姿态估计论文汇总 Stacked Hourglass/CPN/Simple Baselines/MSPN/HRNet
最近阅读了姿态估计领域一些比较重要的论文,写此文记录一下文章的主要思想、网络结构等。
不介绍CPM和Openpose。
题目中的网络结构主要对应下述论文:
Stacked Hourglass-《Stacked Hourglass Networks for Human Pose Estimation》ECCV16
CPN-《Cascaded Pyramid Network for Multi-Person Pose Estimation》CVPR18
Simple Baseline-《Simple Baselines for Human Pose Estimation and Tracking》ECCV18
MSPN-《Rethinking on Multi-Stage Networks for Human Pose Estimation》CVPR19
HRNet-《Deep High-Resolution Representation Learning for Human Pose Estimation》CVPR19
分类
姿态估计分为单人姿态估计和多人姿态估计,多人姿态估计主要有两个方向:Top-down和Bottom-up。
Top-down:先检测人体,再做单人姿态估计的两阶段方法。
Bottom-up:针对整副图像的多人关键点检测,检测所有关键点候选位置的同时,一般会用一定的算法关联或匹配到相关人体。
从网络结构的角度,又可以将姿态估计的方法分为single-stage approch和multi-stage approch。
Single-stage approch都是Top-down,例如:CPN、Simple Baselines
Multi-stage approch可以是Top-down和Bottom-up的,例如:CPM、Stacked Hourglass、MSPN
上述分类来源于MSPN论文。
输出/Ground Truth构建:三类:直接回归关键点坐标;heatmap;heatmap+offset。
下面介绍上述五篇论文:
一.Stacked Hourglass:
网络结构:
 整体的网络结构是由堆叠在一起的Hourglass模块组成,这些Hourglass模块是对称的。
整体的网络结构是由堆叠在一起的Hourglass模块组成,这些Hourglass模块是对称的。
Hourglass 模块: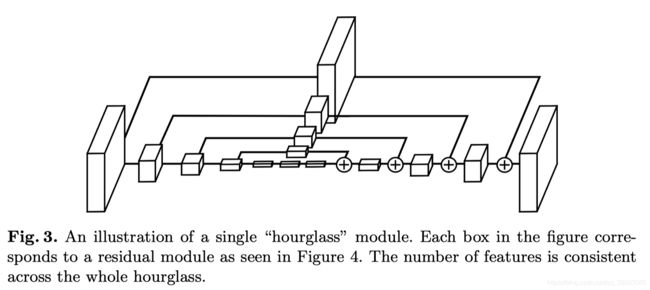
残差块:
Hourglass模块由上面的残差块组成,由于它是一个递归的结构,所以可以定义一个阶数来表示递归的层数,首先来看一下一阶的Hourglass模块:
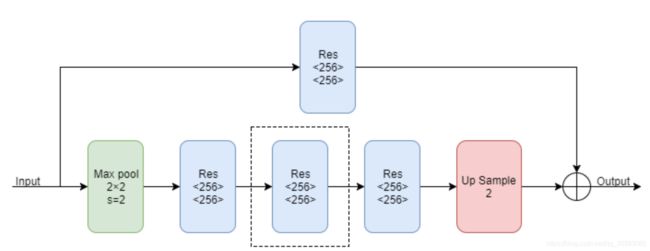
上图中的Max pool代表下采样,Res代表上面介绍的残差块,Up Sample代表上采样(最近邻插值)。多阶的Hourglass模块就是将上图虚线框中的块递归地替换为一阶Hourglass Module,由于作者在实验中使用的是4阶的Hourglass模块,所以我们画出了4阶的Hourglass模块的示意图:
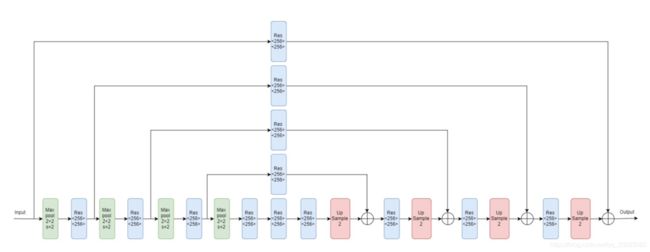
总体网络结构:

Intermediate Supervision(中继监督):
作者在整个网络结构中堆叠了许多hourglass模块,从而使得网络能够不断重复自底向上和自顶向下的过程,作者提到采用这种结构的关键是要使用中继监督来对每一个hourglass模块进行预测,即对中间的heatmaps计算损失。
二.CPN:
网络结构: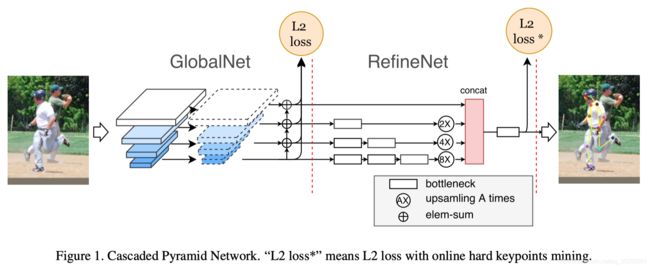
BackBone:采用ResNet作为基础特征网络(ResNet50/ResNet101等);可以理解为上图中输入图像后的箭头。
CPN:
1)参考FPN(Feature Pyramid Networks)设计多层级特征提取网络–GlobalNet;该网络采用L2 Loss作为Loss function。
2)在GlobalNet基础上增加RefineNet,加强对hard keypoint的估计;该网络采用L2 Loss* 作为Loss function。
GlobalNet:
1)采用ResNet的不同Stage的最后一个残差块输出(C2,C3,C4,C5)作为组合为特征金字塔;拿ResNet50来说,当输入大小为1×3×256×192时:
C2 = res2c(1×256×64×48)
C3 = res3d(1×512×32×24)
C4 = res4f(1×1024×16×12)
C5 = res5c(1×2048×8×6)
这样就构成特征金字塔
C2,C3具有较高的空间分辨率和较低语义信息,而C4,C5具有较低空间分辨率和更丰富的语义信息;将他们结合在一起,则即可利用C2,C3空间分辨率优势定位关键点,也可利用C4,C5丰富语义信息识别关键点。
2)然后各层进行1×1卷积将通道都变为256。
3)将分辨率小的层上采样一次,在对应神经元相加,输出P2,P3,P4,P5
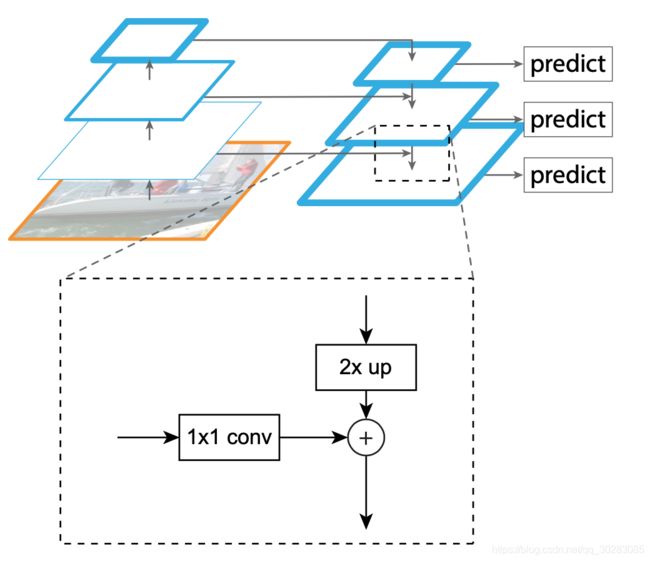
4)输出:对每层,即P2,P3,P4,P5都进行3×3卷积,再生成heatmaps。
RefineNet:
1)对GlobalNet的4层输出P2,P3,P4,P5分别接上不同个数的Bottleneck模块。
2)将这4路输出,上采样到同一分辨率,这里以P2路(64×48)为基础,P3路放大2倍,P4路放大4倍,P4路放大8倍。
3)将4路按通道Concat一起,再接bottleneck,最后接输出层。
RefineNet Loss(L2 loss with online hard keypoints mining):
它与L2是同理的,但是在训练时,动态地将loss值比较大的几个channels进行反向学习;个人理解是RefineNet Loss更加关注loss值比较大的点,而这些点往往就是hard keypoint;实验验证,回传前8个loss效果较好。
三.Simple Baselines:
不介绍论文内的Pose track的工作。
网络结构:
本文仅仅是在ResNet中插入了几层反卷积,将低分辨率的特征图扩张为原图大小,以此生成预测关键点需要的Heatmap。没有任何的特征融合,网络结构非常简单,相较于Hourglass和CPN,较为新颖的点是引入了Deconvolution来替换Upsampling与convolution组成的结构。
四.HRNet:
网络结构:

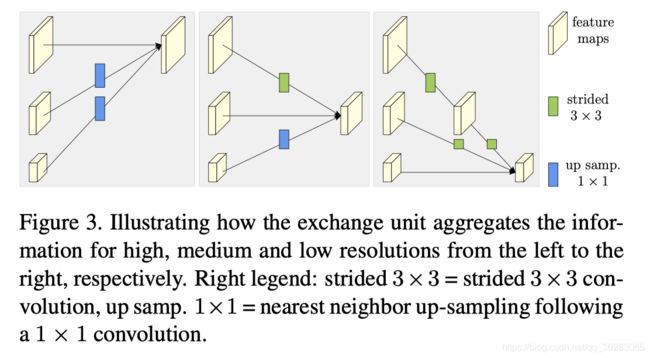
将不同分辨率的feature map进行并联,在并联的基础上,添加不同分辨率feature map之间的交互(fusion),具体fusion的方法如下图所示:
1)同分辨率的层直接复制。
2)需要升分辨率的使用bilinear upsample + 1x1卷积将channel数统一。
3)需要降分辨率的使用strided 3x3 卷积。(卷积在降维的时候会出现信息损失,使用strided 3x3卷积是为了通过学习的方式,降低信息的损耗。所以这里没有用maxpool或者组合池化)
4)三个feature map融合的方式是相加。
 创新点:
创新点:
1)将高低分辨率之间的链接由串联改为并联。
2)在整个网络结构中都保持了高分辨率的表征(最上边那个通路)。
3)在高低分辨率中引入了交互来提高模型性能。
五.MSPN:
网络结构:
 优化单个stage结构:
优化单个stage结构:
在现有的多stage网络中,每个stage在进行特征降采样和升采样时,其通道是保持不变的,而不是像Resnet一样随着特征图的减小会相应的增加通道。这种现象就会导致特征丢失。作者采用CPN的GlobalNet来替换Hourglass中每个stage。使得单个stage的能力变强,规避了特征因为降采样而丢失。
相邻stage特征聚合:
每个stage都会对特征图进行降采样和升采样,多个stage就会反复的进行降采样和升采样,这种反复的操作使得特征信息丢失明显,最终导致网络优化困难。作者将相邻阶段的特征进行聚合,以增强特征信息传播能力并降低训练难度。具体的特征聚合方法如下图所示,对于当前stage的某个降采样过程,其输入包含三个部分。分别为:上个阶段中相同size的降采样特征经过1*1卷积编码后的特征,上个阶段中相同size的升采样特征经过1*1卷积编码后的特征,以及当前stage的降采样特征。
多stage由粗到细监督:
多stage网络的特点是,每个stage的输出都能作为最终的关键点检测结果。而且随着stage的增多,关键点定位会越来越准。为了使得在前端的stage能够获得更好的知道,作者提出了由粗到细的多分支监督的方式来优化多stage的能力。如下图所示,正对于每个stage的特点,采用不同kernel-size的高斯核制作标签,越靠近输入的stage的kernel-size越大。

其他论文后续补充。