sklearn实现Adaboost算法(分类)
阿喽哈~小天才们,今天我们聊一聊Adaboost
上一篇文章我们说了如何去实现随机森林,随机森林是集成学习中bagging算法的代表作,感兴趣的童鞋请移步sklearn实现随机森林(分类算法)
今天要说的Adaboost算是boosting中比较元老级别的算法了,我们先来说说boosting算法的特点吧
- 它和bagging算法不同,boosting是通过降低整体的偏差来降低泛化误差,因此被称为提升法
- 相对于bagging,boosting算法在原理和操作上难度都更大
- 由于boosting算法专注于降低与真实值之间的偏差,因此boosting在模型效果上表现突出
Adaboost(Adaptive Boosting, 自适应增强)是较为早期的boosting算法,所以他的构筑过程相对于其他boosting算法来说都是较为简单直观的,如果你不能够透彻地理解gbdt或是xgboost的原理,可以先从Adaboost入手,懂弄了之后再去看更复杂的集成算法,可能就不会很困难啦
Adaboost的算法原理如下:
- 基于全部样本建立一颗决策树
- 根据第一颗决策树的预测结果与真实值之间的偏差,增加被预测错误的样本在原数据集中的权重,并让加权后的全部样本作为下一颗决策树的训练样本
- 用加权后的数据建立第二颗树,查看第二棵树被预测错误的样本,根据这个结果修正样本权重用于第三棵树
- 一直循环上述过程,直到预测误差小于设定的阈值内,终止迭代,停止生成树
在理解Adaboost算法的时候,有两点需要注意的地方哦:①和随机森林不同,Adaboost不进行样本和特征的抽样,会用全部样本和特征来建立每一个基学习器;②整个算法过程中涉及两个权重的迭代更新,一个是样本权重,根据每轮基学习器的预测结果,增加预测错误样本对应的权重,实质上就是我们在建立下一个基学习器时,会更重视上一轮被预测错误的样本,尽量避免它在这一轮又被预测错误,以此来不断修正错误,进而我们的集成所有的基学习器后,正确率就会高很多,还有一个权重是每一个基学习器的权重,这个权重由每一个基学习器的分类误差率决定,分类误差率越低,基学习器的权重越高,说白了就是能力越大责任越大,预测的准的基学习器就给它话语权,它说了算
具体算法公式啥的大家就自行学习理解叭,我们今天主要是说如何使用sklearn包来实现Adaboost以及简单的调参演示,话不多说上代码~
1、导入各种包
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import OrdinalEncoder
from sklearn import metrics
from sklearn.metrics import roc_curve, auc
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn import ensemble
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
import graphviz
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 242、数据读取
为了方便大家代码复现,本次使用的是python自带的泰坦尼克号数据集,共981个样本,特征涉及性别、年龄、船票价格、是否有同伴等等,标签列有两个,分别是‘survived’和‘alive’,都表示该乘客是否生还,所以我们取一列就可以了
data = sns.load_dataset('titanic') # 导入泰坦尼克号生还数据
data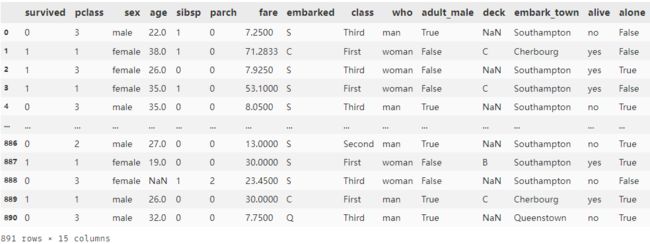
3、数据预处理
首先进行数据的预处理,首先可以看到‘deck’列存在缺失值,我们可以看看总体数据缺失的情况
data.replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True) # 把各类缺失类型统一改为NaN的形式
data.isnull().mean()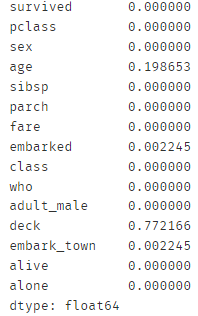
共4列数据存在缺失值,‘deck’缺失率超过70%,予以删除,剩余特征的缺失值使用其均值或是众数进行填补
细心地童鞋可能发现了有好几列重复的特征,‘embarked’和‘embark_town’都表示出发港口,‘sex’、‘who’、‘adult_male’都表示性别,‘pclass’和‘class’都是船票类型,‘sibsp’和‘alone’都表示是否有同伴,对于这几个特征,所以我们保留其中一个就可以了
del data['deck'] # 删除‘deck’列
del data['who']
del data['adult_male']
del data['class']
del data['alone']
data['age'].fillna(np.mean(data.age), inplace=True) # 年龄特征使用均值对缺失值进行填补
data['embarked'].fillna(data['embarked'].mode(dropna=False)[0], inplace=True) # 文本型特征视同众数进行缺失值填补
x = data.drop(['alive', 'survived', 'embark_town'], axis=1) # 取出用于建模的特征列X
label = data['survived'] # 取出标签列Ysklean中的Adaboost算法是无法进行字符串的处理的,所以要先进行数据编码,这里我们就使用最简单的特征编码,转化完毕后特征全部变为数值型
oe = OrdinalEncoder() # 定义特征转化函数
# 把需要转化的特征都写进去
x[['sex', 'embarked']] = oe.fit_transform(x[['sex', 'embarked']])
x.head()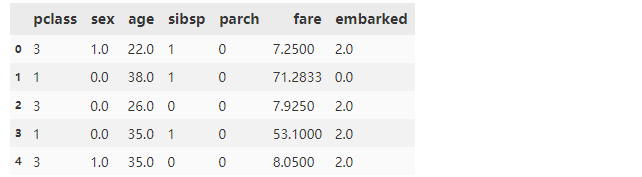
# 划分训练集、测试集
xtrain, xtest, ytrain, ytest = train_test_split(x, label, test_size=0.3)4、训练模型
"""
slearn封装的Adaboost及其参数
sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
"""这里同时训练了Adaboost分类模型和随机森林分类模型,用于对比模型效果
rfc = RandomForestClassifier(class_weight='balanced', random_state=37) # 随机森林
rfc = rfc.fit(xtrain, ytrain)
score_r = rfc.score(xtest, ytest)
abc = AdaBoostClassifier(random_state=37) # adaboost
abc = abc.fit(xtrain, ytrain) # 拟合训练集
score_a = abc.score(xtest, ytest) # 输出测试集准确率
print("随机森林:{}".format(score_r), " adaboost:{}".format(score_a))![]()
从准确率这个指标来看,随机森林略胜一筹,但毕竟是分类问题,我们再使用AUC来评估模型,看一看是否随机森林效果更好
y_test_proba_rfc = rfc.predict_proba(xtest)
false_positive_rate_rfc, recall_rfc, thresholds_rfc = roc_curve(ytest, y_test_proba_rfc[:, 1])
roc_auc_rfc = auc(false_positive_rate_rfc, recall_rfc) # 随机森林AUC指标
y_test_proba_abc = abc.predict_proba(xtest)
false_positive_rate_abc, recall_abc, thresholds_abc = roc_curve(ytest, y_test_proba_abc[:, 1])
roc_auc_abc = auc(false_positive_rate_abc, recall_abc) # adaboost AUC指标
# 画出俩模型对应的ROC曲线
plt.plot(false_positive_rate_rfc, recall_rfc, color='blue', label='AUC_rfc=%0.3f' % roc_auc_rfc)
plt.plot(false_positive_rate_abc, recall_abc, color='orange', label='AUC_abc=%0.3f' % roc_auc_abc)
plt.legend(loc='best', fontsize=15, frameon=False)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()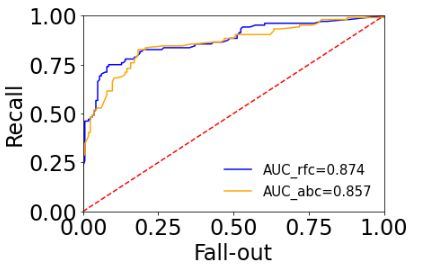
蓝色实线为随机森林的ROC曲线,黄色实线为Adaboost的ROC曲线,从AUC指标评估模型的话,随机森林效果是要更好的,而且AUC指标对于分类模型的评估还是很公平有效的
5、调参
这里设定Adaboost的基学习器为决策树,最大深度为2,当然你也可以设为别的分类算法,通过参数base_estimator进行设置,集成算法最重要的俩参数就是基学习器数量n_estimators和学习率learning_rate,这里我们就通过调整这两个参数来提升模型效果
网格搜索类似枚举法,把要调整的参数和参数范围设置完毕之后,它可以进行参数组合,找到模型效果最佳的模型组合,当需要调整的参数较多或参数范围很广时,网格搜索就会非常慢,有利有弊叭,所以一般的调参可以先手动调一调,找到参数大致的最优范围,再通过网格搜索去准确定位最优参数值
# 通过网格搜索法选择合理的Adaboost算法参数
n_estimators = [10, 100, 200, 300, 400, 500, 600]
learning_rate = [0.01, 0.1, 0.2, 0.3, 0.4, 0.5]
params2 = {'n_estimators':n_estimators,'learning_rate':learning_rate}
adaboost = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2),
algorithm="SAMME", random_state=37),
param_grid= params2, scoring = 'roc_auc', cv = 5, n_jobs = 10, verbose = 1)
adaboost.fit(xtrain, ytrain)
print('best_params_:', adaboost.best_params_) # 返回参数的最佳组合和对应AUC值
print('best_score_:', adaboost.best_score_)
这里给出的最佳参数为100个基学习器搭配0.2的学习率,AUC达到0.86,那我们就认为这是最佳的参数组合,带入模型看看效果
abc = ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2),
n_estimators=100, learning_rate=0.2, algorithm="SAMME", random_state=37)
abc = abc.fit(xtrain, ytrain)
y_test_proba_abc = abc.predict_proba(xtest)
false_positive_rate_abc, recall_abc, thresholds_abc = roc_curve(ytest, y_test_proba_abc[:, 1])
auc(false_positive_rate_abc, recall_abc) ![]()
带入模型后可以看到AUC值为0.87,和刚才的0.86并不相同,因为我们在调参时,设置了CV=5,就是使用了5折交叉验证,把数据分为五份,每一份都去训练评估得到一个AUC值,而这个0.86就是这5个AUC值得均值,后面把调参出来的组合带入模型后,使用的是原始的训练集合测试集,一般来说得到的AUC值都会产生波动,高点或者低点都是很正常的
6、查看模型各类属性
前面我们简单说了Adaboost的算法原理,涉及两个权重,一个是样本权重,一个是基学习器的权重,这两个都是可以看的
#特征重要性
feature_name = x.columns
abc.feature_importances_
[*zip(feature_name,abc.feature_importances_)]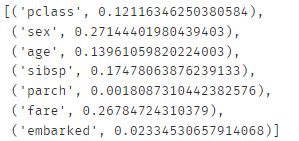
# 基学习器权重
abc.estimator_weights_ 
基学习器的权重这里我只截取了部分,有多少个基学习器就有多少个权重,都是一一对应的
Adaboost和随机森林一样,都可以画出决策树,但只能一棵树一棵树地画
plt.figure(figsize = (15,8)) # 设置画图参数
_ = tree.plot_tree(abc[88]) # 画出第87个基学习器
abc.estimators_[88].feature_importances_ # 查看第87颗树对应的特征重要性 
从树的构成可以看出来,第87颗树只用到了第三、第四这两个特征,所以其对应的特征重要性也就只有这两个特征有数值的
本人才疏学浅,若有理解有误的地方,还请各路大佬批评指正♡♡♡
ok!感恩的心~