聊一聊mmdetection代码框架和自己对于目标检测的新理解
聊一聊mmdetection代码框架和目标检测
文章目录
- 聊一聊mmdetection代码框架和目标检测
-
- 一.为什么要写这篇文章
- 二.关于图像识别任务的共性
-
- 1.图像分类
- 2.语义分割
- 3.目标检测
- 三.mmdetection代码框架解析
-
- 1.配置环境方面
- 2.demo文件夹
- 3.weights文件夹
- 4.setup以及与setup相关的脚本
- 5.训练
-
- (1)train.py
- (2)config
- 6.总结一下
- 四.结语
阅读注意事项:
- 本篇文章主要内容为我自己对于mmdetection工作原理的分析以及部分图像识别任务的个人看法,至于mmdetection的安装和使用,网上有很多非常详细的讲解视频,我就不详解了。
- 由于是个人理解,写文章来做个笔记,若有错误,敬请指正。
import argparse
一.为什么要写这篇文章
前段日子比较忙,忘了对再前些日子学到的东西进行一个总结和归纳:前些日子学习一下目标检测的论文并尝试复现了一下YOLOv1,再加上最近在弄时空检测模型,就趁着这个机会表达一小部分自己的见解并较为仔细地讲一下自己对于mmdetection的代码框架和工作原理。
二.关于图像识别任务的共性
在我看来,像语义分割/目标检测/图像分类这三大图像识别任务都是先通过backbone提取主干特征然后进行对应的处理,比如说:
1.图像分类
对于图像分类,在得到了卷积层输出的高维度特征张量后,需要先展平空间特征,
( b a t c h s i z e , c h a n n e l s , h e i g h t , w i d t h ) − > ( b a t c h s i z e , s p a t i a l f e a t u r e ) (batch size,channels,height,width)->(batch_size,spatial feature) (batchsize,channels,height,width)−>(batchsize,spatialfeature)
然后进入全连接层(CNN其实就是卷积层+全连接层,其中全连接层可以看作传统的BP神经网络),得到最后的输出特征向量。
2.语义分割
至于语义分割,就以最经典的U形神经网络Unet来解释一下,Unet前半部分是Encoder,而后半部分是Decoder——通过卷积可以进行下采样操作,特征图语义信息增加、尺寸变小,这便是Encoder;通过反卷积则可以降低语义信息、增加图像尺寸,这便是Decoder。
其中Encoder操作就是我们说的backbone提取主干特征,而Decoder则是起到一个特征还原的作用,本质上还是对提取到的信息进行一个处理。
3.目标检测
对于目标检测,由于目标检测算法较多且复杂,这里就以YOLO系列为主(目标检测算法可以分为one-stage和two-stage,YOLO系列为one-stage代表模型),用v2-v5来讲一下目标检测与图像识别任务的共性:
为何不先讲v1呢?因为YOLOv1到YOLOv2的改进非常大,对于YOLOv1而言,再进行了特征提取后,剩下的操作与图像分类一样,但是唯一不同的是,YOLOv1需要将输出特征向量规范为:
( b a t c h s i z e , 30 , 7 , 7 ) (batch_size,30,7,7) (batchsize,30,7,7)
的大小,可见这里的YOLOv1使用到了全连接层(不了解YOLOv1原理的小伙伴可以参考一下我复现YOLOv1的文章)。但是在YOLOv2中,作者为了解决YOLOv1中存在的一些问题,eg:coordinate收敛缓慢或者无法收敛(位置信息),直接将全连接层该去掉并且引入锚框等新概念用于改进特征处理过程。到了v3,作者又创造性地给YOLv2网络加入了FPN(特征金字塔)以及Darknet53等结构,但是无论是后面v4、v5新增的结果或者是激活函数,整体上都是在backbone输出特征信息的处理以及backbone提取信息的过程下手。因此,YOLO系列在我看来进步最大的就是YOLOv1的产生以及YOLOv2从YOLOv1的改进。
故而,我们可以看到不管是什么任务最关键的就是对于特征的提取以及对提取到的特征的进一步提取或者利用。
三.mmdetection代码框架解析
多说无益,我们现在就对这个代码框架的工作原理进行解析。
1.配置环境方面
配置环境方面,我一般用的是这个命令:
conda create -n mmdet python=3.8
conda activate mmdet
conda install pytorch=1.8 torchvision cudatoolkit=10.2 -c pytorch
来安装pytorch1.8和python3.8 or python3.7,主要是因为这两个版本的pytorch和python比较稳定——pytorch1.9有一些烦人的bug,而python3.7 or python3.8可以兼容大部分python包。
后面就只需要安装好MMCV并通过如下命令:
pip install -r requirements.txt
python setup.py develop
安装好所需库和mmdetection。
2.demo文件夹
一般来说,对于每一个mmlab系列的深度学习工具包,其主干目录下一般都会有一个叫做demo的文件夹,这个文件夹里面村的都是一些预测代码或者是用于预测文件,当然还可能有其他功能的杂项文件:
![]()
比如说上图中的这个文件夹,一般来说用于前向传播预测到的脚本都会以“webcam”这个前缀开始。一般来说这个文件夹主要分为两大部分:参数解析与主程序调用:
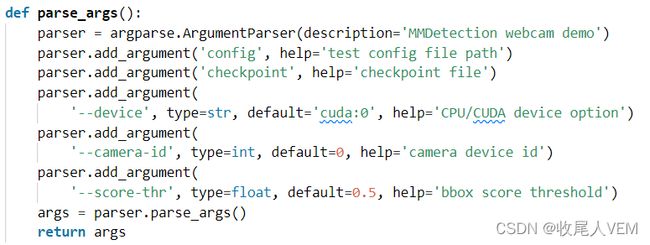
上图为参数解析部分。
可以看到上面的参数列表中主要包含:config、checkpoint、device:
- config是测试使用的配置文件;
- checkpoint一般是用于前向传播预测要使用的权重文件;
- device就是使用的计算平台——cpu or gpu;
同时,还有2个额外参数:
- camera-id:目标检测一般可以用在视频的目标检测中,那么就需要摄像头,如果存在多个摄像头,需要自行设定参数;
- score-thr:这个老熟人了,目标检测在NMS操作中,需要设定阈值去除置信度没达到我们设定阈值要求的bounding box。
另外,再说一下这个参数解析的原理:
通过上面的参数解析函数我们得到了一个返回形参args,这个对象是一个argparse.Namespace的类的对象,这个类的属性便是我们上面定义的config、checkpoint等数据,通过访问这些属性便可以得到一个参数值,可见这个类起到一个“参数存储器”的作用——参数被解析器parser解析后用一个Namespace参数存储器存储起来。
![]()
在main函数中,通过调用一些模块化的函数,这些函数高度的“抽象化”(具体个怎么抽象化我们后面分板块来说,先了解好这个demo文件夹的作用以及这种“参数解析+主程序调用”的结构),在上图中通过调用模块化函数init_detector初始化模型,并通过访问Namespace对象的config等属性来得到参数。
3.weights文件夹
这个文件夹没什么好说的,存放的是一些官方已经训练好的网络权重,但是严格意义上来讲,这种权重应该叫做“网络+数据集+输入权重”,意思就是说,一般这些权重由三个维度去定义:
- 训练所需的backbone或者是算法
- 输入的尺寸或者大小
- 数据集格式或者类型,eg:voc、coco
- 另外,对于特殊的训练任务可能还有其他定义维度,eg:mmaction(mmlab的视频理解工具包)对于权重还有一个定义维度叫做训练方法:rgb或者光流。
4.setup以及与setup相关的脚本
一般来说,setup开头的脚本,eg:setup.cfg或者setup.py是用于mmdetection工具包的安装,搭配setuptools包库使用。
5.训练
这里的话,我们按照这个训练流程来“寻根溯源”,找到背后的运行原理。
(1)train.py
这是一个位于./tools下的脚本文件,先说一下tools文件夹吧,这个文件夹顾名思义,存放了一些训练工具,以目标检测的mmdetection举例子,就主要包括了:训练分析工具以及能够在不同平台(linux和windows)上运行的脚本文件(.sh or .py)。
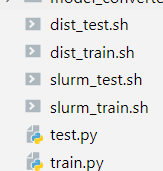
至于train.py文件,我们先看一下文件开头吧:

可以发现,他会从一个mmdet的下的datasets、models、utils导入一些函数,这些函数就是我上面提到的高度“抽象化”函数,什么叫高度抽象化呢?也就是说一般我们在写不同目标检测算法的时候,对于一个流程,eg:构建数据集,这个流程其实对于不同算法或是任务会有不同的搭建函数,也就是说你每次任务都得写一次,这就是高度具体化。
那么高度抽象化就是我可以只写一个函数,比如说这里的build_dataset来完成一个数据集的搭建,对于每一个目标检测任务我都可以用这个,只不过要调整、输入的参数可能变多了而已。
说的简单一点,人家就是把各种功能相似的模块函数集合在一起了,你直接调用就。
因此可见这个mmdet可谓是整个工具包中的核心部件。
train.py从这些库中导入了自己训练所需要的基本组件函数,然后我们继续往下看。

我们发现,接下来的还是一些类似于预测脚本的参数解析,但是相比于预测,这里一般需要填写的参数为:
- config:训练配置文件(后续会讲到);
- resume-from:导入的预训练权重路径;
- –no-validate:决定是否需要去进行验证;
- work-dir:工作目录,aka:训练日志存储目录;
- gpus和gpu_ids:gpu的个数以及当前使用gpu的下标;
基本上,主要的就这几个,其他的不常用,若要用可以自行阅读help。
然后,还是跟预测代码一样为main函数调用,总体上,如果你要训练自己的数据集,可以自行调整参数。
(2)config
这个config其实就是一些py文件,但是这些py文件很意思,首先,我们train.py的参数解析中就有config这一参数,但是一般来说,训练不应该还要给数据集定义参数吗?但是参数解析器中没有add呀~其实很明显了,说明这些参数在config中呗,config文件夹的结构如下:
-config
--_base_
--fast_rcnn
--faster_rcnn
--yolo
......
对于_base_之外的python脚本(都是存储字典或者src列表,字典存配置,src列表存其他python脚本的src),一般要么是存储了数据配置的字典,要么是存储了model的字典,要么是存储了存储其他python脚本src的列表。
_base_内的python脚本分一般主要分为models和datasets,这个就很明确了,models就是存backbone结构配置、datasets存储数据集配置,至于_base_之外的,,,嗯,我估计是开发者更新的时候给“随便”排在那儿的吧,当然,我在用mmaction2的时候,作者干脆就直接在一个脚本里面将dataset和model配置都放在一起。
至于config调用,那就是train or demo中的预测脚本调用config脚本路径,然后会调用一个mmcv中类,叫做Config:

mmcv呢,大家用mmlab都肯定是耳熟能详——必备的基库,对于每一个mmlab计算机视觉工具包都需要mmcv的支持。而这个Config和其他mmcv的类都是mmlab开发人员写出来的,首先跟普通python库ConfigParser一样,实例化一个parser对象:
cfg = Config(....)
然后通过cfg去访问这些配置字典,eg:访问model结构配置字典——cfg.model。
因此,一般如果要自己训练一个自定义数据集的话,就好创建一个data目录,然后把python配置脚本改成固定路径就行了。
![]()
一般就是这种data root的地方改就可以了。
6.总结一下
如果要训练自己定义的数据集:(环境配好的前提下)
- 创建data目录,按照官方文档,将数据集转换为正确格式;
- 找到自己训练任务对应的python配置脚本,修改data root和其他自己想要的参数;
- 修改tools/train.py脚本下的一些主要参数——特别是config。
- 运行train.py就可以开启漫长的训练之旅啦。
四.结语
这篇文章只是我个人对mmlab和目标检测一些见解,如果说对在使用mmlab系列工具包的小伙伴有啥用处的话,可能就是让你们能够更加透析mmlab系列代码构架和工作原理,从而让你们更好地debug和高效率完成任务。
简单来说,mmlab系列“张持有度”,不仅仅是在pytorch等浅层深度学习框架上进行了更高级的封装,还在原基础上融合了更多模型和数据集,在一定程度上既具象化,又抽象化。
最后呢,不得不佩服mmlab的大佬们,首先就是编程的严谨性和这种产品构架思考的创新型,不得不说,作者本人都觉得这些代码都算得上是艺术品,等自己大四或者大三卷完了或者是现在有空,我自己也想并且也在尝试自己复刻mmlab的代码框架。
如有不足和错误,敬请指正。
本文可能会随着博主的研究推进、进一步剖析代码框架而不断更新哦~