sklearn实现随机森林(分类算法)
阿喽哈~小伙伴们,今天我们来唠一唠随机森林 ♣ ♣ ♣
随机森林应该是很多小伙伴们在学机器学习算法时最先接触到的集成算法,我们先简单介绍一下集成学习的大家族吧:
- Bagging:个体评估器之间不存在强依赖关系,一系列个体学习器可以并行生成。代表算法:随机森林(Random Forest)
- Boosting:个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成。代表算法:AdaBoost、GBDT、XGBoost、LightGBM
在Bagging集成中,需要并行建立多个弱评估器(非线性算法),然后综合多个弱评估器的结果进行输出:
- Bootstrap: 从原始样本集中采用有放回抽样的方式抽取n个训练样本,共进行k轮抽取,得到k个相互独立的训练集
- 对每个训练集进行训练,得到k个模型
- 对分类问题:预测结果为k个分类器投票方式得到的分类结果,少数服从多数
- 对回归问题:将学习器的均值作为预测结果
随机森林是bagging家族的代表算法,它的算法思想体现在它的名字上:“随机”和“森林”。首先“森林”是指随机森林的所有基学习器都是决策树,“随机”是指随机从原样本集中抽取样本和特征来训练,并不会使用所有的样本和特征,每棵树独立地有放回抽样,这就保证了每棵树所使用的数据集是不同的,进而所生成的树也是有差异的,最后集成所有树的决策结果,得到最终结果。具体算法流程如下:
从样本中随机抽取不同的子集,用于建立不同的决策树,在按照Bagging的规则对决策结果进行集成:
- 从M个的原始样本集中采用有放回抽样的方式抽取m个训练样本,共进行k轮抽取,得到k个相互独立的训练集,即有k个基学习器,注意:每颗树的特征并不是在建树前就抽好的,而是在每棵树分裂的节点进行抽样
- 用决策树算法对每个训练集进行训练,得到k个树
- 对分类问题:预测结果为k个分类器投票方式得到的分类结果,少数服从多数
- 对回归问题:将学习器的均值作为预测结果
具体更深入的算法原理这里就不多说啦,本篇的重点是演示如何使用Sklearn实现随机森林以及简单的调参,上代码~
1、导入各种包
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OrdinalEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import ensemble
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 242、数据准备
为了方便大家代码复现,本次使用的是python自带的泰坦尼克号数据集,共981个样本,特征涉及性别、年龄、船票价格、是否有同伴等等,标签列有两个,分别是‘survived’和‘alive’,都表示该乘客是否生还,所以我们取一列就可以了
data = sns.load_dataset('titanic') # 导入泰坦尼克号生还数据
data
3、数据预处理
data.replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True) # 把各类缺失类型统一改为NaN的形式
data.isnull().mean()
共4列数据存在缺失值,‘deck’缺失率超过70%,予以删除,剩余特征的缺失值使用其均值或是众数进行填补
细心地童鞋可能发现了有好几列重复的特征,‘embarked’和‘embark_town’都表示出发港口,‘sex’、‘who’、‘adult_male’都表示性别,‘pclass’和‘class’都是船票类型,‘sibsp’和‘alone’都表示是否有同伴,对于这几个特征,所以我们保留其中一个就可以了
del data['deck'] # 删除‘deck’列
del data['who']
del data['adult_male']
del data['class']
del data['alone']
data['age'].fillna(np.mean(data.age), inplace=True) # 年龄特征使用均值对缺失值进行填补
data['embarked'].fillna(data['embarked'].mode(dropna=False)[0], inplace=True) # 文本型特征视同众数进行缺失值填补
x = data.drop(['alive', 'survived', 'embark_town'], axis=1) # 取出用于建模的特征列X
label = data['survived'] # 取出标签列Ysklean中的随机森林算法是无法进行字符串的处理的,所以要先进行数据编码,这里我们就使用最简单的特征编码,转化完毕后特征全部变为数值型
oe = OrdinalEncoder() # 定义特征转化函数
# 把需要转化的特征都写进去
x[['sex', 'embarked']] = oe.fit_transform(x[['sex', 'embarked']])
x.head()
# 划分训练集、测试集
xtrain, xtest, ytrain, ytest = train_test_split(x, label, test_size=0.3)
xtrain.head() 
ok,基本的数据预处理已经完成了,然后就小试牛刀,把数据集扔进随机森林里看看效果吧
4、训练模型
"""
随机森林所有超参数
sklearn.ensemble.RandomForestClassifier (n_estimators=100, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, class_weight=None, random_state=None, bootstrap=True, oob_score=False,
n_jobs=None, verbose=0, warm_start=False)
"""下面把随机森林与单个决策树的拟合效果放在一起对比
# 单颗决策树
clf = DecisionTreeClassifier(class_weight='balanced',random_state=37)
clf = clf.fit(xtrain, ytrain) # 拟合训练集
score_c = clf.score(xtest, ytest) # 输出测试集准确率
# 随机森林
rfc = RandomForestClassifier(class_weight='balanced',random_state=37)
rfc = rfc.fit(xtrain, ytrain)
score_r = rfc.score(xtest, ytest)![]()
这里的score封装的是准确率,即(模型预测正确的样本量)/(模型的总样本量),因此容易受到样本不均匀的影响,尤其是像癌症预测、信贷逾期预测之类的模型,响应样本的占比就很少,100个人中可能就1个人会有逾期的行为,对于这种情况,我们应该使用AUC这类评价指标,可以平衡样本量偏颇带来的影响,那下面我们来看一看单科决策树和随机森林的AUC情况吧
5、模型效果
# 决策树 预测测试集
y_test_proba_clf = clf.predict_proba(xtest)
false_positive_rate_clf, recall_clf, thresholds_clf = roc_curve(ytest, y_test_proba_clf[:, 1])
# 决策树 AUC指标
roc_auc_clf = auc(false_positive_rate_clf, recall_clf)
# 随机森林 预测测试集
y_test_proba_rfc = rfc.predict_proba(xtest)
false_positive_rate_rfc, recall_rfc, thresholds_rfc = roc_curve(ytest, y_test_proba_rfc[:, 1])
# 随机森林 AUC指标
roc_auc_rfc = auc(false_positive_rate_rfc, recall_rfc)
# 画图 画出俩模型的ROC曲线
plt.plot(false_positive_rate_clf, recall_clf, color='blue', label='AUC_clf=%0.3f' % roc_auc_clf)
plt.plot(false_positive_rate_rfc, recall_rfc, color='orange', label='AUC_rfc=%0.3f' % roc_auc_rfc)
plt.legend(loc='best', fontsize=15, frameon=False)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
来瞧一瞧看一看了昂,黄色实线代表随机森林的ROC曲线,蓝色实线代表单棵决策树的ROC曲线,在俩模型均未调参的情况下,明显随机森林的模型效果要比单科决策树的好对吧,所以集成算法还是牛的~
5、调参
接下来我们尝试通过调整随机森林的超参数,来提高模型的性能,评价指标设为AUC
由于随机森林的基学习器均为决策树,因此我们调参的方向也和决策树相同,主要通过控制剪枝的相关参数来防止模型过拟合,这里我们选择两个参数进行调整,分别是:基学习器数量n_estimators和树深max_depth,大家可以使用网格搜索等自动调参工具,这里为了演示调参过程,我们来手动调整参数
# 定义空列表,用来存放每一个基学习器数量所对应的AUC值
superpa = []
# 循环200次
for i in range(200):
rfc = ensemble.RandomForestClassifier(n_estimators=i+1, class_weight='balanced',random_state=37, n_jobs=10)
rfc = rfc.fit(xtrain, ytrain) # 拟合模型
y_test_proba_rfc = rfc.predict_proba(xtest) # 预测测试集
false_positive_rate_rfc, recall_rfc, thresholds_rfc = roc_curve(ytest, y_test_proba_rfc[:, 1])
roc_auc_rfc = auc(false_positive_rate_rfc, recall_rfc) # 计算模型AUC
superpa.append(roc_auc_rfc) # 记录每一轮的AUC值
print(max(superpa),superpa.index(max(superpa))) # 输出最大的AUC值和其对应的轮数
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()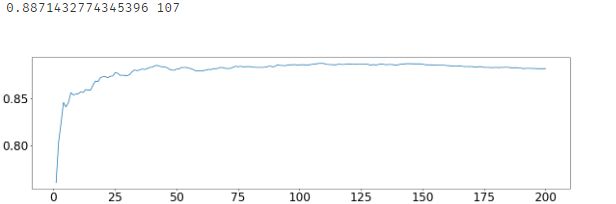
最大AUC为0.8871,对应的轮数是107,即基学习器数量为108时AUC取得最大值0.8871,接下来固定基学习器个数,调整最大树深
superpa = []
for i in range(20):
rfc = ensemble.RandomForestClassifier(max_depth=i+1, n_estimators=185,
class_weight='balanced', random_state=37, n_jobs=10)
rfc = rfc.fit(xtrain, ytrain)
y_test_proba_rfc = rfc.predict_proba(xtest)
false_positive_rate_rfc, recall_rfc, thresholds_rfc = roc_curve(ytest, y_test_proba_rfc[:, 1])
roc_auc_rfc = auc(false_positive_rate_rfc, recall_rfc)
superpa.append(roc_auc_rfc)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,21),superpa)
plt.show()
i=6即树深为7的时候,AUC达到最值0.8983
到此我们调参就结束了,我们通过手动调参,先找到最佳基学习器数量,在此基础上在寻找最佳树深, 但实际上不同的参数组合带来的效果是不同的,啥意思呢,举例说:
我们这边先固定学习器的数量为108,再去找树深,然后我们认为(学习器数量108+树深7)为最佳组合,但是当我们的树深为7时,基学习器的最佳选择可能就不是108了,因为这个108是在不限制树深的情况下跑出来的结果
所以自动调参机器网格搜索就是去枚举尽可能多的参数组合,从中找出最佳的,来弥补手动调参的弊端,但是随着超参数的增加,参数组合可以说是无穷无尽,所以网格搜索也只是尽量找到最佳组合,调参这个工作还是看经验,调的多了慢慢就有感觉了,毕竟调参是门玄学O(∩_∩)O哈哈~
6、特征重要性
因为我们随机森林的基学习器是决策树,所以决策树能干的事情随机森林都能干,比如特征重要性:
#特征重要性
feature_name = x.columns
rfc.feature_importances_
[*zip(feature_name,rfc.feature_importances_)]
然后这个重要性是所有基学习器加在一起的,我们可以看单颗决策树的特征重要性:
tree_3 = rfc.estimators_[2]
rfc.estimators_[2].feature_importances_![]()
随机森林也可以画决策树,但是只能画单棵决策树:
dot_data = tree.export_graphviz(tree_3, feature_names=feature_name, class_names=['good', 'bad'], filled=True, rounded=True)
graph = graphviz.Source(dot_data)
graph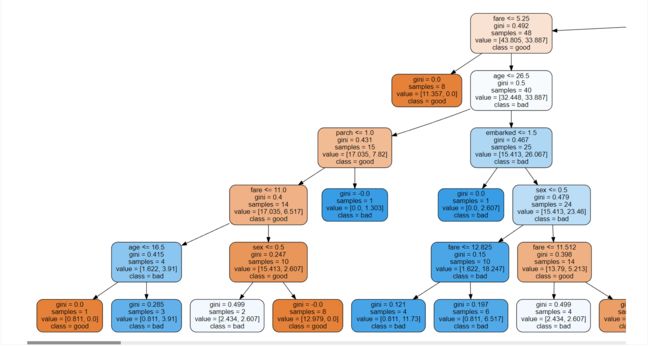
本人才疏学浅,若有理解有误的地方,还请各路大佬批评指正♡♡♡
ok!感恩的心~