【空间/通道注意模型:Nest连接:IVIF】
NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models
(NestFuse: 基于Nest连接和空间/通道注意模型的红外和可见光图像融合架构)
我们提出了一种新颖的红外和可见光图像融合方法,其中我们开发了基于Nest连接的网络和空间/通道注意模型。**基于Nest连接的网络可以从多尺度的角度保存来自输入数据的大量信息。**该方法包括三个关键要素: 编码器,融合策略和解码器。在我们提出的融合策略中,开发了空间注意模型和通道注意模型,它们描述了每个空间位置以及每个具有深层特征的通道的重要性。首先,将源图像输入编码器以提取多尺度深度特征。然后开发了新颖的融合策略,以融合每个规模的这些功能。最后,通过基于nest连接的解码器重建融合图像。
介绍
通常,传统方法涵盖两种方法: 基于多尺度的方法; 基于稀疏和低秩表示 (LRR) 学习的方法。多尺度方法通常将源图像分解为不同的尺度以提取特征,并使用适当的融合策略融合每个尺度特征。然后使用逆算子重建融合图像。尽管这些方法显示出良好的融合性能,但它们的性能高度依赖于多尺度方法。在基于深度学习的融合方法开发之前,稀疏表示(SR) 和LRR引起了广泛关注。基于SR,开发了几种融合算法。例如:Liu等人提出了一种基于联合稀疏表示 (JSR) 和显著性检测算子的融合算法。JSR用于从源图像中提取公共信息和互补特征。
在LRR领域,Li和Wu提出了一种基于LRR和字典学习的多焦点图像融合方法。在这种方法中,首先,将源图像划分为图像块,并利用定向梯度直方图 (HOG) 特征对每个图像块进行分类。通过K奇异值分解 (K-SVD) 学习全局字典。此外,还有许多其他方法结合了SR和其他算子,例如脉冲耦合神经网络 (PCNN),以及shearlet变换。
尽管基于SR和LRR的融合方法显示出非常好的性能。这些方法仍然存在以下缺点:
1)融合算法的运行时间高度依赖于字典学习运算符。
2) 当源图像复杂时,这会导致表示性能下降。
基于深度学习的融合方法。这些方法可以分为两类: 有训练阶段和没有训练阶段。
没有训练阶段*,意味着这些方法没有反向传播,并且使用预训练的网络来提取深层特征,从而导致生成决策图。基于这一理论,Li等人提出了一种利用预训练网络 (VGG-19和ResNet50) 的融合框架。这是首次使用多级深度特征来解决红外和可见光图像融合任务。
由于可以训练图像融合任务的适当模型以获得更好的融合性能,因此最新的深度学习方法均基于此策略。Liu等人提出了一种卷积神经网络 (CNN)用于多焦点图像融合任务的融合框架。Yan等人还提出了一种基于CNN和多级特征的融合网络。在红外和可见光图像融合领域,Li和Wu提出了一种基于密集块和自动编码器体系结构的新颖融合框架。Ma等人将生成对抗网络 (GAN)应用于红外和可见光图像融合任务。与现有的融合方法相比,这些基于CNN或GAN的融合框架实现了非凡的融合性能。
基于深度学习方法的缺点:
1)网络没有下采样算子,不能提取多尺度特征,深度特征没有得到充分利用。
2) 多尺度特征提取需要改进网络架构的拓扑结构。
3) 融合策略未精心设计融合深度特征。
综上我们提出了基于Nest连接和空间/通道注意模型的红外和可见光图像融合架构。
贡献
1)嵌套连接体系结构应用于基于CNN的融合框架。我们的基于nest连接的框架不同于现有的基于Nest连接的框架。它包含三个部分: 编码器网络,融合策略和解码器网络。
2)我们的Nest连接体系结构充分利用了深层特征,并保留了编码器网络提取的来自不同比例特征的更多信息。
3)对于多尺度深度特征的融合,我们提出了一种基于空间注意和通道注意模型的新颖融合策略。
4)与现有的最先进的融合方法相比,我们的融合框架在视觉评估和客观评估方面都具有更好的性能。
相关工作
Deep Learning-Based Fusion Methods
Liu等人提出了基于CNN的融合网络。在他们的论文中,使用了包含不同模糊版本的成对图像补丁 (16 × 16) 来训练其网络。清晰补丁和模糊补丁的标签分别为1和0。该网络的目的是生成决策图,该决策图指示哪个源图像在相应的点处更加集中。在训练阶段,这种基于CNN的方法比2017年的其他算法获得了更好的融合性能。但是,由于训练策略的限制,该方法仅适用于多焦点图像。
为了克服这一弱点,Li和Wu 提出了一种新颖的基于自动编码器的网络(DenseFuse),用于融合红外和可见图像。它由三部分组成: 编码器、融合层和解码器。在训练阶段,丢弃融合层,并且DenseFuse退化为自动编码器网络。训练阶段的目的是获得两个子网络,其中编码器从源图像中完全提取深层特征,解码器根据编码后的特征自适应地重建原始数据。在测试阶段,融合层被用来融合深层特征。然后,通过解码器网络重建融合图像。为了保留更多的细节信息,Zhang等人提出了一种通用的端到端融合网络,它是一种简单而有效的体系结构来生成融合图像。
GAN架构由Ma等人引入红外线和可见光图像融合场 (FusionGAN)。在训练阶段,将源图像串联为张量以馈入生成器网络,并通过该网络获得融合图像。它们的损失函数包含两个术语: 内容损失和鉴别器损失。使用对抗策略,可以训练生成器网络以融合任意红外和可见图像。
Nest Connection Architecture
Nest连接架构是由Zhou等人针对医学图像分割的任务提出的。在深度学习网络中,跳过连接是一种常见的运算符,用于保留来自先前层的更多信息。但是,当在网络体系结构中使用长跳过连接时,语义间隙会导致意外结果。为了解决这个问题,Zhou等人提出了一种新颖的体系结构 (嵌套连接),该体系结构使用上采样和几个短跳过连接来代替长跳过连接。nest连接的框架如图1所示,通过nest连接,可以约束语义间隙的影响,并保留更多的信息以获得更好的分割结果。本文提出的方法就是基于nest连接的改进

方法
Fusion Network
我们的融合网络 (如图2) 包含三个主要部分: 编码器 (蓝色方块) 、融合策略 (蓝色圆圈) 和解码器 (其他)。nest连接在解码器网络中用于处理由编码器提取的多尺度深度特征。

(I1和I2表示源图像。O表示融合的图像。“Conv” 是指一个卷积层。“ECB” 表示包含两个卷积层和一个最大池化层的编码器卷积块。“DCB” 表示没有池化算子的解码器卷积块)
首先,将两个输入图像分别馈送到编码器网络中以获得多尺度深度特征。对于每个比例特征,我们的融合策略都用于融合所得特征。最后,基于nest连接的解码器网络用于使用融合的多尺度深度特征重建融合图像。在接下来的部分中,我们将分别介绍训练阶段和新颖的融合策略。
Training Phase
训练策略类似于DenseFuse。在训练阶段,丢弃融合策略。我们希望训练一个自动编码器网络,在该网络中,编码器能够提取多尺度深度特征,并且解码器从这些特征重构输入图像。训练框架如图3所示,融合网络设置如表II所示。

(在图3和表II中,I和O分别是输入图像和输出图像。编码器网络由一个卷积层 (“Conv”) 和四个卷积块 (“ECB10” 、 “ECB20” 、 “ECB30” 和 “ECB40”) 组成。每个块包含两个卷积层和一个最大池化运算符,可以确保编码器网络可以提取不同比例的深层特征;解码器网络具有六个卷积块 (“DCB11” 、 “DCB12” 、 “DCB13”; “DCB21” 、 “DCB22”; “DCB31”) 和一个卷积层 (“Conv”)。通过嵌套连接架构连接六个卷积块,以避免编码器和解码器之间的语义间隙。)

在训练阶段,损失函数Ltotal定义如下:

其中Lpixel和Lssim表示输入图像I和输出图像O之间的像素损耗和结构相似性 (SSIM) 损耗。λ 表示Lpixel和Lssim之间的权衡值。
Lpixel由以下方程式计算:

其中O和I分别表示输出图像和输入图像。| |·| | F是弗罗贝尼乌斯范数。Lpixel计算O和I之间的距离。此损失函数将确保重建的图像在像素级别上更类似于输入图像。
SSIM损耗Lssim由下式得到:

其中SSIM(·) 表示结构相似性度量。当SSIM(·) 的值变大时,输出图像O和输入图像I在结构上具有更大的相似性。
训练阶段的目的是为编码器网络和解码器网络获得两个强大的工具。因此,训练阶段的输入图像的类型不限于红外和可见图像。在训练阶段,数据集MS-COCO [36] 用于训练我们的自动编码器网络,我们选择80000图像作为输入图像。这些图像被转换为灰度,然后调整大小为256 × 256。由于Lpixel和Lssim之间的数量级不同,因此参数 λ 设置为1、10、100和1000以训练我们的网络。
Fusion Strategy
大多数融合策略都基于权重平均运算符,该运算符生成权重图以融合源图像。基于这一理论,权重图的选择成为一个关键问题。当将融合策略添加到测试一下阶段时,融合网络变得更加灵活; 但是,这些策略并非针对深度功能而设计,并且尚未考虑注意机制。为了解决这个问题,在本节中,我们介绍了一种基于两个阶段注意力模型的新颖融合策略。在我们的融合架构中,m表示多尺度深度特征的级别,m ∈ {1,2,…,M},M = 4。我们的融合策略的框架如图4所示。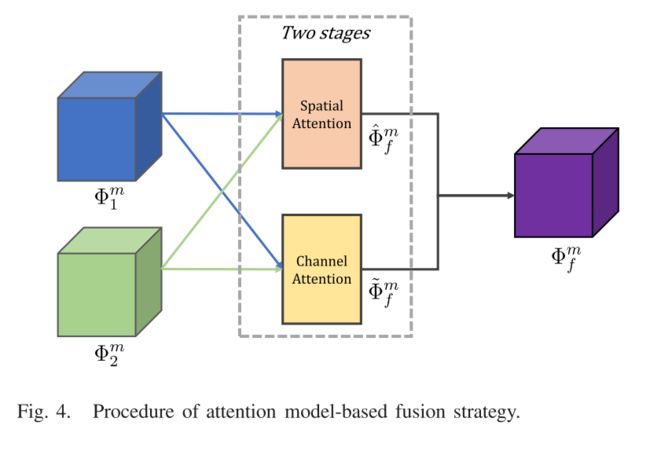

在我们的融合策略中,我们关注两类特征: 空间注意力模型和渠道注意力模型。提取的多尺度深度特征分两个阶段进行处理。

介绍基于注意力模型的融合策略:
1) Spatial Attention Model:
在之前的文献中在图像融合任务中使用了基于空间的融合策略。在本文中,我们将此操作扩展到融合多尺度深层特征,并称为空间注意力模型。获取空间注意力模型的过程如图5所示。

Β m 1和 β m 2 代表由l1-norm和软最大算子从深度特征m 1和m 2计算的加权图。加权图由以下公式表示:

其中 | | · | | 1表示l1-norm,k ∈ 1,…,K和K = 2。(x,y) 表示多尺度深度特征 (Φm 1和Φm 2) 和加权图 (β m 1和 β m 2) 中的相应位置,每个位置表示深度特征中的C维向量。Φm k (x,y) 表示具有C维的向量。

通过以下公式计算:

2) Channel Attention Model:
深层特征是三维张量。因此,在融合策略中不仅应考虑空间维度信息,而且还应考虑通道信息。因此,我们提出了一种基于渠道注意力的融合策略。该策略的示意图如图6所示。


其中k ∈{1,2},n表示深度特征Φm k中通道的相应索引,P(·) 是全局池化算子。
在我们的渠道注意模型中,选择了三种全局池化操作,包括: 1) 平均运算符,计算每个渠道的平均值; 2) max运算符,计算每个渠道的最大值;和3) 核范数算子 (| |·||∗) 是一个通道的奇异值之和。
