句关系不大。
P28
GPU训练(第一种方式)
- 找到自己创建的网络类的对象(第四步) + 训练集/测试集从dataloader中读取的数据(输入,标注)(第八步) + 损失函数(第五步)
- 在它们后面加.cuda()
# 第一种gpu训练的方式
# 第一步:找到网络模型 + 数据(输入,标注) + 损失函数
# 第二步:.cuda()
# 第二种gpu训练的方式
# .to(device)
# Device = torch.device("cpu")
# Torch.device("cuda")
# Torch.device("cuda:0") # 指定训练的显卡
# Torch.device("cuda:1")
import time
import torch.optim.optimizer
import torchvision.datasets
from torch import nn
# 第一步:准备数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化:把train_data_size带入{}中
print("训练数据集的长度为:{}".format(test_data_size)) # 字符串格式化:把test_data_size带入{}中
# 第二步:利用dataloader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 第三步:搭建/加载神经网络
# 第一种方式:搭建网络
# class MyModule(nn.Module):
# def __init__(self):
# super(MyModule, self).__init__()
# self.model = nn.Sequential(
# nn.Conv2d(3, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 64, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Flatten(),
# nn.Linear(64 * 4 * 4, 64),
# nn.Linear(64, 10)
# )
#
# def forward(self, x):
# x = self.model(x)
# return x
from P25_model import * # 第二种方式:加载网络
# 第四步:创建网络模型对象
myModule = MyModule()
if torch.cuda.is_available():
myModule = myModule.cuda() # 找到了网络模型,使用gpu计算时用.cuda
# 第五步:创建损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda() # 找到了损失函数,使用gpu计算时用.cuda
# 第六步:创建优化器
config = {
"learning_rate": 1e-2,
"momentum": 0.9
}
optimizer = torch.optim.SGD(myModule.parameters(), lr=config["learning_rate"], momentum=config["momentum"])
# 第七步:设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
# 第八步
for i in range(epoch):
print("------------------------第{}轮训练开始-----------------------".format(i + 1))
# 训练步骤开始
myModule.train() # 不设置也可以训练
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 找到了数据,使用gpu计算时用.cuda
targets = targets.cuda() # 找到了标注,使用gpu计算时用.cuda
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 重置梯度值
loss.backward() # 反向传播
optimizer.step() # 模型优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) # 不加item是tensor类型,加了item是数据
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始(使用tensorboard可以实时查看损失函数走势,使用argmax可以求出输出outputs中各行的最大值,再与targets比较,进而得出正确率)
myModule.eval() # 不设置也可以测试
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 找到了数据,使用gpu计算时用.cuda
targets = targets.cuda() # 找到了标注,使用gpu计算时用.cuda
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 模型保存的方式一
torch.save(myModule, "mymodule_{}.pth".format(i))
# 模型保存的方式二
torch.save(myModule.state_dict(), "mymodule_0.pth".format(i))
print("模型已经保存")
writer.close()
P29
GPU训练(第二种方式)
# 第二种gpu训练的方式 对
# .to(device)
# device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
# myModule.to(device)
# loss.to(device)
# imgs.to(device)
# labels.to(device)
示例:
# .to(device)
# device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
# myModule.to(device)
# loss.to(device)
# imgs.to(device)
# labels.to(device)
import time
import torch.optim.optimizer
import torchvision.datasets
from torch import nn
# 第零步:定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
# 第一步:准备数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size)) # 字符串格式化:把train_data_size带入{}中
print("训练数据集的长度为:{}".format(test_data_size)) # 字符串格式化:把test_data_size带入{}中
# 第二步:利用dataloader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 第三步:搭建/加载神经网络
# class MyModule(nn.Module):
# def __init__(self):
# super(MyModule, self).__init__()
# self.model = nn.Sequential(
# nn.Conv2d(3, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 32, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Conv2d(32, 64, 5, 1, 2),
# nn.MaxPool2d(2),
# nn.Flatten(),
# nn.Linear(64 * 4 * 4, 64),
# nn.Linear(64, 10)
# )
#
# def forward(self, x):
# x = self.model(x)
# return x
from P25_model import * # 加载模型
# 第四步:创建网络模型对象
myModule = MyModule()
myModule = myModule.to(device) # 找到了网络模型,使用gpu计算时用.cuda
# 第五步:创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 第六步:创建优化器
config = {
"learning_rate": 1e-2,
"momentum": 0.9
}
optimizer = torch.optim.SGD(myModule.parameters(), lr=config["learning_rate"], momentum=config["momentum"])
# 第七步:设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("------------------------第{}轮训练开始-----------------------".format(i + 1))
# 训练步骤开始
myModule.train() # 不设置也可以训练
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 找到了数据,使用gpu计算时用.cuda
targets = targets.to(device) # 找到了标注,使用gpu计算时用.cuda
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 重置梯度值
loss.backward() # 反向传播
optimizer.step() # 模型优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) # 不加item是tensor类型,加了item是数据
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始(使用tensorboard可以实时查看损失函数走势,使用argmax可以求出输出outputs中各行的最大值,再与targets比较,进而得出正确率)
myModule.eval() # 不设置也可以测试
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 找到了数据,使用gpu计算时用.cuda
targets = targets.to(device) # 找到了标注,使用gpu计算时用.cuda
outputs = myModule(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 模型保存的方式一
torch.save(myModule, "mymodule_{}.pth".format(i))
# 模型保存的方式二
torch.save(myModule.state_dict(), "mymodule_0.pth".format(i))
print("模型已经保存")
writer.close()
P30
完整的模型验证套路
Pytorch创建神经网络
第一步:准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True) # root指定根目录,train指定数据是训练集还是数据集,transform是对原始数据进行一些形状调整,方便神经网络读入,download指定是否下载数据集
Pytorch已经内置了常用的数据集和神经网络模型,可以在官网上上找到。附上链接Datasets — Torchvision 0.12 documentation (pytorch.org)
第二步:使用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64,shuffle=True) # 将数据集装入DataLoader中,batch_size设置部分数据用于梯度下降,shuffle指定是否打乱数据集
第三步:搭建/加载神经网络
# 搭建神经网络(仿写搭建CIFAR-10网络结构)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential( #nn.Sequential()简化神经网络编写的过程
nn.Conv2d(3, 32, 5, 1, 2), # nn.Conv2d前五个参数(in_channel,out_channel,卷积核函数,stride,padding)
nn.MaxPool2d(2), # 池化核函数2×2
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(), # 把神经网络拉直
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 加载模型
from 神经网络类所在文件名 import * # 加载模型
一般情况下,神经网络类中编写init和forward函数。
第四步:创建网络模型对象
myModule = MyModule()
第五步:创建损失函数
loss_fn = nn.CrossEntroyLoss()
第六步:创建优化器
config = {
"learning_rate": 1e-2,
"momentum": 0.9
}
optimizer = torch.optim.SGD(myModule.parameters(), lr=config["learning_rate"], momentum=config["momentum"])
第七步:设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train") # tensorboard用于可视化神经网络结构和训练过程,这里的参数指定了tensorboard记录的目录,查看文本的方式是在pycharm的terminal中切换到当前.py文件的目录中,输入命令 tensorboard --logdir=logs_train 会弹出网址,网址中可以实现查看网络结构等操作。
第八步:开始训练
for i in range(epoch):
print("------------------------第{}轮训练开始-----------------------".format(i + 1))
# 训练步骤开始
myModule.train() # 不设置也可以训练
for data in train_dataloader: # 读取train_dataloader中的data
imgs, targets = data # 1.读取data中的imgs,targets
outputs = myModule(imgs) # 2.前向传播
loss = loss_fn(outputs, targets) # 3. 损失函数计算
# 优化器优化模型
optimizer.zero_grad() # 4.重置梯度值
loss.backward() # 5.反向传播
optimizer.step() # 6.模型优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) # 不加item是tensor类型,加了item是数据
writer.add_scalar("train_loss", loss.item(), total_train_step) # 这里用上了tensorboard,第一个参数train_loss是可视化的图表的名称,第二个参数loss.item()指定了自变量,第三个参数指定了图表中的某个图。
# 测试步骤开始(使用tensorboard可以实时查看损失函数走势,使用argmax可以求出outputs中各行的最大值,再与targets比较,进而得出正确率)
myModule.eval() # 不设置也可以测试
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader: # 读取test_dataloader中的data
imgs, targets = data # 1.读取data中的imgs,targets
outputs = myModule(imgs) # 2.前向传播
loss = loss_fn(outputs, targets) # 3,损失函数计算
total_test_loss = total_test_loss + loss # 统计损失值
accuracy = (outputs.argmax(1) == targets).sum() # 计算准确率
total_accuracy = total_accuracy + accuracy # 统计准确率
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step) # 这里用上了tensorboard,第一个参数test_loss是可视化的图表的名称,第二个参数total_test_loss指定了自变量,第三个参数指定了图表中的某个图。
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step) # 这里用上了tensorboard,第一个参数test_accuracy是可视化的图表的名称,第二个参数total_accuracy / test_data_size 指定了自变量,第三个参数指定了图表中的某个图。
total_test_step = total_test_step + 1
# 模型保存的方式一
torch.save(myModule, "mymodule_{}.pth".format(i))
# 模型保存的方式二
torch.save(myModule.state_dict(), "mymodule_{}.pth".format(i))
print("模型已经保存")
writer.close()
tensorboard训练结果展示

参考视频:PyTorch深度学习快速入门教程 哔哩哔哩_bilibili
typora + picgo + 阿里云 制作远程图片服务器(后续有需要可以出一期搭建教程)