《Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning》译文
原文链接 https://arxiv.org/pdf/1709.10082v1.pdf
Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning
这个上面图片好像是传失败了,可以去这个链接下载,包含了论文原文、翻译、以及实现代码
https://download.csdn.net/download/circleyuanquan/12423287?spm=1001.2014.3001.5501
翻译:
摘要-在分散的场景中,为多个机器人开发一个安全有效的碰撞避免策略是一个挑战,在这种场景中,每个机器人生成其路径而不观察其他机器人的状态和意图。当其他分布式多机器人避碰系统存在时,往往需要提取代理级特征来规划局部无碰撞动作,这在计算上是令人望而却步的,而且不具有鲁棒性。更重要的是,在实践中,这些方法的性能远远低于它们的集中式方法。针对多机器人系统,提出了一种分散的传感器级碰撞避免策略,该策略将原始传感器测量值直接映射到代理的运动速度方向指令。作为减少分散和集中方法之间性能差距的第一步,我们提出了一个多场景多阶段训练框架来学习最优策略。利用基于策略梯度的强化学习算法,在丰富复杂的环境下对大量机器人同时进行策略训练。通过深入的性能评估,验证了所学习的传感器级碰撞避免策略在各种模拟场景中的有效性,并证明了所学习的策略能够为大型机器人系统找到时间效率高、无碰撞的路径。我们还证明了所学习的策略可以很好地推广到新的场景中,这些场景在整个训练期间不会出现,包括导航一组异构的机器人和一个包含100个机器人的大规模场景。视频可在https://sites.google.com/view/drlmaca上获取。
I. INTRODUCTION
近来,多机器人导航已引起人们对机器人技术和人工智能的极大兴趣,并具有许多实际应用,包括多机器人搜索和救援,人群中的导航以及自动仓库。多机器人导航的主要挑战之一是为每个从起始位置导航到期望目标的机器人制定安全可靠的防撞策略。
先前的一些工作(称为集中式方法)假设为中央服务器提供了有关所有座席意图(例如初始状态和目标)及其工作区(例如2D网格图)的全面知识,以控制座席的行为。这些方法可以通过同时计划所有机器人的最佳路径来生成防撞动作。但是,这些集中式方法很难扩展到具有许多机器人的大型系统,并且当需要频繁地重新分配任务/目标时,它们的性能可能会很差。此外,实际上,它们严重依赖机器人与中央服务器之间的可靠通信网络。因此,一旦中央服务器和/或通信网络发生故障,多机器人系统将崩溃。此外,当在未知且非结构化的环境中部署多个机器人时,这些集中式方法将不适用。
与集中式方法相比,一些现有的工作提出了代理级分散式冲突避免策略,其中每个代理独立考虑其他代理的可观察状态(例如形状,速度和位置)作为输入来做出决策。大多数座席级策略基于速度障碍(VO)[1] – [5],并且它们可以为杂乱工作区中的多个座席有效地计算局部无碰撞动作。但是,一些限制极大地限制了它们的应用。首先,基于仿真的工作[1],[6]假设每个代理对周围环境都有完美的感知,由于无处不在的感知不确定性,在现实世界中这种情况并不成立。为了缓解完美感测的局限性,以前的方法使用全球定位系统来跟踪所有机器人的位置和速度[2],[5],或设计一种智能体间通信协议以在附近的智能体之间共享位置和速度信息[3]。 ],[4],[7]。但是,这些方法将外部工具或通信协议引入到多机器人系统中,这可能不够鲁棒。其次,基于VO的策略具有许多对方案设置敏感的可调参数,因此必须离线仔细地设置参数以实现令人满意的性能。最后,就导航速度和导航时间而言,以前的分散方法的性能明显低于集中式方法。
受基于VO的方法启发,Chen等人。 [8]运用深度强化学习训练了一个Agent级别的避免冲突策略,该策略学习了一个两Agent值函数,该函数将Agent的自身状态及其邻居的状态显式映射到无碰撞行为,而它仍然需要完美的感知。在他们的后续工作[9]中,部署了多个传感器来执行分割,识别和跟踪的任务,以便估计附近人员和移动障碍物的状态。但是,这种复杂的管道不仅需要昂贵的在线计算,而且会使整个系统对感知不确定性的鲁棒性降低。
在本文中,我们专注于传感器级别的分散式碰撞避免策略,这些策略直接将原始传感器数据映射到所需的无碰撞转向命令。与代理程序级策略相比,不需要对相邻代理程序和障碍物进行完美感知,也不需要针对不同情况进行离线参数调整。传感器级别的冲突避免策略通常由深度神经网络(DNN)[10],[11]建模,并在大型数据集上使用监督学习进行训练。但是,在监督下学习策略存在一些局限性。首先,它需要大量的训练数据,这些数据应涵盖多个机器人的不同种类的交互情况。其次,在交互场景中不能保证数据集中的专家轨迹是最优的,这使得训练很难收敛到一个可靠的解决方案。第三,难以手动设计适当的损失函数来训练鲁棒的碰撞避免策略。为了克服这些缺点,我们提出了一种多场景多阶段深度强化学习框架,以使用策略梯度法学习最优的避免碰撞策略。
主要结果:在本文中,我们解决了在完全分散的框架中避免多个机器人发生碰撞的问题,在该框架中,仅从机载传感器收集输入数据。为了学习最佳的避免碰撞策略,我们提出了一种新颖的多场景多阶段训练框架,该框架利用了在一组复杂环境中在大型机器人系统中训练的基于鲁棒策略梯度的强化学习算法。我们证明,从所提出的方法中学到的避免碰撞策略能够为大型非完整机器人系统找到时间高效,无碰撞的路径,并且可以很好地推广到看不见的场景。它的性能也比以前的分散方法好得多,并且可以作为缩小集中式和分散式导航策略之间差距的第一步。
 正在上传…重新上传取消
正在上传…重新上传取消
图1:使用我们学习到的策略的圆形场景中的机器人轨迹。注意,机器人是方形的。在这种情况下,直接对圆盘机器人训练的策略进行测试,表明所学习的策略具有良好的泛化能力。
II. RELATED WORK
基于学习的碰撞避免技术已经被广泛地研究于一种避免静态障碍的机器人。许多方法都采用有监督的学习范例,通过模仿传感器输入和运动命令的数据集来训练碰撞避免策略。穆勒等。文献[12]通过训练6层卷积网络将监督的基于视觉的静态障碍物避免系统训练为移动机器人,该6层卷积网络将原始输入图像映射到转向角。张等。 [13]利用基于后继特征的深度强化学习算法将先前掌握的导航任务中学习的深度信息传输到新的问题实例。警长等。 [14]提出了一种基于多模式深度自动编码器的移动机器人控制系统。罗斯等。 [15]用模仿学习技术训练了一个小型四旋翼直升机的离散控制器。四旋翼机仅使用一台廉价摄像机就能成功避免与环境中的静态障碍物发生碰撞。是,仅需学习离散运动(左/右),并且仅在静态障碍物内训练机器人。注意,上述方法仅考虑了静态障碍物,并且要求驾驶员在各种各样的环境中收集训练数据。 Pfeiffer等人提出了另一种数据驱动的端到端运动计划器。 [11]。他们使用ROS导航软件包生成的专家演示训练了模型,将激光测距结果和目标位置映射到运动命令。该模型可以在以前看不见的环境中导航机器人,并成功地应对突然的变化。但是,类似于其他监督学习方法,学习策略的性能受到标记训练集质量的严重限制。为了克服这个限制,Tai等。 [16]提出了一种通过深度强化学习方法训练的无地图运动计划器。卡恩等。 [17]提出了一种基于不确定性模型的增强学习算法来估计先验未知环境中的碰撞概率。但是,测试环境相对简单且结构化,学习过的计划人员很难将其推广到具有动态障碍和其他主动代理的场景。
关于多智能体碰撞避免,最优交互碰撞避免(ORCA)框架[1]在人群仿真和多智能体系统中很流行。 ORCA为多个机器人提供了充分的条件,可以避免在短时间内相互碰撞,并且可以轻松扩展以应对具有多个机器人的大型系统。 ORCA及其扩展[2],[5]使用启发式或第一性原理构建了避免碰撞策略的复杂模型,该模型具有许多繁琐且难以正确调整的参数。此外,这些方法对现实世界中普遍存在的不确定性很敏感,因为它们假定每个机器人都具有对周围特工的位置,速度和形状的完美感知。为了减轻对完美感知的需求,[3],[4],[7]引入了通信协议以共享状态信息,包括组中特工的位置和速度。而且,ORCA的原始公式是基于完整的机器人,在现实世界中这种机器人比非完整的机器人要少见。为了在最常见的差动驱动机器人上部署ORCA,已经提出了几种方法来解决非完整机器人运动学的难题。 ORCADD [18]将机器人扩大到原始尺寸半径的两倍,以确保在不同约束条件下机器人的碰撞路径畅通无阻。但是,这种扩大的虚拟机器人尺寸可能导致狭窄通道或非结构化环境中的问题。 NH-ORCA [19]使差动驱动机器人以一定的跟踪误差ε跟踪完整的速度矢量。它比ORCA-DD更可取,因为机器人半径的虚拟增加仅是ε的大小,而不是半径的两倍。
在本文中,我们专注于学习一种避免碰撞的策略,该策略可以使多个非完整的移动机器人导航到其目标位置,而不会在复杂复杂的环境中发生碰撞。
正在上传…重新上传取消
图2:我们方法的概述。在每一个时间步,每个机器人从环境中接收其对地面的观察和回报,并在遵循策略π时生成一个动作。策略π在所有机器人之间共享,并通过基于策略梯度的强化学习算法进行更新。
III. PROBLEM FORMULATION(问题表述)
多机器人避碰问题主要是在欧氏平面上有障碍物的非完整差分驱动机器人和其他决策机器人的背景下定义的。在训练过程中,N个机器人都被建模为半径R相同的圆盘,即所有机器人都是齐次的。
在每个时间步t,第i个机器人(1≤i≤N)有权访问地面观测,并在其处计算无碰撞转向命令,驱动其从当前位置pt i接近目标gi。观测值从概率分布w.r.t.到基本系统状态st i,ot i∼O(st i),仅提供部分状态信息,因为第i个机器人对其他机器人的状态和意图没有明确的了解。与以往方法(如[1]、[3]、[4]、[6]、[8]、[9])中应用的完美传感假设不同,我们基于部分观测的公式使得我们的方法在实际应用中更适用和更稳健。每个机器人的观测矢量可分为三个部分:ot=[ot z,ot g,ot v](这里为了易读性我们忽略机器人ID i),ot z表示其周围环境的原始二维激光测量值,ot g表示其相对目标位置(即机器人局部极坐标系中目标的坐标),ot v是指它的流速。给定部分观测ot,每个机器人独立计算从所有机器人共享的随机策略π中采样的动作或转向命令at:
转存失败重新上传取消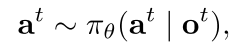
其中θ表示策略参数。计算出的动作实际上是一个速度vt,它引导机器人接近目标,同时避免在∆t时间范围内与其他机器人和障碍物Bk(0≤k≤M)发生碰撞,直到接收到下一次ot+1观测。
因此,多机器人碰撞避免问题可以表述为一个部分可观测的顺序决策问题。由机器人i的观察和动作(速度)正在上传…重新上传取消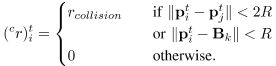 组成的顺序决策可视为从起始位置正在上传…重新上传取消
组成的顺序决策可视为从起始位置正在上传…重新上传取消![]() 提升到期望目标正在上传…重新上传取消
提升到期望目标正在上传…重新上传取消![]() 的轨迹,其中tg是行进时间。为了总结上述公式,我们将正在上传…重新上传取消
的轨迹,其中tg是行进时间。为了总结上述公式,我们将正在上传…重新上传取消![]() 定义为所有机器人的轨迹集,这些机器人受机器人运动学(例如非完整)约束,即:
定义为所有机器人的轨迹集,这些机器人受机器人运动学(例如非完整)约束,即:
正在上传…重新上传取消![]()
为了找到一个所有机器人共享的最优策略,我们采用了一个目标,即在相同的场景中,最小化所有机器人的平均到达时间的期望,定义为:
正在上传…重新上传取消 最小化同一场景中所有机器人的平均到达时间
最小化同一场景中所有机器人的平均到达时间
式中,tg是由共享策略πθ控制的轨迹li in L的行进时间
在第五节中,平均到达时间也将被用作评估学习策略的一个重要指标。我们通过基于策略梯度的强化学习方法来解决这个优化问题,该方法将策略参数更新限制在信任区域内以确保稳定性。
IV. APPROACH
本节首先介绍强化学习框架的关键要素。接下来,我们用一个深神经网络来描述避碰策略的结构细节。最后,我们阐述了用于优化策略的训练协议。
A、强化学习设置
第三节定义的部分可观测序贯决策问题可以表示为一个部分可观测马尔可夫决策过程(POMDP),通过强化学习求解。形式上,POMDP可以描述为6元组(S,a,P,R,Ω,O),其中S是状态空间,a是动作空间,P是状态转移模型,R是报酬函数,Ω是观测空间(O∈Ω),O是给定系统状态的观测概率分布(O∼O(S))。在我们的公式中,每个机器人只能访问从底层系统状态采样的观测值。此外,由于每个机器人以完全分散的方式规划其运动,因此不需要由机器人的运动学和动力学确定的多机器人状态转移模型P。下面我们将详细介绍观察空间、动作空间和奖励函数。
1) 观察空间:如第三节所述,观察时间由二维激光测距仪ot z的读数、相对目标位置和机器人当前速度ot v组成,ot z包括180度激光扫描仪的最后三个连续帧的测量,该扫描仪的最大范围为4米,每次扫描提供512个距离值(即ot z∈R3×512)。实际上,扫描器安装在机器人的前部,而不是中心(参见图1中的左图),以获得大的未包含视图。相对目标位置是以极坐标(距离和角度)表示目标相对于机器人当前位置的二维矢量。观测到的速度包括差动驱动机器人当前的平移和旋转速度。通过减去平均值并除以标准差,利用整个培训过程中汇总的统计数据,将观察值标准化。
2) 动作空间:作用空间是连续空间中的一组容许速度。差动机器人的动作包括平移和旋转速度,即at=[vt,wt]。在本研究中,考虑到实际机器人的运动学和实际应用,我们设定了平移速度v∈(0.0,1.0)和旋转速度w∈(1.0,1.0)的范围。注意,不允许向后移动(即v<0.0),因为激光测距仪无法覆盖机器人的后部区域。
3) 奖赏设计:我们的目标是避免导航过程中的碰撞,并最小化所有机器人的平均到达时间。奖励功能旨在指导机器人团队实现这一目标:
正在上传…重新上传取消![]()
机器人i在时间步骤t时收到的奖励r是gr、cr和wr三个项的总和。特别是,机器人达到其目标所获得的奖励正在上传…重新上传取消![]() :
:
正在上传…重新上传取消![]()
当机器人与环境中的其他机器人或障碍物碰撞时,会受到正在上传…重新上传取消![]() 的惩罚:
的惩罚:
正在上传…重新上传取消
为了鼓励机器人平稳移动,引入了一个小惩罚正在上传…重新上传取消![]() 来惩罚大转速:
来惩罚大转速:
正在上传…重新上传取消![]()
在训练过程中,我们设置rarritival=15,ωg=2.5,rcollision=-15和ωw=-0.1。
B、网络结构
在给定输入(观测正在上传…重新上传取消![]() )和输出(动作正在上传…重新上传取消
)和输出(动作正在上传…重新上传取消![]() )的情况下,详细阐述了正在上传…重新上传取消
)的情况下,详细阐述了正在上传…重新上传取消![]() 和正在上传…重新上传取消
和正在上传…重新上传取消![]() 的策略网络映射,设计了一个四隐层神经网络作为策略πθ的非线性函数逼近器。它的架构如图3所示。我们利用前三个隐藏层有效地处理激光测量。第一个隐藏层在三个输入扫描上卷积32个核大小为5、步长为2的一维滤波器,并应用ReLU非线性[20]。第二个隐藏层卷积32个一维过滤器,内核大小为3,步幅为2,然后是ReLU非线性。第三个隐藏层是具有256个整流单元的完全连接层。第三层的输出与另外两个输入(ot和ot v)相连,然后馈入最后一个隐藏层,这是一个具有128个整流单元的完全连接层。输出层是一个具有两种不同激活的完全连接层:通过双曲正切函数(tanh),使用一个sigmoid函数来约束平动速度vtin(0.0,1.0)的平均值和旋转速度wtin(1.0,1.0)的平均值。
的策略网络映射,设计了一个四隐层神经网络作为策略πθ的非线性函数逼近器。它的架构如图3所示。我们利用前三个隐藏层有效地处理激光测量。第一个隐藏层在三个输入扫描上卷积32个核大小为5、步长为2的一维滤波器,并应用ReLU非线性[20]。第二个隐藏层卷积32个一维过滤器,内核大小为3,步幅为2,然后是ReLU非线性。第三个隐藏层是具有256个整流单元的完全连接层。第三层的输出与另外两个输入(ot和ot v)相连,然后馈入最后一个隐藏层,这是一个具有128个整流单元的完全连接层。输出层是一个具有两种不同激活的完全连接层:通过双曲正切函数(tanh),使用一个sigmoid函数来约束平动速度vtin(0.0,1.0)的平均值和旋转速度wtin(1.0,1.0)的平均值。
正在上传…重新上传取消
图3:避碰神经网络的结构。该网络具有扫描测量正在上传…重新上传取消![]() 、相对目标位置正在上传…重新上传取消
、相对目标位置正在上传…重新上传取消![]() 和当前速度正在上传…重新上传取消
和当前速度正在上传…重新上传取消![]() 输入,并输出速度正在上传…重新上传取消
输入,并输出速度正在上传…重新上传取消![]() 。最后一个动作正在上传…重新上传取消
。最后一个动作正在上传…重新上传取消![]() 是用分离的对数标准差向量正在上传…重新上传取消
是用分离的对数标准差向量正在上传…重新上传取消![]() 从转存失败重新上传取消
从转存失败重新上传取消![]() 构造的高斯分布中采样。
构造的高斯分布中采样。
总的来说,神经网络将输入观测向量ott映射为向量转存失败重新上传取消![]() 。从高斯分布转存失败重新上传取消
。从高斯分布转存失败重新上传取消![]() 中采样的最后动作转存失败重新上传取消
中采样的最后动作转存失败重新上传取消![]() ,其中转存失败重新上传取消
,其中转存失败重新上传取消![]() 用作平均值,转存失败重新上传取消
用作平均值,转存失败重新上传取消![]() 表示日志标准偏差,仅在训练期间更新。
表示日志标准偏差,仅在训练期间更新。
C. 多场景多阶段训练
1) 训练算法:即使深度强化学习算法已经成功地应用于移动机器人的运动规划中,它们也主要集中在离散的动作空间[13]、[21]或小规模的问题[8]、[9]、[16]、[17]。在这里,我们重点学习一种避免碰撞的策略,该策略能够在有障碍物的复杂场景(如走廊和迷宫)中,对大量机器人执行稳健而有效的操作。我们将最近提出的鲁棒策略梯度算法,近端策略优化(PPO)[22]-[24]扩展到我们的多机器人系统。我们的方法适应了集中学习、分散执行的模式。特别是,每个机器人在每个时间步都接收自己的观测值o,并执行共享策略πθ产生的动作;该策略由所有机器人同时收集的经验进行训练。
如算法1(改编自[22]、[23])中总结的,训练过程通过并行执行策略和用采样数据更新策略来在采样轨迹之间进行交替。在数据收集过程中,每个机器人使用相同的策略来生成轨迹,直到它们收集到转存失败重新上传取消![]() 以上的一批数据。然后利用采样轨迹构造代换损失转存失败重新上传取消
以上的一批数据。然后利用采样轨迹构造代换损失转存失败重新上传取消![]() ,并在Kullback-Leiber(KL)散度约束下,用Adam优化器[25]对Eπ周期的代换损失进行优化。以状态值函数转存失败重新上传取消
,并在Kullback-Leiber(KL)散度约束下,用Adam优化器[25]对Eπ周期的代换损失进行优化。以状态值函数转存失败重新上传取消![]() 为基线估计i处的优势,并用采样轨迹上参数为φ的神经网络逼近。Vφ的网络结构与策略网络πθ的网络结构相同,只是它的最后一层只有一个具有线性激活的单元。我们构造了Vφ的平方误差损失LV(φ),并用Adam优化器对其进行了优化。我们独立地更新πθ和Vφ,并且它们的参数是不共享的,因为我们发现在实际应用中使用两个分离的网络将获得更好的结果。
为基线估计i处的优势,并用采样轨迹上参数为φ的神经网络逼近。Vφ的网络结构与策略网络πθ的网络结构相同,只是它的最后一层只有一个具有线性激活的单元。我们构造了Vφ的平方误差损失LV(φ),并用Adam优化器对其进行了优化。我们独立地更新πθ和Vφ,并且它们的参数是不共享的,因为我们发现在实际应用中使用两个分离的网络将获得更好的结果。
由于团队中的每个机器人都是一个独立的数据采集员,因此这种并行PPO算法可以很容易地扩展到一个大型的多机器人系统中,该系统由100个机器人以分散的方式组成。分散执行不仅大大减少了样本采集的时间,而且使算法适用于多种场景下的多机器人训练。
2) 训练场景:为了让我们的机器人暴露在不同的环境中,我们使用场景移动机器人模拟器(如图4所示)创建不同的场景,并同时移动所有机器人。在图4中的场景1、2、3、5和6中(黑色实线是障碍物),我们首先从可用的工作区中选择合理的开始和到达区域,然后在相应区域中随机抽样每个机器人的开始和目标位置。场景4中的机器人被随机初始化成一个半径不同的圆圈,它们的目标是通过穿过中心区域到达它们的对端位置。对于场景7,我们在每集开始时为机器人和障碍物(以黑色显示)生成随机位置;并且机器人的目标位置也是随机选择的。这些丰富、复杂的训练场景使机器人能够探索其高维观测空间,并有可能提高学习策略的质量和鲁棒性。结合集中式学习、分散式执行机制,有效地优化了各种环境下的每次迭代冲突避免策略。
3) 培训阶段:虽然在多个环境中进行的培训在不同的测试用例中同时带来了健壮的性能(见V-C节),但它使培训过程更加困难。在课程学习范式[27]的启发下,我们提出了一个两阶段的培训过程,它加速了政策收敛到一个满意的解决方案,并且获得了比相同历元数的白手起家的政策更高的回报(如图5所示)。在第一阶段,我们只训练20个随机场景(图4中的场景7)的机器人,没有任何障碍,这使得我们的机器人能够快速学习相对简单的避碰任务。一旦机器人达到可靠的性能,我们就停止第1阶段并保存训练策略。此策略将在阶段2中继续更新,机器人的数量增加到58个,他们在图4所示的更丰富和更复杂的场景中接受训练。
转存失败重新上传取消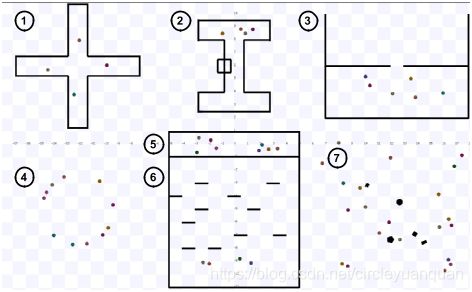
图4:用于训练碰撞避免策略的场景。所有机器人都被模拟成半径相同的圆盘。障碍物显示为黑色。
V. 实验和结果
翻译:
在这一部分中,我们首先描述了训练过程的超参数和计算复杂性。然后,在不同的模拟场景下,将我们的策略与其他方法进行了定量比较。最后,我们证明了所学习的策略在一些具有挑战性和复杂性的环境中具有良好的泛化能力。
A、 训练结构与计算复杂度
我们的算法是在TensorFlow中实现的,并在场景模拟器中对带有激光扫描仪的大型机器人组进行了仿真。我们在一台带有i7-7700 CPU和Nvidia GTX 1080 GPU的计算机上训练多机器人避免碰撞的策略。离线训练需要12个小时(算法1中约600次迭代)才能训练出在所有场景中收敛到稳定性能的策略。表1总结了算法1中的超参数,特别是策略网络的学习率lrθ在第一阶段被设置为5e-5,然后在第二阶段训练阶段被降低为2e-5。对于10个机器人的在线分散控制,策略网络在CPU上计算新动作需要3ms,在GPU上计算新动作需要约1.3ms。
转存失败重新上传取消
图5:在训练过程中,平均奖励以墙时间表示。
B、 各种情景的定量比较
1) 性能度量:为了在不同的测试用例中比较策略和其他方法的性能,我们使用以下性能指标。对于每个方法,每个测试用例都要评估50次重复。
表1:算法1中描述的训练算法的超参数
转存失败重新上传取消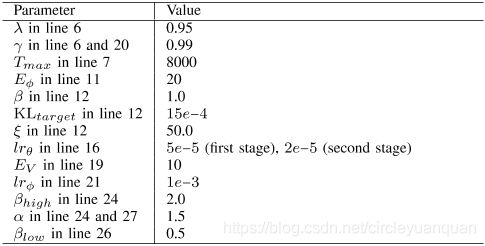
•成功率是指在一定时间内,机器人在不发生碰撞的情况下达到目标的数量与机器人总数的比率。
•额外时间?tem测量所有机器人的平均行程时间与行程时间下限之间的差异(即,机器人以最大速度[7]、[8]直向目标的平均成本时间)。
•额外距离∏测量机器人的平均行进轨迹长度与机器人行进距离下限之间的差异(即机器人沿着最短路径朝目标行进的平均行进距离)。
•平均速度v测量机器人团队在导航过程中的平均速度。
请注意,在评估过程中,将对所有机器人的额外时间和额外距离进行测量,以消除由于代理数量的差异和与目标的距离不同而产生的影响。
2) 循环场景:我们首先比较了我们的多场景多阶段学习策略和NH-ORCA策略[19],以及在不同机器人数量的循环场景中使用监督学习(SL策略,变量[10],详见下文)训练的策略。圆圈场景与图4所示的场景4相似,只是我们在圆圈上统一设置了机器人。我们使用来自[3],[4]的开源NH-ORCA实现,并在模拟中共享所有机器人的地面真实位置和速度。在监督模式下学习的策略具有与我们的策略相同的体系结构(在第IV B节中描述),使用来自[10],[11]的方法在大约800000个样本上进行训练。
与NH-ORCA策略相比,我们的学习策略在成功率、平均额外时间和旅行速度方面都有显著提高。虽然在机器人数量超过15的情况下(表二第三行),我们学习的策略比NHORCA策略的行程稍长,但更大的速度(表二第四行)有助于我们的机器人更快地达到目标。实际上,稍微长一点的路径是更高速度的副产品,因为机器人在停在目标前需要更多的空间减速。
表二:针对不同机器人数量的圆形场景,评估不同方法的性能指标(平均值/标准差)。
转存失败重新上传取消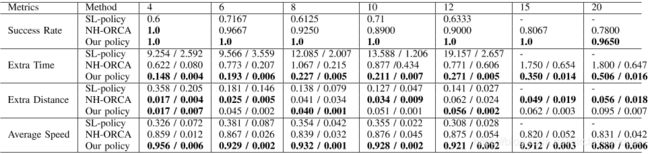
3) 随机场景:随机场景是评价多机器人避碰性能的常用场景。为了测量我们的方法在随机场景中的性能(如图4中的第7个场景所示),我们首先创建5个不同的随机场景,每个场景中有15个机器人。对于每个随机场景,我们重复评估50次。结果如图6所示,它将我们的最终政策与仅在第1阶段(第IV-C.1节)和NHORCA政策中培训的政策进行了比较。我们可以观察到,使用深度强化学习训练的两种策略的成功率都高于NH-ORCA策略(图6a)。还可以看出,使用学习策略的机器人(在阶段1和阶段2)能够比NH-ORCA(图6b)更快到达目标。虽然学习到的策略具有较长的轨迹长度(图6c),但较高的平均速度(图6d)和成功率表明,我们的策略使机器人能够更好地预测其他机器人的运动。与上面的圆形场景类似,稍微长一点的路径是由于机器人在到达目标前需要减速。此外,第一阶段策略在随机场景中的高性能部分是由于过度拟合造成的,因为它是在类似的随机场景中训练的,而第二阶段策略是在多个场景中训练的。
转存失败重新上传取消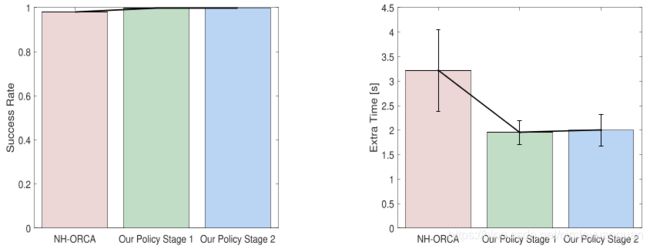
(a)成功率 (b)耗时
转存失败重新上传取消
(c)额外距离 (d)平均速度
图6:随机场景下,为我们学习的策略和NH-ORCA策略评估的性能指标。
4) 小组场景:为了评估机器人之间的合作,我们希望在更具挑战性的场景中测试我们的训练策略,例如小组交换、小组交叉和在走廊中移动的小组。在组交换场景中,我们导航两组机器人(每组有6个机器人)朝相反方向移动以交换位置。对于群组交叉场景,机器人被分成两组,其路径将在场景中心相交。我们通过测量50次试验的平均额外时间,将我们的方法与NH-ORCA在这两个病例上进行比较。从图8可以看出,我们的策略在这两种情况下的性能都比NH-ORCA好得多。较短的目标间隔时间表明,我们的政策已学会产生比基于反应的方法(NH-ORCA)更多的合作行为。然后我们评估了走廊场景,两组人员在有两个障碍物的狭窄走廊内交换位置,如图7a所示,只有第二阶段策略才能完成这项具有挑战性的任务(路径如图7b所示)。第一阶段策略的失败表明,在各种场景下进行联合训练,可以在不同的情况下获得稳健的性能。NH-ORCA策略在这种情况下失败,因为它依赖于全球规划者来指导机器人在复杂环境中导航。如第一节所述,agentlevel碰撞避免策略(如NH-ORCA)需要额外的管道(如指示障碍物的栅格地图)来明确识别和处理静态障碍物,而我们的方法(传感器级策略)则从原始传感器读数隐式推断障碍物,而无需任何额外处理。
转存失败重新上传取消
(a)走廊场景 (b)机器人轨迹
图7:两组机器人在有障碍物的走廊中移动。(a) 显示走廊方案。(b) 显示由我们的第二阶段政策产生的轨迹。
转存失败重新上传取消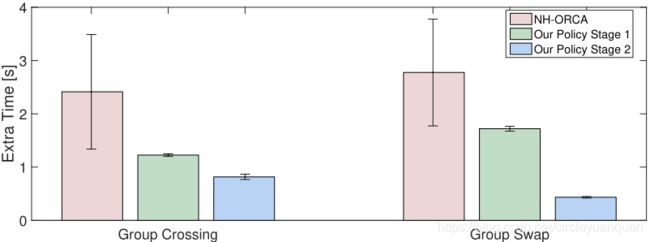
图8:我们的策略(阶段1和阶段2)和NH-ORCA策略在两个组场景中的耗时情况。
转存失败重新上传取消
(a) 异构机器人 (b)非合作机器人
图9:在异构机器人团队(a)中,只有两个圆盘形机器人用于训练。(b) 显示6个机器人在两个非合作机器人(矩形)周围移动,这两个机器人以直线快速移动。
转存失败重新上传取消
图10:模拟100个机器人试图通过圆心移动到相反的位置。
C、 概括
翻译:
多场景训练的一个显著特点是学习策略(第二阶段策略)具有良好的泛化能力。如第三节所述,我们的策略是在一个机器人团队中进行训练,所有机器人共享相同的碰撞避免策略。在整个训练过程中不引入非合作机器人。有趣的是,图9b所示的结果表明,所学习的策略可以很好地直接推广以避免非合作代理(即图9b中的矩形机器人以固定速度直线行进)。回想一下,我们的策略是在具有相同形状和固定半径的机器人上进行训练。图9a显示,学习的策略还可以有效地导航由不同大小和形状的机器人组成的异构机器人组,以在不发生任何碰撞的情况下实现其目标。为了测试我们的方法在大规模场景中的性能,我们模拟了100个机器人在一个大圆圈中移动到对端位置,如图10所示。这表明我们所学习的策略可以直接推广到大规模环境中,而无需任何微调。
VI 结论
翻译:
本文提出了一个多场景多阶段训练框架,利用稳健的策略梯度算法来优化完全分散的传感器级碰撞避免策略。所学习的策略在广泛评估ART NH-ORCA策略的状态时,在成功率、避免碰撞性能和泛化能力方面显示了一些优势。我们的工作可以作为减少集中式和分散式方法之间导航性能差距的第一步,尽管我们充分意识到,当调度多个机器人在障碍物密集的复杂环境中导航时,以局部避免碰撞为重点的学习策略无法取代全局路径规划器。