双流网络学习笔记
1.视频理解学习笔记
- 1.视频理解学习笔记
- 1.1.视频理解概述
- 1.2.双流网络的诞生
- 1.3.双流网络论文讲解
- 1.3.1.双流网络主要思想
- 1.3.2.关于光流(Optical flow)
- 1.3.3.双流法的继承
- 1.3.4.双流神经网络的结构
- 1.3.4.1.空间流神经网络
- 1.3.4.2.时间流神经网络以及如何利用光流
- 1.3.4.2.1.光流及其具体表示
- 1.3.4.2.2.如何使用光流
- 1.3.4.2.3.关于时间流卷积神经网络的输入
- 1.3.4.3.最后的输出
- 1.3.5.测试过程
- 1.3.6.如何计算光流
1.1.视频理解概述
为什么要选择视频?视频相对于图片所拥有的信息更多,利用这些不同方面的信息,可以完成多种信息提取,比如说从视频可以提取到时序性信息、从视频单个帧可以提取到视觉信息,如果将视觉、时序、听觉等方面结合起来,就是我们所说的多模态。
同时,视频相较于图片其实更能够体现人的视觉机制,因为我们人类的视觉本质上其实一张张连续图片构成的“视频”,而并非单个的一张图片。
过去十年来。计算机视觉在2D上完成了众多壮举,但是这远远不够,视频对于图片形式更加多样,内容也非常多样,所以视频理解的研究前景非常可观。
1.2.双流网络的诞生
其实在之前,DeepVideo已经将深度学习的卷积神经网络运用到了视频分类领域,但是相较于人工特征提取进行分类,效果还没有人格特征提取的效果好,所以slowfast——双流神经网络的提出就是为了改变这个现状。
它的主要成就就是让深度学习在视频分类这一块站稳了脚跟,它可以和当时最好的人工特征提取方法达成平手。
1.3.双流网络论文讲解
文章标题为 Two-Stream Convolutional Nets for Action Recognition in Videos,从中我们不难发现,这个网络主要针对于视频中的行为识别。在一段视频中,我们其实更加关心的是人的动作,所以说在视频中做这个行为识别是非常有价值的。
1.3.1.双流网络主要思想
在最开始的时候,也就是DeepVideo那个时代,我们常常使用的是将一个视频:
- 抽取关键帧数,将这些帧图片一个一个通过卷积神经网络;
- 要么就是将这些帧图片叠起来,当作一个整体输入然后扔给神经网络。
但是这些工作的效果都不非常好。
双流网络的作者认为,以往的卷积神经网络更容易学习局部的特征,但是对于时空上的物体的动作运动信息,它不能够很好地处理。
那么双流网络的作者就想:那就干脆再设计一条神经网络让其学习从“输入光流(Temporal Stream)”到“动作类别”的一个映射,也就是说这里的输入贯穿了整个时间序,现在就需要两条神经网络分别学习“空间上的信息”到“种类”的映射和“时间上的信息”到“种类”的映射。
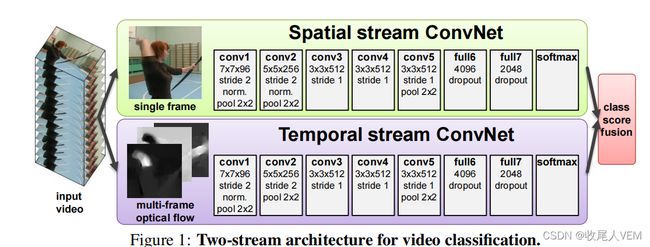
这里的空间信息我们用Spatial stream——空间流来表示,时间信息则使用光流这个概念来定义。
两条神经网络的前向传播的输出有两个概率,那么只需要将这两个概率取得加权平均值就可以得到一个汇总的概率值了。
可以看到,双流神经网络就是把最重要的“时序”信息给补上了,让CNN也能够学习到时间变化时,物体的变化特征。
事实上,作者也在双流网络原论文中讲到了:双流网络提出的启发主要来自元人类的视觉中枢的工作原理——也是有两条路的:dorsal stream and ventral stream,前者完成对运动信息的处理,后者完成对空间信息的识别。
1.3.2.关于光流(Optical flow)
所谓的光流,就是描述光的流动规律,具体一些就是描述视频中物体的运动状态变化规律。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

例如,上面的的图片是由两张帧图片叠加在一起形成的,所以有些“残影”。
如果要更形象一些,我们可以这样表示(这两张不一样哦):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
可以看到黑色的地方的像素值就是接近于0的,也就是说黑色部位的变化值为接近于0,也就是说这个部位没有发生运动,而白色的部位则是说明这个人的头进行了一定的运动。
由于拍摄用的是手机,所以就算人静止,也会有相对位移。
因此,我们提取到的光流特征就是一个忽略了其他因素,完全考虑物体运动的特征信息。
1.3.3.双流法的继承
事实上,我们今天所说的双流法来自于之前的“基于光流轨迹”的手工特征提取方法,而如今的3D卷积网络来自于之前的“局部的时空学习”手工特征提取。
基于光流轨迹的手工特征提取方法其实和双流法类似——利用视频前后帧,来提取点对点的关系。
至于之前的研究工作,以DeepVideo为代表的一些列深度学习视频分类工作,利用了非常庞大的数据集(10亿张视频帧图片),讲视频分帧后叠加在一起然后扔给卷积神经网络。
作者在论文中也介绍到了:如果把视频帧一张一张扔给2D卷积神经网络与把视频帧叠加在一起然后扔给3D卷积神经网络,两者的效果是一样的。也就是文章开头的一句话,这些学习都没有抓住如何提取出运动信息特征信息。
1.3.4.双流神经网络的结构
视频可以被拆分为空间部分和时间部分,二者描述的特征类别不同。那么就让空间神经网络去学习空间特征,而时间神经网络去学习时间特征,两者互不打扰,到最后进行一个late fusion合并信息即可。
1.3.4.1.空间流神经网络
这个网络分支就是完成一个普通的图像分类,从静止的图片中提取出空间特征并利用全连接层映射为一个预测的特征向量。

1.3.4.2.时间流神经网络以及如何利用光流
1.3.4.2.1.光流及其具体表示

如图所示,a、b就是视频的连续的两个帧数,d、e分别为两个方向维度上的光流。
首先这两张帧图片维度为:
( h e i g h t , w i d t h , c h a n n e l ) (height,width,channel) (height,width,channel)
不管使用什么光流算法,你最后生成的图c为:
( h e i g h t , w i d t h , d i m s ) (height,width,dims) (height,width,dims)
其中dims为x、y两个方向上的光流,因此d、e图形状为:
( h e i g h t , w i d t h , 1 ) (height,width,1) (height,width,1)
1.3.4.2.2.如何使用光流
要注意的是,如果我们直接将我们的光流图输入到卷积神经网络中去,那么我们本质上还是在做一个图像分类,因此,我们需要改变一下策略。
以往的手工特征提取方法是同时处理了多张光流图,这样理解:光流可以理解为一个动作的变化,那么我们不能通过一个变化就能猜出一个人在干什么,所以我们需要多个变化,所以以往的方法一次性处理的都是10-16帧图片。放在这里,我们需要将多个光流图叠加在一起再输入。
也就是说,时间流神经网络的输入叠加的光流图,那么如何叠加效果要好一些呢?该论文有提出了两种方法:
-
第一种就是对应位置的相叠加。
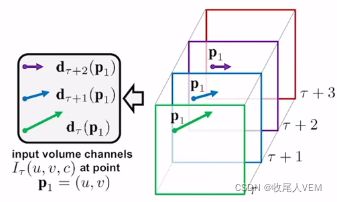
这种方式的处理就相较而言比较简单。但是没有充分利用光流信息。
-
第二种方式,就是移动点的对应位置寻找。
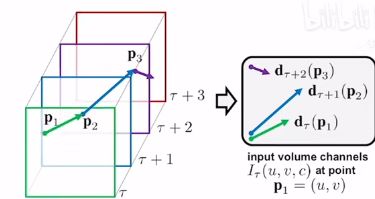
也就是说对于一个移动的点,去“跟踪”他的位置。
但是,最后实验发现第二种基于轨迹的实验效果要差一些。
关于光流的使用,作者还使用了一种trick——前向“追踪”+后向“追踪”,也就是说,你一个物体从A点到B我可以认出你在干什么,你反过来其实我还是可以认出来你在干什么?所以说假如是有L个光流图,我们最后输入的是L个前向光流图+L个后向光流图,总共2L个光流图。
1.3.4.2.3.关于时间流卷积神经网络的输入
前面我们都知道了时间流神经网络的输入是叠加的光流图片,那么具体叠加又是怎么叠加的呢?
论文里面给定的是现将水体方向的光流图进行叠加,然后再进行竖直方向的叠加。
那么最后可以得到的叠加为:
( h e i g h t r e s i z e , w i d t h r e s i z e , 2 L ) (height_{resize},width_{resize},2L) (heightresize,widthresize,2L)
1.3.4.3.最后的输出
上方、下方的网络输出的是一个:
( n u m c l a s s e s , 1 ) (num_{classes},1) (numclasses,1)
的特征向量,那么现在只需要进行一个权重相加并进行argmax即可。
到这里的话,双流神经网络的结构就完成了。
1.3.5.测试过程
训练我们已经介绍了,在测试的时候,需要把一段视频分成指定数目的视频帧,然后再将每一张帧图片进行ten-crop操作,也就是将图片分为两个部分,一个部分进行随机翻转,另一个不变,分别对这两个图片进行如下操作:
- 以一定长度取得四个边角图片
- 以相同长度取得中间的图片。
对于一个fps为f的长度为t秒的视频,我指定分为25帧,那么间隔为:
f × t 25 \frac{f\times t}{25} 25f×t
每一张帧图片有10个小图片,那么进一步就是250个图片。
对于光流来说也是一样的,要取得25帧图片后,并从这25帧的位置开始往后面连续取得L帧光流,然后将这些光流图送入时间流神经网络。
最后将取得的两个输出,进行late-fusion,从而得到最终结果。
1.3.6.如何计算光流
论文中采用的是一种使用了GPU计算的光流计算方法,引用论文下标为2,计算一帧光流图大概需要0.06秒。
但是,对于大型的数据集,耗时间是非常大的,将近一个月。并且,光流表示是密集数据,也就是对于一对图片,光流需要表示每个像素的变化,因此存储空间也是非常大。针对于这个存储空间需求大的问题,作者类别图像分类的归一化,将光流图的像素值也进行归一化到了[0,255]这个区间内部,并存储为JPEG格式图片,让存储空间从1.5TB缩减为27GB,但是光流对于大型数据所需的存储空间还是非常大。
因此,后续的工作主要是针对于光流的改进或者是直接另寻方法——3D卷积神经网络。
学习资料:
B站视频