机器学习数据集处理:用Python筛除无法读取、边长过小的图片
毕设题目是火焰识别,利用CNN去做,最近一直在网上搜罗常用的数据库,翻了一大堆英文论文,GitHub码云都试过,无奈老是卡在下载速度过慢上。。。。
可做训练不能没有数据集啊!!!
无奈打算从网上爬,无奈乘2自己写的代码老是报错,最后用了大佬的一个代码,原文出处:
https://blog.csdn.net/qq_40774175/article/details/81273198
大佬就是大佬,代码秒过,但爬下来的数据有一些问题:
(1)总有一些与主题无关的图片混了进来
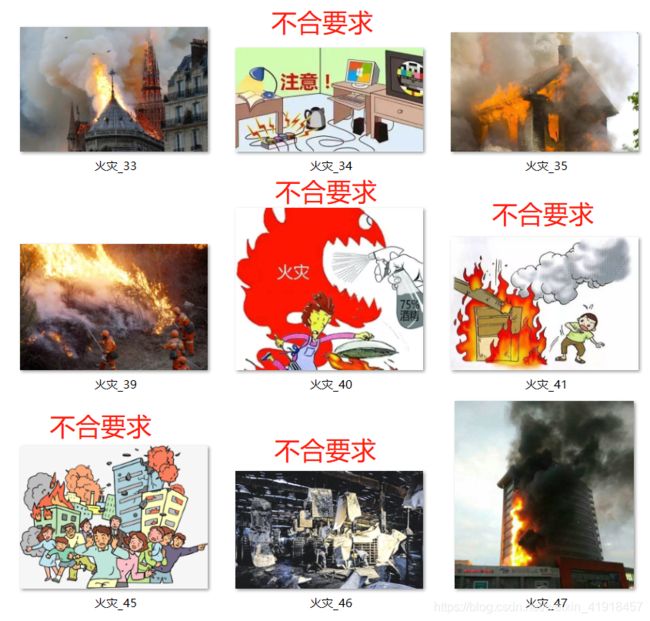
(2)我们知道2242243的图片是训练常用的一种规格,但文件夹里面的预览很难肉眼发现边长小于224的文件一个一个看又太费劲

(3)有一些图片因为下载出问题读取失败

咋办呢?
对于**(1),只能肉眼去筛,爱莫能助**(谁让我选则自己爬度娘的)
对于**(2)和(3),我决定自己写个程序筛掉不符合要求的图**
废话结束,正文开始,有需要可以直接复制这个程序~~
import tensorflow as tf
import cv2#用里面的imread函数,获取图像大小
import os#用里面的删除、重命名、路径合成函数
import shutil#用里面的移动文件函数
import random
#path='./target'#制定了一个当前文件夹
#trashcan='./trashcan'
'''
输入待筛查文件夹路径,垃圾桶路径,指定的图像边长
函数自动筛除文件夹下不符合要求的图片
'''
def sift_image(path,trashcan,size):
image=tf.gfile.ListDirectory(path)#罗列其下所有文件的名称
total=len(image)#算一下文件里的图像个数
num_size=0#因为尺寸大小被删除的图片数
num_channel=0#因为通道大小被删除的图片数
num_read=0#因为无法读入被删除的图片数
for i in range(total):
old_path=os.path.join(path,image[i])#合成原始相对路径
real_path=os.path.join(path,str(i+random.uniform(0,1))+'.jpg')#生成不带中文名的新路径,否则imread读不出来
os.rename(old_path,real_path)#将可能带有中文的原始路径重命名成数字编号,如 162.jpg
img=cv2.imread(real_path) #读图
try:
s=img.shape #我试了好几次,如果读图失败会在这一步报错,所以干脆顺水推舟,来个except语句删掉读不了的图,反正读不了的也是损坏的
except:
print('图像: %s 读取失败,已移入垃圾桶'%image[i])#读不了,自觉进入垃圾桶
shutil.move(real_path,trashcan)
#os.remove(real_path)
num_read+=1
continue
height=s[0]
width=s[1]
channel=s[2]
if (height<size)or(width<size):#长宽不合要求,自觉进入垃圾桶
shutil.move(real_path,trashcan)
#os.remove(real_path)
print('图像: %s 某一边长小于224,已移入垃圾桶'%image[i])
num_size+=1
elif channel !=3:#通道不合要求,自觉进入垃圾桶
shutil.move(real_path,trashcan)
#os.remove(real_path)
print('图像: %s 非3通道图像,已移入垃圾桶'%image[i])
num_channel+=1
print('共读取 %d 张图像'% total)
print('其中 %d 张图像被移入垃圾桶'% (num_read+num_size+num_channel))
print('读取失败 %d 张,已移入垃圾桶'% num_read)
print('已移入垃圾桶边长不符合要求的图像 %d 张'%num_size)
print('已移入垃圾桶通道不符合要求的图像 %d 张'%num_channel)
order=input('确定删除这些文件吗?是:敲 Y / 否:任意键:')
if order=='Y':
trashcan_list=tf.gfile.ListDirectory(trashcan)
for delete in trashcan_list:#罗列其下所有文件的名称
os.remove(os.path.join(trashcan,delete))
print('共%d张不合要求文件删除完成,感谢使用' % len(trashcan_list))
else :
print('放弃删除,感谢使用')
注:
(1)已经封装成函数,懒得看原理(也没多难~)可以直接import进主函数脚本,带入path和trashcan自动筛除
(2)一开始的版本没有trashcan这个设计,又来想想万一以后手残把路径指定错了把数据库删了咋办???保险起见放了个trashcan,和咱桌面的回收站一样,给你二次选择的权利。
(3)我承认我比较懒,没在程序里建trashcan文件夹,所以需要大家自己建一个trashcan文件夹,或者直接指定一个文件夹当垃圾桶,另外注意trashcan文件夹下最好不要有其他文件,尤其是文件夹,否则会报错。
(4)target路径随意指定,绝对路径和相对路径都可以,但切记相对路径不要有中文!否则imread会报错!(如果使用绝对路径的话绝对路径整体一个汉字都不能有,但如果相对路径就不存在这个问题,所以推荐使用相对路径)
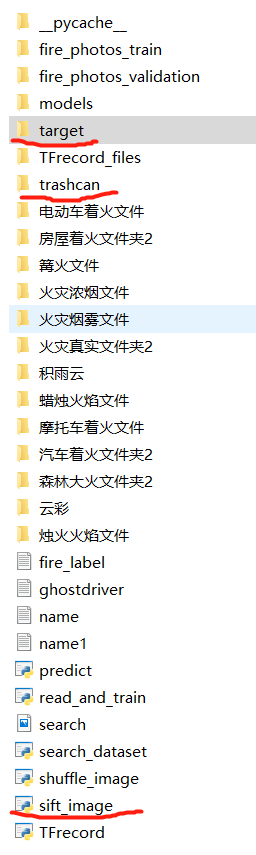
给大家看一下我的文件路径,sift_image就是我封装的这个函数文件,为了方便演示我把这仨文件(夹)都制定在相同目录下了~
最后我们来看一下运行效果:
(2)开始爬下来的文件一群没法读的
(2)新建脚本,import这个函数,运行以下代码
import sift_image as sift
path='./target'
trashcan='./trashcan'
sift.sift_image(path,trashcan)
(3)运行结果,此时所有不合格图片都被扔到trashcan里

(4)我们打开trashcan看一下,里面全都是打不开或者某个边长小于224的图片
(5)点开一个验证一下,选第一行的图4看看~,果不其然

(6)在交互页面输入Y删除这些图片,清空垃圾桶

(7)再看看垃圾桶,果然啥都没了~
当然如果你误删了某个数据库直接来这儿找也行,所以敲Y之前最好先审一遍别删错了~
ps:
筛完了图片,又发现一个问题,我把几个存不同类别的文件夹都混在一起后(开始按关键字从度娘上爬,但我想汇总成一个更大的数据集),图像都是按顺序放的(字母顺序排序,所以类别没变),所以会涉及到分验证集怎么随机抽取图片的问题。解决方案也是写了个小程序,直接打乱顺序,代码如下:
import random
import tensorflow as tf
import os
#path='./target'
'''
允许按类别批量命名图片,便于字符串匹配
'''
def shuffle_image(path):
image=tf.gfile.ListDirectory(path)#读取路径下全部图片名称,写入列表image
random.shuffle(image)#把image列表顺序打乱
kind=input('请输入类别名称:')
num=0
for i in image:
old_path=os.path.join(path,i)#生成完整的原始路径
new_path=os.path.join(path,kind+'.'+str(num)+'.jpg')#
os.rename(old_path,new_path)#重命名
num+=1
print('共检索到 %d 张图片'%len(image))
print('洗牌完成!')
print('感谢使用!')
这个很简单不详细讲了,方法也比较笨(手动狗头)。代码封装好了,同样可以被import进你想要的脚本~
——————————————————更新线:20年3月4日———————————————————
实际应用中发现代码有一些不必要的计算,优化了一下。
目前显示的V2版本更新如下:
(1)减少了 sift 文件的代码量
(2)允许 shuffle 文件对指定文件夹下的图片批量命名