《HRNet-OCR:Object-Contextual Representations for Semantic Segmentation》论文笔记
参考代码:HRNet-OCR
1. 概述
导读:这篇文章研究了语义分割中上下文信息的提取与表达,其方法设计的灵感来自于:分割中一个像素的label是其对应目标(object)的类别,那么基于此文章便是通过不同object区域的表达去关联并表达一个像素(特征图上)的信息,从而建立更加具有区分性质的上下文信息。对此完成该目的需要3个步骤:
1)通过在GT的监督训练下得到图片的分割结果;
2)在分割结果的基础上按照分割的类别划分区域(对应文章的object),使用区域中像素去计算区域的表达(OCR,Object-Contextual Representations);
3)建立每个像素与不同区域之间的联系,这里通过加权的方式去聚合不同区域的表达,从而去增强像素信息的表达;
文章的方法提供了另外一种角度的上下文信息增强方法,通过添加SegFix的后处理过程可以进一步优化分割边界,从而文章的整体方法HRNet+OCR+SegFix取得相当不错的分割结果。
文章的方法是通过在分割网络的中间阶段通过一个分割预测头来生成一个corse的分割结果,再在此基础上使用文章提到的object-contextual representation去优化特征图中的像素,因而文章的方法将相同目标类别的上下文信息与不同不目标类别的上下文信息进行区分,也就是说文章的方法是基于目标的(object based)。
在常见的上下文信息提取的方法中有比较常用的基于空间聚合的也有基于attention方式聚合的,这里将他们与文章的方法进行比较:
- 1)基于空间的方法,这类中ASPP/PPM是典型的代表,其区分的是当前pixel与周围位置的pixel。以典型的ASPP方式为例子,对于一个增强之后的像素其输出可以描述为:
y i d = ∑ p s = p i + d Δ t K t d x s y_i^d=\sum_{p_s=p_i+d\Delta_t}K_t^dx_s yid=ps=pi+dΔt∑Ktdxs
其中, x s x_s xs代表的是输入特的pixel, K K K代表的是对应空洞卷积的参数, d d d代表膨胀系数。在下图中展示的是文章的方法和ASPP方法使用使用上下文上的不同:

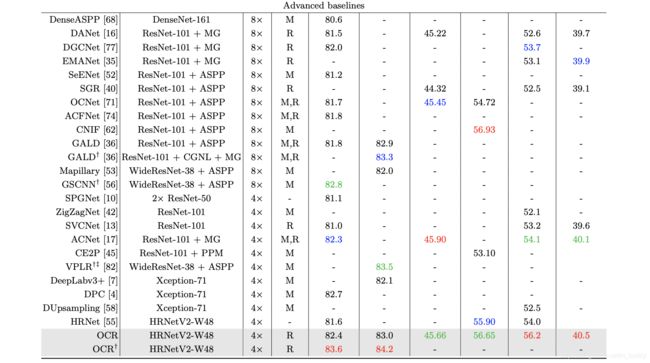
从下表可以看看与其它空间聚合类方法的性能比较:
- 2)基于attention的方法,这类中DANet/ CFNet/ OCNet是较为典型的代表,多使用attention的方式去建立当前像素和整体像素之间的关系,并没有去考虑像素所属的不同目标属性,其输出可以描述为:
y i = ρ ( ∑ s ∈ I w i s δ ( x s ) ) y_i=\rho(\sum_{s\in I}w_{is}\delta(x_s)) yi=ρ(s∈I∑wisδ(xs))
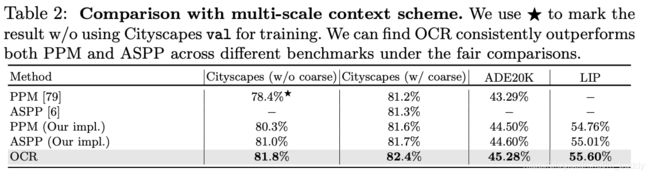
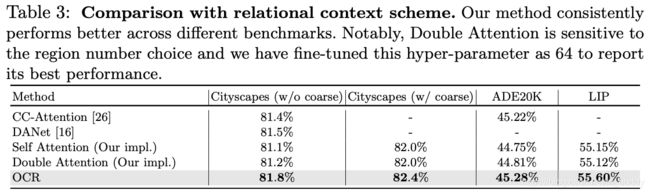
与上述attention方式进行特征增强性能上的比较:
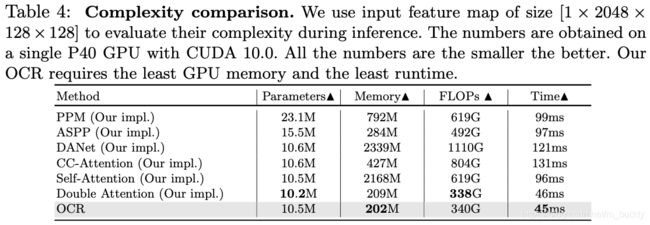
上面的两种方式其计算量与文章方法的比较:
2. 方法设计
2.1 OCR头结构
文章基于目标的上下文信息增强方法其结构见下图所示:
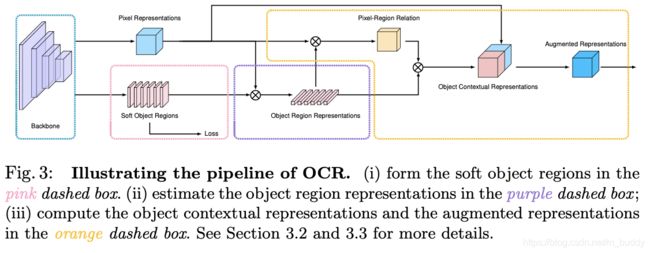
2.1 OCR头原理
文章整体的像素特征增强的过程可以通过下面的公式进行表达:
y i = ρ ( ∑ k = 1 K w i k δ ( f k ) ) y_i=\rho(\sum_{k=1}^Kw_{ik}\delta(\mathcal{f}_k)) yi=ρ(k=1∑Kwikδ(fk))
其中, f k \mathcal{f}_k fk是第 k k k个区域的表达, w i , k w_{i,k} wi,k是第 i i i个像素对第 k k k个目标的关系(也就是加权系数),这样每个像素点就与所有的不同目标关联起来了。其具体的对应代码如下:
# ocr 对应Step1
out_aux = self.aux_head(feats) # feats是backbone输出u的特征图
# compute contrast feature
feats = self.conv3x3_ocr(feats)
context = self.ocr_gather_head(feats, out_aux) # 对应Step2
feats = self.ocr_distri_head(feats, context) # 对应Step3
out = self.cls_head(feats)
具体要实现上述的功能,则就需要完成下面的3个步骤:
Step1:
获得分割目标,这里通过分割头在分割网络的中间得到一个corase的分割结果,之后根据分割结果中不同像素的类别将其划分为 K K K个不同的目标 { M 1 , M 2 , … , M k } \{M_1,M_2,\dots,M_k\} {M1,M2,…,Mk}。对应的代码便是:
self.aux_head = nn.Sequential(
nn.Conv2d(last_inp_channels, last_inp_channels,
kernel_size=1, stride=1, padding=0),
BatchNorm2d(last_inp_channels),
nn.ReLU(inplace=relu_inplace),
nn.Conv2d(last_inp_channels, config.DATASET.NUM_CLASSES,
kernel_size=1, stride=1, padding=0, bias=True)
)
Step2:
计算目标区域的表达,这里通过每个目标的分割概率(通过softmax normalize)与输入的特征图进行计算,得到每个区域的特征表达:
f k = ∑ i ∈ I m ‾ k i x i \mathcal{f}_k=\sum_{i\in I}\overline{m}_{ki}x_i fk=i∈I∑mkixi
对应的实现代码:
batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
probs = probs.view(batch_size, c, -1)
feats = feats.view(batch_size, feats.size(1), -1)
feats = feats.permute(0, 2, 1) # batch x hw x c
probs = F.softmax(self.scale * probs, dim=2)# batch x k x hw
ocr_context = torch.matmul(probs, feats).permute(0, 2, 1).unsqueeze(3)# batch x k x c
Step3:
计算目表上下文表达,这里是将不同的目标(object)区域表达与当前像素点 x i x_i xi计算相关性:
w i k = e k ( x j , f k ) ∑ j = 1 K e k ( x j , f j ) w_{ik}=\frac{e^{\mathcal{k}(x_j,f_k)}}{\sum_{j=1}^Ke^{\mathcal{k}(x_j,f_j)}} wik=∑j=1Kek(xj,fj)ek(xj,fk)
其中, k ( x , f ) = ϕ ( x ) T ψ ( f ) \mathcal{k}(x,f)=\phi(x)^T\psi(f) k(x,f)=ϕ(x)Tψ(f)是一种类似self-attention形式的关联性度量。之后使用object-based上下文对信息增强:
z i = g ( [ x i T y i T ] T ) z_i=g([x_i^T\ y_i^T]^T) zi=g([xiT yiT]T)
这里其实就是求取对应像素点的attention权重,与self-attention类似,其核心代码为:
query = self.f_pixel(x).view(batch_size, self.key_channels, -1)
query = query.permute(0, 2, 1)
key = self.f_object(proxy).view(batch_size, self.key_channels, -1)
value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
value = value.permute(0, 2, 1)
sim_map = torch.matmul(query, key)
sim_map = (self.key_channels**-.5) * sim_map
sim_map = F.softmax(sim_map, dim=-1)
# add bg context ...
context = torch.matmul(sim_map, value)
context = context.permute(0, 2, 1).contiguous()
context = context.view(batch_size, self.key_channels, *x.size()[2:])
context = self.f_up(context)
上文中的 ϕ ( ⋅ ) , ψ ( ⋅ ) , δ ( ⋅ ) , ρ ( ⋅ ) , g ( ⋅ ) \phi(\cdot),\psi(\cdot),\delta(\cdot),\rho(\cdot),g(\cdot) ϕ(⋅),ψ(⋅),δ(⋅),ρ(⋅),g(⋅)都是有1*1的卷积+BN+ReLU构建的。
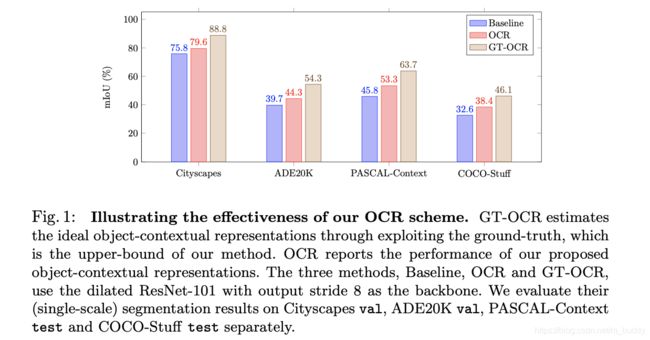
文章将通过coarse分割结果进行OCR与通过GT进行OCR的结果进行比较,其对比见下图所示:
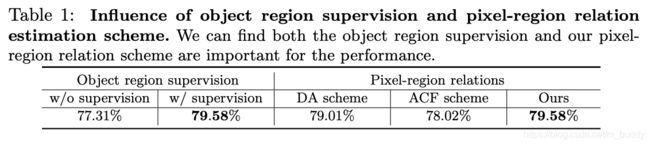
对于该object-based特征优化与简单的附加损失和self-attention机制的增强方式进行比较:
3. 实验结果