目标检测再次革新!图灵奖得主团队提出Pix2Seq,将Detection变成了Image Captioning...
关注公众号,发现CV技术之美
▊ 写在前面
本文提出了一种简单通用的目标检测框架Pix2Seq。与目前显式地集成了关于检测任务的先验知识的方法不同,本文的方法简单地将目标检测转换为以像素输入为条件的语言建模任务 。对象描述(检测框和类别标签)被表示为离散的token序列,并且作者通过训练神经网络来感知图像并生成所需的序列。
作者认为:如果神经网络知道目标在哪里以及目标是什么,那么只需要教模型如何“ 读出 ”它们 。除了使用特定于任务的数据增强,本文的方法对任务做了最少的假设,但与高度专业化和优化良好的检测算法(Faster R-CNN、DETR)相比,它在COCO数据集上获得了不错的结果。
▊ 1. 论文和代码地址

Pix2seq: A Language Modeling Framework for Object Detection
论文地址:https://arxiv.org/abs/2109.10852
代码地址:未开源
▊ 2. Motivation
目标检测的目标是识别和定位图像中所有预定义类别的对象。检测到的对象通常由一组边界框和相关联的类别标签来描述。鉴于任务的难度,大多数现有的方法都是使用精心设计和高度定制的框架,在模型结构和损失函数的选择方面需要大量的先验知识,比如NMS、ROI Pooling等等。
尽管目标检测在无数领域都有应用,从自动驾驶到医学图像分析,再到农业病害虫检测,但专业化和复杂性使它们难以集成到更大的系统中,或推广到的更广泛的任务。
作者认为:如果神经网络知道对象在哪里以及对象是什么,那么我们只需要教它读出它们(即语言生成任务) 。通过学习“描述”对象,模型可以在像素观察的基础上,学习“语言”的生成,从而产生有用的对象表示。
这是本文的Pix2Seq框架的思想:给定一幅图像,本文的模型生成一系列离散的token,这些token对应于对象描述(边界框和类别标签),这就很类似于Image Captioning任务(Image Captioning任务就是输入一张图片,然后让模型用语言描述这个图片内容;这里只不过是把语言换成了边界框和类别标签的token) 。
从本质上讲,作者把目标检测看作是一个以像素输入为条件的语言建模任务,其模型结构和损失函数都是通用的,并且相对简单,并不是专门为检测任务设计的。因此,人们可以很容易地将该框架扩展到不同的领域或应用,从而为广泛的视觉任务提供语言接口。
为了能够用Pix2Seq来进行检测任务,作者首先提出了一种量化和序列化方案,将检测框和类标签转换为离散的token序列。然后,作者利用编码器-解码器架构来感知像素输入并生成目标序列。目标函数是以像素输入和前面的token为条件的最大似然。通过广泛的实验,作者证明了与高度定制的方法(Faster R-CNN,DETR)相比,这个简单的Pix2Seq框架可以在COCO数据集上实现性能相当的结果。
▊ 3. 方法

Pix2Seq将目标检测作为一项语言建模任务,以像素输入为条件,输出相应目标的坐标和类别信息,如上图所示。

Pix2Seq的结构和学习过程有四个主要部分,如上图所示:
图像增强(Image Augmentation) :作者使用图像增强来丰富一组固定的训练样本(例如,使用随机缩放和裁剪)。
序列构造和增强(Sequence construction & augmentation) :目标检测数据中的目标通常用检测框和类别标签来表示,作者在Pix2Seq中将其表示为一些离散token的序列,并在训练过程中对其进行了增强。
结构(Architecture) :作者使用编码器-解码器结构,其中编码器用来感知像素输入,解码器用于生成目标序列。
目标函数(Objective/ function): 该模型的训练目标是最大化以图像和之前的token为条件的token对数似然。
3.1. 根据对象描述构建序列
在目标检测数据集中,图像具有可变数量的对象,表示为检测框和类别标签的集合。在Pix2Seq中,作者将它们表示为离散token序列。虽然类标签自然地表示为离散token,但检测框不是。检测框由两个角点(即左上角和右下角)确定,或者由中心点加上高度和宽度确定。
因此,作者提出将用于指定角点的x,y坐标的连续数字离散化。具体地说,对象被表示为五个离散token的序列,即,,,,,其中每个连续的角坐标被均匀离散为,之间的整数,c是类索引。
作者对所有token使用共享词汇表,因此词汇表大小等于+类别数。这种用于边界框的量化方案使得模型在实现高精度的同时使用较小的词汇量(下图显示了不同下的检测结果)。
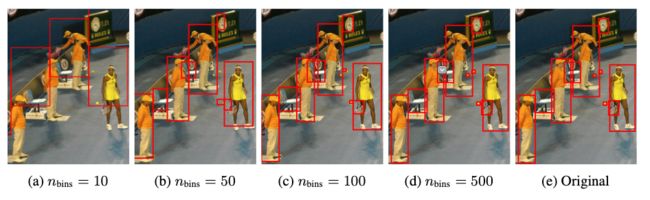
由于每个对象描述都表示为一个简短的离散序列,接下来需要序列化多个对象描述,以形成给定图像的单个序列。由于图像中目标框的顺序对于检测任务本身并不重要,因此作者使用随机排序策略来生成给定图像的序列。此外,作者还探索了其他确定性排序策略,但作者认为,给定一个强大的神经网络,随机排序应该与任何确定性排序策略效果是类似的。
3.2. 架构、目标及推理
Architecture
作者使用编码器-解码器架构。编码器可以是感知像素并将其编码成隐藏表示的通用图像编码器,例如ConvNet、Transformer或是他们的组合结构。对于解码器结构,由于是生成任务,作者选用了在语言模型中广泛使用的Transformer decoder。这种结构消除了目标检测结构中的复杂性和定制化,例如region proposal和回归。
Objective
与语言建模类似,在给定图像和之前的token的情况下,Pix2Seq被训练生成预测具有最大似然损失的token:
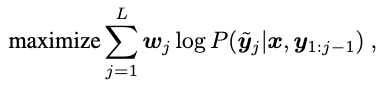
其中为输入的图像,和为输入和目标的序列。L为目标序列的长度。是序列中第j个token的预先分配的权重。在本文中,作者设置,,然而,也可以根据它们的类型(例如,坐标与类别)或通过相应对象的大小来对token进行加权。
Inference
在推理时,作者从模型似然,即,:中采样token。这可以通过采样可能性最大的token(即,Argmax)或使用其他随机采样技术来实现。序列在生成EOS token时结束。
3.3. 序列增强
EOS token允许模型决定何时终止生成,但在实验中,作者发现模型往往在没有预测所有目标的情况下结束。这可能是由于两方面的原因:1)标注噪声2)在识别或定位某些对象时的不确定性。
由于召回率和精确度对于目标检测都很重要,如果没有良好的召回率,模型就不能实现好的整体性能(例如,平均精确度)。为了鼓励模型具有更高的召回率,一个trick是通过人为降低EOS token的可能性来延迟EOS token的采样。然而,这往往会导致重复的预测。
在一定程度上,这种在精确度和召回率之间进行权衡困难的原因是,本文的模型是任务不可知的。为了缓解这个问题,作者引入了一种序列增强技术 ,从而合并了关于该任务的先验知识。自回归语言建模中的目标序列通常与输入序列相同,并且序列中的所有token都是从真实标注转换而来的。
在本文中,作者在训练期间增强了输入序列 ,使之包括真实和合成噪声token。此外,作者还修改了目标序列 ,以便模型可以学习识别噪声token,而不是模仿它们。这提高了模型对噪声和重复预测的鲁棒性,如下图所示:

Altered sequence construction
首先创建合成的噪声对象(synthetic noise objects) 来增强输入序列,主要有以下两种方式:
1)向现有Ground Truth对象添加噪声(例如,随机缩放或移动边界框等);
2)生成完全随机的框,并随机关联的类标签。

这些噪声框可能和现有的ground truth目标框是有重叠甚至相同的,如上图所示。在合成和离散化噪声对象之后,作者将它们附加到原始输入序列的末尾。对于目标序列,作者将噪声对象的目标token设置为“Noise”类(即,不属于任何ground truth分类标签),将噪声对象的坐标token设置为“n/a”,其损失权重设置为零。
Altered inference
通过序列增强,能够大幅延迟EOS token,并在不增加噪声和重复预测频率的情况下提高召回率。因此,作者让模型预测到最大长度,从而产生固定大小的对象列表。当从生成的序列中提取边界框和类标签的列表时,作者用在所有真实类标签中具有最高似然的真实类标签来替换“噪声”类标签。
▊ 4.实验
4.1 结果对比

上表显示了用ResNet作为Backbone时,不同模型的结果。可以看出看出,本文的方法在小目标和中等目标的检测上比Faster R-CNN好。
4.2 序列构造的消融
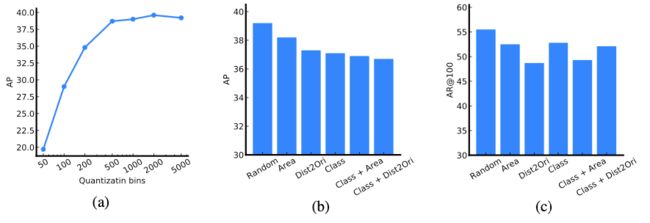
上图(a)显示了不同的结果,可以看出就能达到已经比较好的结果了。上图(b)和(c)分别显示了不同排序策略下,Top-100预测的average precision和average recall。
4.3 增强部分的消融

上表显示了有无图像和序列增强下的实验结果。
4.4 解码器cross attention map的可视化

上图显示了解码器在预测前5个对象时的cross attention map。
▊ 5. 总结
在本文中,作者提出了Pix2Seq,一个简单而通用的目标检测框架。通过将目标检测转换为语言建模任务,Pix2Seq极大地简化了目标检测的pipeline,消除了目前检测算法中的大部分特定于任务的手工设计。
虽然它在具有COCO数据集上已经取得了与baseline相当结果,但训练过程仍然可以优化以提高其性能。作者认为,本文提出的Pix2Seq框架不仅适用于目标检测,还可以应用于其他的视觉任务,输出可以表示为相对简洁的离散token序列。
继DETR之后,目标检测范式又一次被革新,这个过程,为目标检测专门设计的模块被一步步的移除,如nms、RoI Pooling,使得目标检测能够用一种更加通用的范式来处理。大大简化了训练的流程。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「目标检测」交流群备注:OD
