pandas学习笔记
Series结构
- Series结构是pandas常用的数据结构之一,由一组数据之和一组标签组成,其中标签和数据之具有对应关系,标签不必是唯一的.
- Series可以保存任何数据类型,整形,字符串,浮点型,python对象等,默认值是整数,从0开始递增

引入pandas:import pandas as pd
pd.Series(data=None,index=None,dtype=None,name=None,copy=False)
- data 输入的数据
- index 指定索引值
- dtype 输出的类型
- name 定义一个名称
- copy 对data进行拷贝
获取下标标签值和属性值
p.index 获取下标值,默认是0到n
list(p.values) 获取所有属性值,可以将转list直接输出
通过标签获取索引和赋值
s1[1] 通过行索引获取第二个数据
s1[0]=50 更改行索引为0的值
s1[-1] 找的是标签值为-1的,不存在从后往前找,但是可以新增,就像添加一行数据
s1["a"]=1 新增不同类型的索引数据,索引类型会发生变化
字典作为数据源创建series
pd.Series({"a":1,"b":1}) 创建之后key会变成索引,也就是行
索引取值
标签如果不存在数值型的数据,我们就可以使用标签取值也可以用索引0-n获取值
如果存在,则不可以使用标签的index获取,只可以用对应的值获取数据
访问多个元素值s1[["a","b"]]
指定索引创建series
如果指定索引,然后用字典构建则只有对应索引的数据会被创建,不存在的补NAN
指定name列名
s1.name 获取列名
s1.name="aa" 指定列名
我们也可以在创建的时候指定name属性
转换成DataFrame之后就会称为列名
切片
s[1:3] 使用python切片
基本方法
s.head() 默认看前5条,可以指定
s.tail() 默认看后五条,可以指定
s.reindex() 重新指定索引
s1 + s2 相同索引的会相加,没有的NaN
s.drop("a",inplace=True) 删除标签为a的值,修改原值
DataFrame数据类型(重要)
- DataFrame是pandas的重要数据结构之一
- 结构有行有多列的.类似表格
- 每个列可以有不同的数据类型
- 同列都是相同数据类型
- 有索引index

pandas.DataFrame(data=None,index=None,columns=None,dtype=None,copy=None)
- data 输入的数据
- index 行标签
- columns 列标签
- dtype 只允许指定一个数据类型,一般不指定
- copy 是否从输入复制数据
嵌套列表创建:每个元素代表一行数据
列表嵌套字典创建:每个元素的key会作为列名称,值为value
字典嵌套列表创建:每个key作为列名称,值的列表每一个元素作为当前key列的数据
指定需要哪些列:构建DataFrame的时候columns指定想要的列就可以筛选
列操作:
df['列名'] 获取列
df[['列名','列名']] 获取多列
注意:获取列不能用切片操作,也不能用索引获取列
df['新列名']=pd.Series([1,2,3]) 添加新的一列
df['新列名']=df['列名']+df['列名'] 可以进行运算返回新的列
del df['列名'] 删除一列
df.pop('列名') 删除一列并且返回删除数据
行操作:
行操作需要借助loc属性来完成
df.loc['b'] 选取行标签为b的数据
df.loc['b','one'] 获取行标签为b,列名为one列的数据
df.loc['a':'b','one'] 获取行标签a-b(包含尾),列为one的数据
df.loc[['a','b'],['one','two']] 获取多行多列
索引获取数据:
我们需要使用iloc来完成
df.iloc[2] 获取行索引为2的数据
df.iloc[[0,2]] 获取行索引0和2的数据
df.iloc[0,1] 获取行索引0和列索引1的数据
添加行数据:
使用append(other,ignore_index=False,verify_integrity=False,sort=False)
- other:DataFrame或series或字典等类对象
- ignore_index:如果是True将按照原本自动添加索引
- verify_integrity:如果为True,则在创建具有重复项的索引报错
- sort:排序
list添加是一维为一行
删除行数据:
使用drop删除某一行数据,如果有重复则一起删除
df.drop('行标签') 默认不会修改原数据,要修改加上inplace=True
设置index列:
#将索引设置为“month”列:
df.set_index('month')
# 将month列设置为index之后,并保留原来的列
df.set_index('month',drop=False)
# 保留原来的index列
df.set_index('month', append=True)
# 使用inplace参数取代原来的对象
df.set_index('month', inplace=True)
# 通过新建Series并将其设置为index
df.set_index(pd.Series(range(4)))
常用属性和方法:
T:转置
axes:返回一个仅以行标签和列标签的列表
dtypes:返回每列数据的类型
empty:判断数据是否长度为0
columns:返回所有列标签
shape:返回一个数组,获取行数和列数
size:元素数量
values:返回所有元素值
head():返回前n条
tail():返回后n条
rename():rename({"old","new"}),修改列名
info():查看基本信息
sort_index():根据行标签对所有行进行排序,或者根据列标签
sort_values():可以根据列数据排序,也可以行数据排序
时间转换:
to_datetime转换时间戳
大部分字符串直接传入即可转换
去重函数:
# 默认情况下,它会基于所有列删除重复的行,就是删除所有列都相同的保留第一行
df.drop_duplicates()
# 删除特定列上的重复项,使用子集,就是删除brand这一列数据相同的数据保留第一行
df.drop_duplicates(subset=['brand'])
# 删除重复项并保留最后出现的项,请使用“保留”。就是删除brand和style这两列相同的数据只保留最后一行 df.drop_duplicates(subset=['brand', 'style'], keep='last')
pandas读取文件
csv文件读取:
pd.read_csv(文件路径,encoding="utf-8",sep="|",header=0,names=["编号", "姓名", "地址", "性别", "出生日期"],index_col="birthday")
- encoding:编码
- sep:分隔符
- header:设置列名第几行
- names:添加列名
- index_col:指定index
设置编码:
df = pd.read_csv(r"data\students_step.csv", encoding="gbk")
设置分隔符
df = pd.read_csv(r"data\students_step.csv", sep="|")
delim_whitespace:
默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、"\t"等等。不管分隔符是什么,只要是空白字符,那么可以通过delim_whitespace=True进行读取。
指定表头行:
pd.read_csv(r"data\students.csv", header=1)
设置表行头内容,并且设定第一行是表头覆盖原表头:
pd.read_csv(r"data\students.csv", names=["编号", "姓名", "地址", "性别", "出生日期"], header=0)
指定索引index列:
df = pd.read_csv(r"data\students.csv", index_col="birthday")
第二种方式
df.index=df['birthday']
del df['birthday']
df.set_index('Date',inplace=True)
指定多列为index:
df2 = pd.read_csv(r"data\students.csv", index_col=["gender","birthday"])
展示指定列的数据:
pd.read_csv(r"data\students.csv", usecols=["name","birthday"])
指定某一列的数据类型:
df = pd.read_csv(r"data\students_step_001.csv", sep="|", dtype ={"id":str}) #用于保存其原本的格式
读取数据对一列进行运算:
pd.read_csv('data\students.csv', converters={"id": lambda x: int(x) + 10})
指定哪些数据清洗为true或false:
pd.read_csv('data\students.csv', true_values=['男'], false_values=['女'])
过滤指定行:
pd.read_csv('data\students.csv', skiprows=[0,3]) # 先进行跳过0和3行,先跳过才会确定表头
pd.read_csv('data\students.csv', skiprows=lambda x: x > 0 and x % 2 == 0) # 也可以传入一个函数
过滤文件末尾行:
pd.read_csv('data\students.csv', skipfooter=1)
pd.read_csv('data\students.csv', skipfooter=1, engine="python", encoding="utf-8") #报错需要指定
设置一次性读取的行数:
pd.read_csv('data\students.csv', nrows=3)
配置哪些值需要处理成NaN:
pd.read_csv('data\students.csv', na_values=["女", "朱梦雪"])
指定某一列为时间列:
df = pd.read_csv('data\students.csv', parse_dates=["birthday"]) #指定为时间列
df2 = pd.read_csv('data\students_年月日.csv', parse_dates=["birthday"], date_parser=lambda x: datetime.strptime(x, "%Y年%m月%d日")) # 自定义格式解析
分块读取数据:
chunk = pd.read_csv('data\students.csv', iterator=True) # 开启迭代器默认为false分批读取
# 文件还剩下三行,但是我们指定读取100,那么也不会报错,不够指定的行数,那么有多少返回多少
print(chunk.get_chunk(100))
try:
# 但是在读取完毕之后,再读的话就会报错了
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
chunk = pd.read_csv('data\students.csv', chunksize=2)
# 还是返回一个类似于迭代器的对象
print(chunk)
#
# 调用get_chunk,如果不指定行数,那么就是默认的chunksize
# 也可以指定
print(chunk.get_chunk(100))
try:
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕 缺失值处理
df.info() 查看基本信息可以可以看出是否有缺失值的列
df.isnull() 返回对应原数据的boolean是否是空
df.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
- axis:0或index,1或columns,默认为0表示删除包含学是指的行
- how:any,all 默认是any,删除至少有一个na的行或者所有na的列
- thresh:输入int,保留至少有几个非空的行
- subset:定义在那些列找缺少的值
- inplace:是否更改原数据
df.fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None)
- value:用于填充的值
- method:两个选择ffill->用空值上面有值的值填充,bfill->用空值下面有值的值填充
- axis:用于填充缺失值的轴
- inplace:是否需改原数据
- limit:设置填充最大几个连续NaN的值
# 删除缺失值
# 删除至少缺少一个元素的行。
df.dropna()
# 删除至少缺少一个元素的列。
df.dropna(axis='1')
# 删除缺少所有元素的行
df.dropna(how='all')
# 仅保留至少有2个非NA值的行
df.dropna(thresh=2)
# 定义在哪些列中查找缺少的值
df.dropna(subset=['toy'])
# 在同一个变量中保留操作数据,修改原本数据
df.dropna(inplace=True)
# 填充缺失值
# 将所有NaN元素替换为0
df.fillna(0)
# 我们还可以向前或向后传播非空值,最近一个值是什么后面的就是什么
df.fillna(method="ffill")
df.fillna(method="bfill")
# 将列“A”、“B”、“C”和“D”中的所有NaN元素分别替换为0、1、2和3。
values = {"A": 0, "B": 1, "C": 2, "D": 3}
df.fillna(value=values)
# 只替换第一个NaN元素
df.fillna(0, limit=1)
# 当使用数据填充时,替换会沿着相同的列名和索引进行
df2 = pd.DataFrame(np.random.rand(4,4), columns=list("ABCE"))
df.fillna(value=df2)
分组聚合
根据数据进行分组,然后应用过滤转换统计函数
- 拆分:对数据进行分组
- 应用:对分组数据应用聚合函数,进行计算
- 合并:最后汇总计算结果
groupby分组:
df.groupby('列名') 根据列的数据进行分组
agg聚合:
data.groupby("company").agg('mean') #求均值 data.groupby('company').agg({'salary':'median','age':'mean'}) #对不同列求不同的值 data.groupby('company').agg({'salary':['median',np.max],'age':'mean'}) # 执行多种操作 data.groupby('company').agg({'salary':lambda x:x**2}) # 可以传入自定义函数
1.0之后得groupby('岗位')[['工资']].agg([('工资','max')])
transform转换
和agg的区别在于,agg聚合之后如果新增一列不能直接添加
第一种方式:
# to_dict将表格中的数据转换成字典格式
avg_salary_dict= data.groupby('company')['salary'].mean().to_dict()
# map()函数可以用于Series对象或DataFrame对象的一列,接收函数作为或字典对象作为参数,返回经过函数或字典映射处理后的值。
data['avg_salary'] = data['company'].map(avg_salary_dict) #对company列和要映射的数据一一对应
第二种方式:
data['avg_salary1'] = data.groupby('company')['salary'].transform('mean') #分组之后统计的均值映射一一对应并且返回那一列
apply操作:
apply比agg和transform更加灵活,能够传入任意自定义的函数,实现复杂的数据操作
案例:
# 假设我现在需要获取各个公司年龄最大的员工的数据 def get_oldest_staff(x): # 输入的数据按照age字段进行排序 df = x.sort_values(by = 'age',ascending=True) # 返回最后一条数据 return df.iloc[-1,:]
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff) #传入函数的时候不需要括号
# '地区'作为索引分组,'年份'与分组列'地区'聚合
# 第一种方法
df_1.groupby(by=['地区'], as_index=True).agg({'年份': ['max', 'min', 'median']}).head()
# 第二种方法,两种方法是等效的
df_1.groupby(by=['地区'], as_index=True).年份.agg(['max', 'min', 'median']).head()
# 指定多列列是聚合列,如:年份、国内生产总值
df_1.groupby(by=['地区'], as_index=True).agg({'年份': 'max', '国内生产总值': 'describe'}).head()
# 返回所有列中的最大值
df_1.groupby(by=['地区'], as_index=True).max().head()
# 获取分组之后的当前索引
df.groupby('item_name').agg({'qu':'sum'}).idxmax()
数据合并
# 取交集
df_1.merge(df_2,on='userid') #两种方式inner
pd.merge(df_1, df_2, on='userid')
# 左连接和右连接,如果没有对应的数据就填空值
pd.merge(df_1, df_2,how='left', on="userid") # 左连接,on指的是根据哪个来连接
pd.merge(df_1, df_2,how='right', on="userid") # 右连接
# 取并集
pd.merge(df_1, df_2,how='outer',on='userid') # 把所有的都展示
#通常用来连接DataFrame对象。默认情况下是对两个DataFrame对象进行纵向连接,
# 当然通过设置参数,也可以通过它实现DataFrame对象的横向连接
df_1 = pd.concat(objs=[df1, df2, df3]) # 合并数据,以行的维度合并
df_1.sample(n=7, replace=False) # 随机不放回抽样 7 个数据
# 横向纵向表堆叠
pd.concat([df1,df2]) # 纵向堆叠
pd.concat([df1,df2],axis=1) # 横向堆叠
pd.concat([df1,df2],join="outer") # 在拼接的时候取两张表的并集,没有的nan填充
pd.concat([df1,df2],join="inner") # 在拼接的时候取两张表的交集,有一边没有的就不拼接字符串操作
pandas中.str方法,之后就可以使用,会自动忽略缺失值


三板斧map-apply-applymap
- apply应用在DataFrame的行或列中
- applymap应用在DataFrame的每个元素中
- map应用在单独一列(Series)的每个元素中
# 默认是一列一列也就是axis=0
df.apply(np.sum)
# 1或“列”:将函数应用于每一行一行一行的进行求和
df.apply(np.sum, axis=1)
# 传入匿名函数进行操作,axis默认等于0则是通过一列一列的数据传入进行操作
df.apply(lambda x: x + 1)
# 当然我们也可以自定义传入多个参数
def cal_result(df, x, y):
df['C'] = (df['A'] + df['B']) * x
df['D'] = (df['A'] + df['B']) * y
return df
有三种方式传参:
df.apply(cal_result, x=3, y=8, axis=1)
df.apply(cal_result, args=(3, 8), axis=1)
df.apply(cal_result, **{'x': 3, 'y': 8}, axis=1)
# 保留两位小数
df.apply(lambda x : format(x,'.2%'))# 保留两位小数
df.applymap(lambda x: '%.2f'%x)
#取列,注意一个[]获取的是series数据,[[]]获取的是dataframe数据,而且这个只能操作dataframe数据不能操作series数据
df[['A']].applymap(lambda x: '%.2f'%x)#map是操作series数据的
df['A'].map(lambda x: '%.2f'%x)
# 替换操作
df['Sex'] = df['Sex'].map({"male":1, "female":0})pandas绘图
# 默认绘图就是线型图,我们只需要数据.plot()即可
# index会作为y轴坐标,列名则会作为图例名称作为展示
# df里没有自带的show()方法,我们想要使用则需要导入matplotlib来使用,可以消除第一行显示的东西
from matplotlib import pyplot as plt
# 设置中文:
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 中文负号
plt.rcParams['axes.unicode_minus'] = False
df.plot(title="我的图形")
# 设置x轴xticks旋转
df["A"].plot(rot=70) 或者
plt.xticks(rotation=70)
# 我们可以单独设置索引和数据
plt.plot(df["A"].index,df["A"])
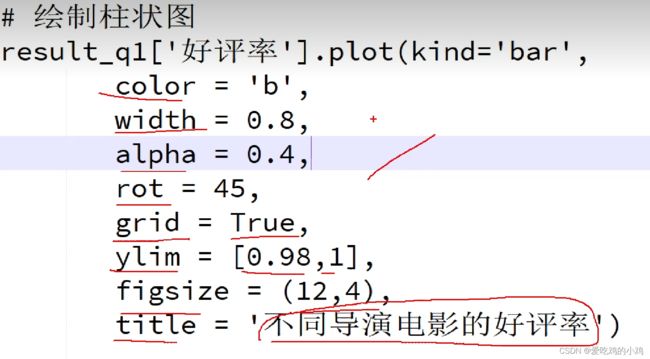
# 柱状图
df.plot.bar() 或者
df.plot(kind="bar")
# 柱状堆叠图
df.plot(kind="bar",stacked=True) 或者
df.plot.bar(stacked="True")
# 横向水平图
df.plot.barh(stacked=True) 或者
df.plot(kind="barh", stacked=True)
# 直方图
#指定箱数为15
df.plot.hist(bins=15)
#使用diff绘制,给每一列都绘制直方图
df.diff().hist(color="r",alpha=0.5,bins=15)
# 箱线图
df.plot.box()
# 区域图,类似与线型图,但是他把其他空位填充了
df.plot.area()
# 散点图,x和y是散点图的点的坐标,但是x和y只能是列名
df.plot.scatter(x="a",y='b')
# 饼状图
# 饼状图需要添加subplots
df.plot.pie(subplots=True)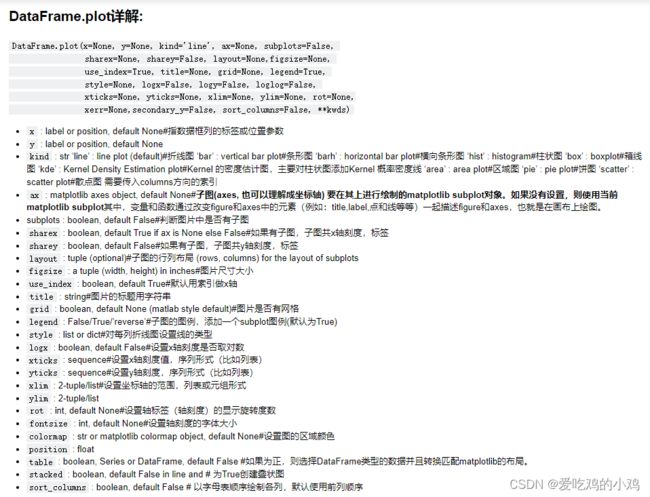

常用操作
df.head(2) # 显示前面两行
df.tail(2) # 显示最后两行
df.info # 相关信息预览
df.describe() #快速综合统计结果异常值处理
# 通过绘制一列的箱线图可以看出异常值
plt.boxplot(data['a']) # 超出上边线的和下边线的点就是有异常值
# 我们定义一个函数来将异常值转换为空值
def replace(x):
import numpy as np
QU = x.quantile(0.75)
QL = x.quantile(0.25)
IQR = QU - QL
x[(x > (QU + 1.5*IQR)) | (x < (QL - 1.5*IQR))] = np.nan
return x
# 我们把有异常值的数据传入进去即可将缺失值转换为空值转换成列表数据:
df.index.tolist() #转换索引为数组
list(df['brand']) #转换brand这一列为数组
dict(df['brand']) #转换brand这一列为字典
df['brand'].to_dict() #转换brand这一列为字典去重操作
chipo['item_name'].unique() # 返回的是去重之后的数据
chipo['item_name'].nunique() # 返回的是去重之后的数量统计个数并且排序
# value_counts() 函数可以对Series里面的每个值进行计数并且排序
chipo['choice_description'].value_counts().head()判断字符串存在这一列?
# 接受一个列表,判断该列中元素是否在列表中
euro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia'])][["Team","Shooting Accuracy"]]描述性统计describe
drinks.groupby('continent').wine_servings.describe() # 返回各种统计之后的均值平均值等信息迭代器循环
for (columnName, columnData) in df.iteritems():
print('行 Name : ', columnName)
print('列 Contents : ', columnData.values)
print("===============")数据抽样
# replace允许或不允许对同一行进行多次采样,默认就是False
data = df.sample(n=5, replace=False) # 不放回随机抽样 5 个数据重置索引
# 注意在取消索引操作时,inplace=True 设置为 True,以便后面可以查看到取消后的情况
d.reset_index(inplace=True) 重复值处理
# 查找重复值,subset参数指定列
print('>>>\n', df_1.duplicated(subset=['年份'], keep='first').head())
# 删除重复值,keep是删除第一次出现的重复值
print('>>>\n', df_1.drop_duplicates(subset=['年份'], keep='first', inplace=False).iloc[:, :4])
# 查找重复索引
print('\n>>>', df_1.index.duplicated())query函数(类似where)
df.query('列名 判断 值'),如df.query('column1 > 2 and column 2<1')
等于
df[df[列名] 判断 值],如 df[df[column1]>2 & df[column2]<1]filter函数
# DataFrame.filter(items=None, like=None, regex=None, axis=None)
#items对列进行筛选#regex表示用正则进行匹配#like进行筛选#axis=0表示对行操作,axis=1表示对列操作
# 选择指定的列,类似于 df[['某列', '某列']]
df_1.filter(items=['地区', '年份']) # 选择指定的列
df_1.filter(like='产业', axis=1) # 选择(含有) "产业" 的列
数据透视表
# 第一个参数data表示我们要传入的数据,index表示索引,columns表示行名称,aggfunc表示要进行的操作
pd.pivot_table(detail[['订单id','菜品名称','下单数量']],index='订单id',colomns='菜品名称',aggfunc='sum')
# aggfunc默认是均值mean
pd.pivot_table(detail[['订单id','菜品名称','下单数量']],index='订单id',colomns='菜品名称',values='counts',fill_value=0)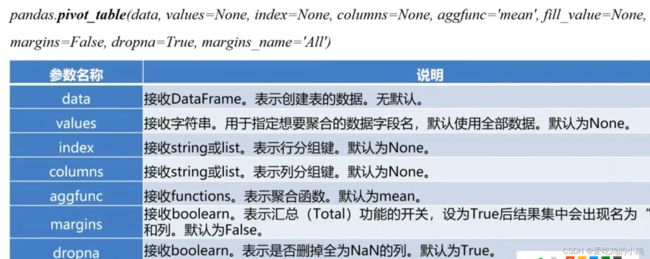
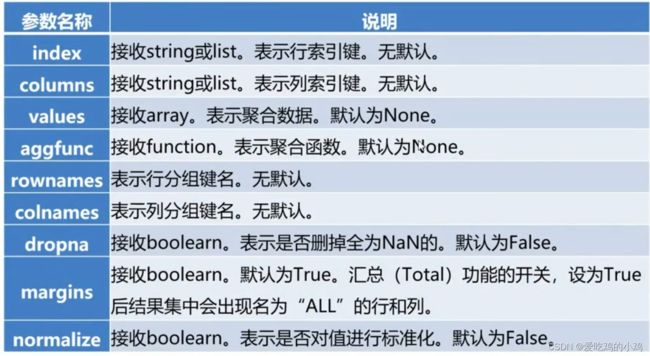
创建交叉表
# index指定索引,columns指定行名称,values指定数据,aggfunc指定进行什么操作,因为没有fill_value参数
pd.crosstab(idnex=detail['订单id'],columns=detail['菜品名称'],values=detail['下单数量'],aggfunc='sum').fillna(0)
使用unstack和pivot实现数据二维透视
# 分组之后的数据df_group
df_group.unstack()
# 执行上面操作之后还原原来格式
df_group.stack()
# 参数x,y,数据
df_reset.pivot("pdate","Rating","pv")
cut分组等级
pd.cut(fh_data['总无机养分百分比'],bins=10,labels=group_names)