Swin Transformer网络模型
文章目录
- 前言
- 网络结构
-
- 整体架构
- Swin Transformer Block模块
- W-MSA
-
- 相对位置编码
- SW-MSA
-
- Mask MSA
- 模型详细配置参数
前言
论文地址:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文代码:https://github.com/microsoft/Swin-Transformer
Transformer从NLP迁移到CV(ViT)上没有大放异彩,是由于几点原因
- 视觉实体规模变化很大,在不同场景下ViT性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大,较为耗时
为此提出2个解决方法
1.引入CNN中常用的层次化构建方式构建层次化Transformer。
2.提出滑窗操作,其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。

所提出的Swin Transformer通过合并更深层的图像块(灰色显示)来构建层次特征图,并且由于只在每个局部窗口(红色显示)内计算自注意,因此对输入图像大小具有线性计算复杂度。因此,它可以作为图像分类和密集识别任务的通用骨干。
网络结构
整体架构

上图是Swin Transformer的整体架构。
架构详解
1.首先,和ViT类似,通过patch partition将输入图片HxWx3划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4。
2.Stage1,将分的块先通过一个linear embedding将输划分后的patch特征维度变成C,然后送入Swin Transformer Block;Stage2到Stage4操作相同,先通过一个patch merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C。
Swin Transformer Block模块

Swin Transformer是通过将变压器块中的标准多头自注意(MSA)模块替换为基于移位窗口的模块,其他层保持不变。一个Swin Transformer由一个基于移位窗口的MSA模块组成,然后是一个中间具有GELU非线性的2层MLP。在每个MSA模块和每个MLP之前应用一个LayerNorm(LN)层,在每个模块之后应用一个残差连接。
W-MSA
W-MSA:Window Multi-headed Self-attention

之前的Vision Transformer(ViT)是对全局都进行注意力机制的计算(如左图所示)。而在论文中作者建议在局部窗口(如右图所示)内计算自注意。这些窗口是以不重叠的方式均匀地分割图像。假设每个窗口包含M×M图像块,全局MSA模块的计算复杂度和基于窗口的计算复杂度:
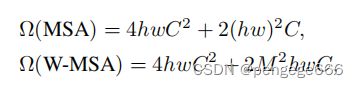
具体公式推导见Swin-Transformer网络结构详解
相对位置编码
在文章的后续实验有证明相对位置编码的加入提升了模型性能。
相对位置编码的详细内容见:Swin-Transformer网络结构详解
SW-MSA
SW-MSA:Shifted Window Multi-headed Self-attention
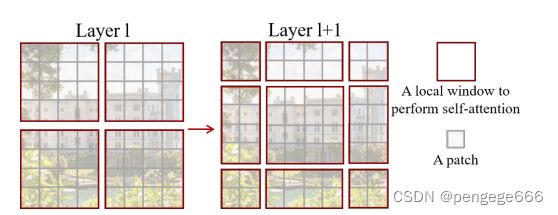
红色框的叫做一个local window,灰色框的叫一个patch。我们在每一个local window中计算self-attention。如果是只计算一次self-attention,每个local window之间是没有联系的,但是有关联才对。因此层l+1在层l给出了新的划分关系,可以很好的将未联系的块建立联系。但是,这么划分的话就有9个块了,较为耗时。
因此作者提出了shifted-window进行了第二次self-attention。

这里,我们将标有数字的列作以下操作(操作部分可以参考SW-MSA):循环上移,在循环左移,最后变成如上所示的上层图片。变化之后的图像块有些是没有联系关系的。图中将具有联系关系的用黄色框标出,紫色框标出那些没有联系的框。
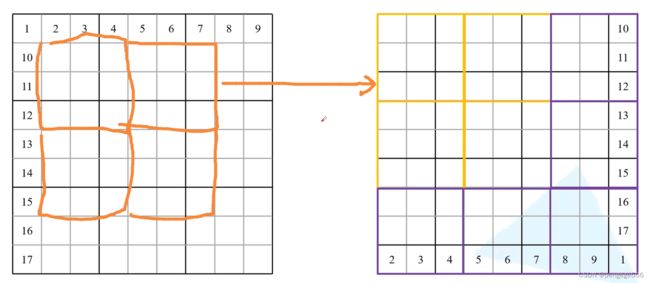
为了更好得到看出滑窗操作后能将之前未建立联系的图像块之间建立联系,因此用橙色的框标出了移动后所建立的联系,正好对应右图的黄色框部分。这样操作后就可以将原先分隔开的区域进行计算,建立联系。
Mask MSA
由于移动后一些块就不连续了,因此有些地方的注意力不应该计算,因此引入了Mask MSA,论文中也给出了相应的图示。
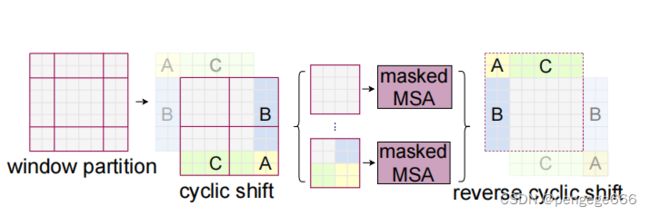
但由于论文中的图示较为简单,这里总结一下这块的学习。
首先我们对Shift Window后的每个窗口都给上编号,并且做一个roll操作,如下图所示。

我们对每个块都计算自注意力(上图右图共4个分块),计算过程如下图所示。

我们只需要将网格中标有颜色的数字的位置加入注意力计算。其他的灰色方格之间是不存在联系的,因此无需加入计算。
模型详细配置参数

原论文中给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large)
- win. sz. 7x7表示使用的窗口(Windows)的大小
- dim表示feature map的channel深度(或者说token的向量长度)
- head表示多头注意力模块中head的个数
参考文献
Swin Transformer对CNN的降维打击
SW-MSA
图解swin transformer
Swin-Transformer网络结构详解