ICLR 2022 | 目标检测新坑来了!谷歌Hinton团队提出Pix2Seq:基于Transformer的检测新工作...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自丨极市平台 作者丨happy
导读
语言模型与目标检测这种八竿子打不着的领域之间会存在关联性吗?Hinton团队的最新工作Pix2Seq对此进行了探索,它将目标检测问题转换成了语言模型问题,并在COCO数据集上取得了与DETR相当甚至更优性能。好大的脑洞!
Pix2seq: A Language Modeling Framework for Object Detection
原文链接(已收录于ICLR 2022):
https://arXiv.org/abs/2109.10852
https://openreview.net/forum?id=e42KbIw6Wb
Abstract
本文提出了一种简单而通用框架Pix2Seq用于目标检测,不同于已有显式集成先验知识的方案,我们将目标检测任务转换成了基于观测像素输入的语言模型任务 。关于目标的描述(比如边框、类别)将被描述为离散token序列,我们训练了一个神经网络去感知图像并生成期望的序列。
该方法主要基于这样的直觉:如果神经网络知道目标在哪、目标是什么,那么我们仅需要教它如何进行解析 。除了实用任务相关数据增广外,该方法对任务做了最小假设,相比高度优化的检测方案,所提方法在COCO数据集上取得了极具竞争力的结果。

Method

正如前面所提到,Pix2Seq将目标检测任务转换为基于像素输出的语言模型任务。如上图所示,该方案包含四个主要成分:
图像增广 :正如其他CV模型一样,我们采用图像增广提升训练集的样本丰富,比如随机缩放、随机裁剪;
序列构建与增广 :由于图像中的目标标注通常为边框与类别集合,因此我们将其转换为离散token序列;
网络架构 :我们采用了编码-解码架构,其中编码器用于感知像素输入,解码器用于生成目标序列;
损失函数 :模型通过最大化token的对数似然进行训练。
Sequence Construction from Object Descriptions
在常规目标检测数据(比如Pascal VOC,COCO以及OpenImages)中,图像往往包含可变数量的目标,每个目标通过边框与类别标签表示。在Pix2Seq中,我们将其表示为离散token序列。
类别标签天然的可以表示为离线token,但边框不行。边框可以通过两个角点(比如左上、右下两个角点)确定,或者通过中心加宽高。我们对角点的坐标进行离散化,具体来说,目标将被表示为五个离散token序列
402 Payment Required
,每个连读角点坐标被均匀离散化到整数 ,c为类别索引 。我们对所有目标采用共享词表(vocabulary),故此表大小等于bins数+类别数。这种量化机制使得我们可以使用较小的词表取得高精度。比如, 大小图像仅需600bins即可达到零量化误差,这远小于32K词表的语言模型。下图给出了不同水平量化对于边框的影响。
在前面内容中,我们将目标的描述转换为短离散序列,接下来,我们对多目标描述序列化以构建给定图像的单序列。由于目标的顺序不会对检测任务产生影响,我们采用了随机顺序策略 。我们同样探索了其他确定性顺序策略,但两者性能相当。

由于不同图像通常包含不同数量的目标,所生成的序列具有不同的长度。为指示序列结尾,我们引入了EOS词 。上图给出了不同顺序策略下的序列构建过程。
Architecture, Objective and Inference
前面完成了目标描述的转换,接下来,我们将转向架构、损失函数的构建。
Architecture 我们采用编码器-解码器架构 ,编码器是一种广义图像编码器(ConvNet、Transformer或者两者组合):它对像素进行感知并编码为隐表达。对于生成器部分,我们采用语言模型中常用的Transformer解码器:它一次生成一个token。这种方式消除了已有目标检测器架构的复杂性与定制化功能,比如bbox proposal、regression等。
Objective 类似语言模型,Pix2Seq将用于预测token,给定图像与之前的token,最大化似然损失:
402 Payment Required
其中,x表示输入图像,表示输入与目标序列,L表示目标序列长度。
Inference 在推理阶段,我们从中进行token采样,此时可以选用具有最大似然的token、或者其他随机采样技术。我们发现:nucleus采样具有更高的召回率 。当生成EOS这个token后,序列结束,然后对所的序列进行反量化转换为目标。
Sequence Augmentation to Integrate Task Priors
EOS的存在允许模型自己决定何时停止生成token,但实际上我们发现:模型倾向于提前停止,导致无法预测所有目标 。原因可能有一下两个:
标注噪声,比如标注者没有标注所有目标
某些目标的不确定性
由于召回率与准确率对目标检测均非常重要,为得到更高召回率,一个可能的技巧:通过人工降低似然延迟EOS的采样。然而,这会误检、重复检测问题。
由于所提方案的任务不可知性,很难对精度-召回率进行均衡调整。为缓解该问题,我们引入了一种序列增广技术,集成关于任务的先验信息 。传统自回归语言模型中的目标序列与输入序列相同;经过序列增广后,我们不仅对输入序列进行增广,同时还对目标序列进行修改使其能辨别噪声token。这种处理方式可以有效提升模型的鲁棒性。下图给出了所提序列增广示意图。
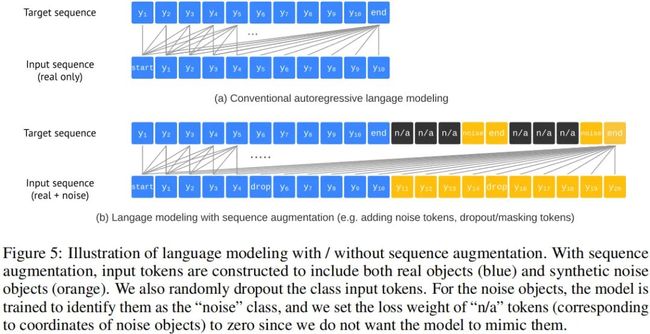
Altered Sequence Construction 我们首先通过如下两种方式构建合成噪声目标以增广输入序列:
对已有真实目标添加噪声,如边框随机缩放与移位;
生成随机边框与随机类别标签。

上图给出了合成噪声目标示意图,可以看到:合成噪声目标与真实目标会存在重叠。完成噪声目标合成与离散化后,我们将其添加到原始输入序列尾部;对于目标序列,我们设置噪声目标的目标token为noise类、坐标token为n/a,对应的损失权值为0,即 。
Altered inference 基于上述序列增广,我们可以极大的延迟EOS词的生成,提升召回率且不会提升噪声/重复预测。我们让模型预测最大长度序列,生成定长目标列表。然后,我们从生成的目标序列中提取边框与类别信息,采用最大似然真实类别标签替换noise类别标签。
Experiments
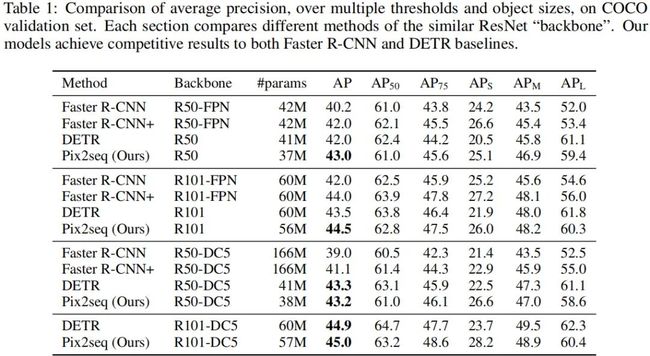
上表给出了所提方案与DETR、Faster R-CNN在COCO数据集上的性能对比,从中可以看到:
所提Pix2Seq取得了与基线方案相当的结果 ;
相比Faster R-CNN,所提Pix2Seq在小目标与中目标检测方面性能相当,但在大目标检测方面更优;
相比DETR,所提Pix2Seq在大/中目标检测方面相当或稍差,但在小目标检测方面更优,高4-5AP。
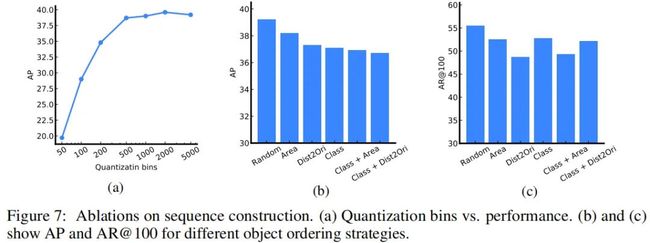
上图a比较了坐标量化对于性能的影响,结果表明:500bins量化足矣 。
上图b和c比较了不同目标顺序策略的性能对比,结果表明:随机顺序具有最佳性能 。
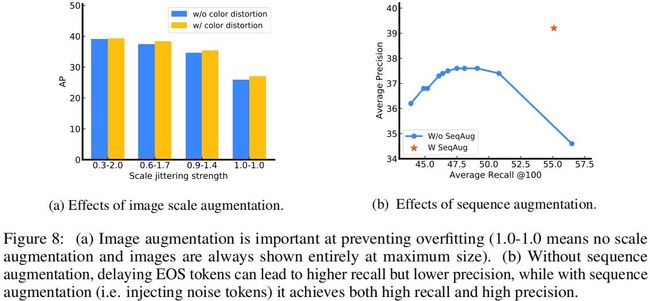
上图a比较了图像增广的性能影响,结果表明:使用不合适的增广时,模型会出现过拟合 。更强的图像增广可能会带来更好的性能提升。
上图b比较了序列增广的性能影响,结果表明:不使用序列增广时,随AR提升,AP出现了大幅下降;而使用了序列增广后,模型具有更好的AR-AP均衡 。

全文到此结束,更多消融实验与分析建议查看原文。
Pix2Seq论文下载
后台回复:Pix2Seq,即可下载上述论文ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看