强化学习论文分析5---多基站_强化学习_联邦学习_计算卸载
目录
- 一、文章概述
- 二、理论模型
-
- 1.系统目标
- 2.约束条件
- 3.公式推导
-
- (1)任务量
- (2)卸载率
- (3)本地能耗
- (4)传输能耗
- (5)MEC计算能耗
- (6)总述
- 三、算法架构----多基站联合强化学习
-
- 1.网络结构图
- 2.算法总述
- 3.Actor网络
-
- (1).输入状态
- (2).输出动作
- 4.Critic网络
-
- (1).环境奖励
- 5.伪代码
- 四、算法架构----多基站联邦学习
-
- 1.网络结构图
- 2.算法总述
- 3.模型融合
- 4.伪代码
- 五、性能表征
-
- 1.计算性能
- 2.能耗指标
本文是对论文《Multi-Agent Deep Reinforcement Learning for Computation Offloading and Interference Coordination in Small Cell Networks》的分析,第一作者为北京邮电大学Xiaoyan Huang

一、文章概述
为了更好地将AI服务应用于通信网络之中,作者建议在每个基站处配置MEC服务器作为辅助。在此情景下,就产生了用户端计算卸载的分配方案选择问题。本文中,作者提出了一种基于多代理联合强化学习的计算卸载算法,有助于整个通信网络运行更为高效。此外,考虑到部分场景无法支持联合强化学习的信令开销,作者还提出了基于联邦学习的计算卸载算法。两种方法均优于常规算法,联合强化学习方案产生更大的信令开销,同时也具有更好的性能。联邦学习方法是对于联合强化学习方法的弱化,旨在用更少的信令,达到优于常规的效果。
二、理论模型
1.系统目标

整个系统所优化的目标是本地(用户端UE)和卸载(基站处服务器MEC)所产生的的能量开销最小化。
2.约束条件

C1:用户处和基站处计算的最大时延必须小于可接受最大时延T。.
C2:卸载任务量占比需在[0,1]之间。
C3-C5:每个UE最多可以分配一个信道,每个小区的每个信道最多可以分配给一个UE。
C6:功率限制
C7:基站内所有UE分配MEC,其总和不能超过MEC总算力。
3.公式推导
(1)任务量
![]()
对于任意时隙,基站M所对应的用户N处的任务具有如上图所示的三个参量,其中![]() 表示计算任务的规模(在传输中使用的参数)。
表示计算任务的规模(在传输中使用的参数)。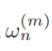 表示计算任务所需要的算力(在本地和服务器计算时使用的参数)。
表示计算任务所需要的算力(在本地和服务器计算时使用的参数)。 表示计算任务可以接受的最大时延。
表示计算任务可以接受的最大时延。
(2)卸载率
对于每一个task,我们用 表示其卸载率(该部分任务交由基站处MEC服务器计算)。相应的,
表示其卸载率(该部分任务交由基站处MEC服务器计算)。相应的, 表示在本地所进行的计算任务占比。
表示在本地所进行的计算任务占比。
(3)本地能耗
对于每一个本地用户终端,我们认为其具有数值固定但相互之间各不相同的算力,表示为算力![]() 。
。
那么,对于每一个计算任务,其本地的计算用时为
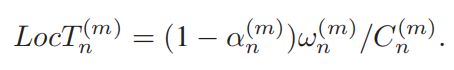
用户侧的功率设为![]() (固定值),其所消耗的总能量如下
(固定值),其所消耗的总能量如下

(4)传输能耗
当计算任务以Un(以香农定理给出)的速率在信道中传送时,所需要的总时长为

相应的,其消耗的能量(Pn表示的是发送功率)为

(5)MEC计算能耗
基站MEC服务器的计算时间消耗为
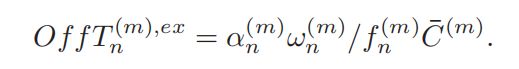
相应的,其能量消耗(时间*功率)为

(6)总述
本地能耗+传输能耗+MEC计算能耗之和,就是本文优化的总目标(最小化功率消耗)。联合强化学习、联邦学习的目的是训练模型,对卸载率、信道分配、功率分配做出决策,达到较优结果。
三、算法架构----多基站联合强化学习
1.网络结构图

2.算法总述
对于多基站联合强化学习算法,作者所搭建的强化学习模型架构如下:在每个基站处,以DDPG(改进版AC)算法为核心进行处理。突出特点在于Critic网络接收全局基站的动作状态信息,对Actor网络进行直到,以达到全局能量消耗最优的任务目标。
3.Actor网络
(1).输入状态
![]()
依次为信道增益、信道干扰以及各任务的分配与完成情况。
(2).输出动作
![]()
依次为UE侧任务卸载率、基站侧信道分配、功率分配以及MEC算力分配。
4.Critic网络
Critic网络以全局能量消耗作为评价指标,对于状态的转换进行评估,给予反馈来控制Actor网络的演进。
(1).环境奖励

环境奖励包含三项,依次为 本地能量消耗(负奖励)、卸载能量消耗(正奖励)以及延时满足情况。
5.伪代码

四、算法架构----多基站联邦学习
1.网络结构图

2.算法总述
对于多基站联邦学习算法,依旧是在每个基站处建立DDPG(改进AC)框架。其联合强化学习显著的不同点是:Critic网络不再接收全局状态-动作信息以计算能量消耗。相应的,Critic网络只计算每个基站的能量消耗与时延满足程度,并在每一个时隙的末尾与其他基站进行模型融合(联邦平均)。
3.模型融合
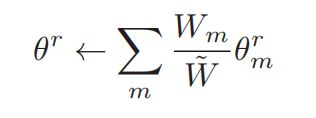
模型融合的方法为常见的联邦平均算法。
4.伪代码

五、性能表征
1.计算性能

2.能耗指标
