Augmented semantic feature based generative network for generalized zero-shot learning
Accepted 14 April 2021(Neural Networks)
目录
-
- 1.摘要
- 2.思想
- 3.创新与贡献
- 4.增强语义
-
- 4.1 学习拓展语义性
- 4.2 可见类语义增强
- 4.3 不可见类语义增强
- 5.视觉特征生成
-
- 5.1 VAE模块
- 5.2 WGAN 模块
- 5.3 模式崩溃缓解模块
- 5.4 特征可分离约束模块
- 6.实验
-
- 6.1 GZSL
- 6.2 ZSL 设置下的 Top-1 准确度
- 6.3 数据集 CUB 和 SUN 消融实验结果
- 7.总结
1.摘要
零样本学习 (ZSL) 旨在在没有可用于对象类的训练数据时识别图像中的对象。在广义零样本学习(GZSL)设置下,测试对象属于可见或不可见类别。
在最近的许多研究中,零样本学习是通过利用生成网络从特定类别的语义特征中合成看不见的类别的视觉特征来执行的。用户定义的语义信息不完整,缺乏可辨别性。然而,大多数生成方法直接使用用户定义的语义信息作为生成模型的约束条件,这使得模型合成的视觉特征缺乏多样性和可分离性。
在本文中,我们提出了一种利用判别性视觉特征来改善语义特征的新方法。此外,构建了一种新颖的基于增强语义特征的生成网络(ASFGN)来合成看不见的类的可分离视觉表示。由于基于 GAN 的生成模型可能会出现模式崩溃,我们提出了一种新的崩溃缓解损失来提高我们生成网络的训练稳定性和泛化性能。
2.思想
在生成方法中,使用语义信息作为约束来生成视觉特征。语义信息由专家人工定义或从利用基于类别标签的词嵌入网络获得的辅助数据集中自动提取。因此,关于类的描述是有限的和不完整的,这可能不足以区分不同的类别
此外,还存在视觉特征空间和语义空间的不一致。然而,图像可能包含更多的区分信息来分类不同的类别。
我们提出了一种利用图像特征来改进语义特征的方法。利用视觉特征得到每个类的扩展语义属性向量。然后,可以通过特征选择策略得到去噪后的语义属性向量。通过将扩展语义属性向量与去噪语义属性向量连接,可以获得语义增强属性向量。增强的语义属性向量更完整,更具判别力。使用这样的语义属性向量作为生成方法的语义约束,我们为看不见的类别合成更多样化和可分离的视觉特征样本。
GANs 网络可能会遇到模式崩溃的问题。因为生成方法通常使用高维和结构化数据(例如语义属性或文本描述)作为约束,这使得生成器很可能忽略与多样性相关的潜在代码(随机噪声向量)。
在实验中观察到,当模式崩溃发生时,具有高相似性的噪声向量更有可能崩溃成相同的模式。
具体来说,我们直接惩罚两个噪声向量的相似度与对应的合成视觉特征向量的相似度的比率。
3.创新与贡献
1.提出了一种语义增强方法。图像特征中的判别信息用于学习更正确的类间关系并删除用户定义的语义特征上的冗余属性。基于上述操作,提高了类特定语义特征的完整性和区分度,进一步减少了语义空间结构与视觉空间结构的不一致性。
2.设计了一种基于增强语义特征的生成网络(ASFGN),它以增强语义特征作为生成网络的约束条件,合成未见类的视觉特征。合成的视觉特征分布显示出更少的重叠和更清晰的分类决策边界。
3.提出了一种新的崩塌缓解损失。通过惩罚两个噪声向量的相似度和相应的合成视觉特征向量的相似度的比率,collapse-aleviate loss 进一步提高了我们模型的训练稳定性和泛化性能。 GZSL 和传统 ZSL 的大量实验表明,我们提出的方法优于最先进的方法,并有显着改进
4.增强语义
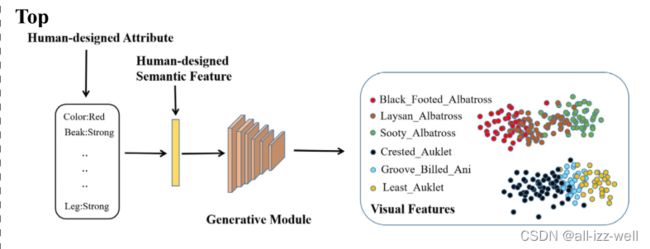
语义属性特征作为生成模型的约束来合成视觉特征
基线方法(上)和我们的方法(下)的比较。我们的方法合成的视觉特征更容易分类

本文的模型如下:

SA中视觉特征通过视觉语义嵌入网络投影到语义属性空间和扩展属性空间中。语义属性用于学习不同类别之间的共享属性,而扩展属性用于通过调节类间/类内距离来学习潜在语义信息

在 GM 中,增强的语义特征被输入到生成网络中以合成视觉特征。为了确保生成器(G)合成有意义的视觉特征,一个预训练的分类器(C)用于计算更新生成器(G)的参数的 Lossc
4.1 学习拓展语义性
由于专家定义的语义属性所描述的类内和类之间的关系不足以识别不同的类,因此使用这些语义属性作为生成模型的条件约束合成的视觉特征的可辨性不足。我们假设具有相似视觉特征的类别具有更高的语义相关性,因此可以从所见类的视觉特征中学习更恰当的类间语义关系
受度量学习方法的启发,我们使用三重损失来捕捉类间/类内的关系。并将学习到的语义关系特征视为扩展的语义属性。图像的视觉特征通过视觉语义嵌入网络投影到用户定义的语义属性 Ψa(x) 和扩展语义属性 Ψlat(x) 中。我们同时进行视觉语义投影和视觉潜在投影,并同时优化它们。对于视觉-潜在投影,三重损失用于通过同时增加类间距离和减少类内距离来学习扩展语义属性 Ψlat(x)。以下损失用于更新权重 Wlat ,xr 和 xs 是来自同一类的图像,xt 来自另一个类

4.2 可见类语义增强
对于每个图像xi∈Xs,可以通过上述方法获得扩展语义属性Ψlat(x)。为了获得每个类别 ys 的扩展语义属性 aaug(ys),我们需要将 ys 的扩展语义属性与其无冗余语义 ^a(ys) 连接起来。对于每个类 ys,类扩展语义属性是所有图像的扩展语义属性的平均值
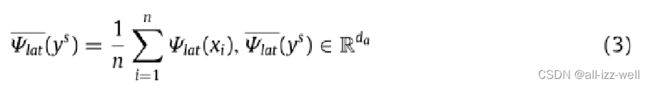
a(ys) 中有冗余的语义属性。我们使用特征选择来获得更具区分性和代表性的类级语义特征 ^a(ys)。我们计算属性激活值并将属性激活值用于特征选择。对于每个看到的类,为了避免噪声样本的影响,其原型投影语义向量计算如下

其中 nb 表示具有相同标签 a(ys) 的样本数,xi 是图像特征。由于 Ψpro(ys) 是通过对所有 Ψa(x) 进行平均获得的,因此 Ψpro(ys) 可能包含标签 ys 的丰富视觉信息。我们利用隐含在 Ψpro(ys) 中的判别性视觉信息来帮助我们从用户定义的语义特征中选择特殊属性。这些特殊属性与特定类的视觉特征高度相关。
步骤如下。 (i) 通过计算每个看到的类的 Ψpro(ys) 和 a(ys) 的元素乘积,得到 a(ys) 中所有属性的激活值。 (ii) 一个属性的激活值越大,该属性与该类的视觉信息的相关性就越大。所以我们应该将激活值高的属性保留在 a(ys) 中。 (iii) 选择激活值高的 Top t 属性形成 ^a(ys)。增强语义特征 aaug(ys) 可以通过合并每个看到的类的 ^a(ys) 和 Ψlat(ys) 来获得

4.3 不可见类语义增强
为了获得未见类的扩展语义向量,我们在专家定义的语义属性空间中计算未见类与所有已见类之间的相似度值向量。然后,未见类别的扩展语义特征是扩展语义特征对已见类别的线性加权组合。对于每个未见过的类,其与所有已见类的相似度由以下等式计算
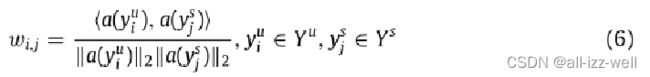
我们设置相似度阈值μ,并选择相似度值大于阈值μ的已见类计算未见类i的潜在扩展原型向量。计算公式如下

由于未见类没有视觉特征,我们不能使用上述为已见类设计的属性选择方法。在这里,我们使用未见类和已见类的语义属性相似度来计算属性选择系数。然后,利用属性选择系数对未见过的类的自定义语义特征进行特征选择操作。在上一步中,对于每个未见过的类,选择 nv 个见过的类。设这些选定的可见类的去噪语义特征的集合为 T , T = {^a(ys1), ^a(ys2),., ^a(ysnv )}。在用户定义的 unseen 类中,我们假设如果第 k 维属性在集合 T 的语义特征中出现的频率更高,则第 k 维属性越重要。因此,对于未见过的类 i,第 k 个属性的特征选择系数由下式计算

对于每个未见过的类,可以通过合并 ^a(yu) 和 Ψlat(yu) 来获得增强的语义特征

5.视觉特征生成
5.1 VAE模块
我们使用 VAE 和 WGAN来生成视觉特征,在我们的模型中VAE 的解码器(DC)和 WGAN 的生成器(G)共享相同的网络参数。特征生成器 VAE 包含一个编码器 E(x, aaug(ys)),它将输入图像特征 x 转换为视觉潜在分布 Z。通过对 Z 进行重采样得到潜在向量 z。 DC(z) 输出重建的视觉向量 xre。编码器和解码器的参数由以下损失函数更新
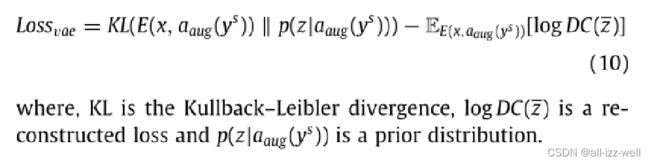
5.2 WGAN 模块
WGAN 模块包含一个生成器(G)和一个鉴别器(D)。生成器(G)合成视觉特征 ^xs。一个随机高斯噪声n和增强语义向量aaug(ys)是G的输入。随后,视觉特征和语义特征被输入到D中,其中视觉特征包括真实视觉特征和合成视觉特征,而D的输出可以判断视觉特征是真实的还是合成的。生成器(G)和判别器(D)的参数由损失函数Losswgan更新

5.3 模式崩溃缓解模块
对于生成式 ZSL 任务,其中模型的约束是高维和结构化的,而不是噪声向量。因此,生成器可能专注于结构化语义特征而忽略噪声向量。然而,合成样本的多样性与随机噪声向量有关。
具体到我们的案例,我们的目标是为看不见的类合成不同的视觉特征。一旦发生模式崩溃,生成器可能会输出单模式视觉特征,这与我们的预期目标背道而驰。
我们提出了一种缓解模型崩溃的方法,将两个相似度高的噪声向量输入生成器,然后让生成器合成两个相似度低的视觉向量。在每个训练批次中,从标准高斯分布中提取两个随机噪声向量 n1 和 n2。这两个随机噪声分别与一个语义特征级联,然后输入到生成器中合成两个视觉特征向量 ^x1,F 和 ^x2,F 。损失函数计算如下
其中,cossim(x, y) 是向量 x 和 y 的余弦相似度。由于分母可能为 0,我们添加一个小的 δ,其中 δ 设置为 1e-7

当两个噪声高度相似时,优化器会强制生成器合成相似度低的视觉特征以获得较小的损失值,从而使合成的视觉特征更加多样化
5.4 特征可分离约束模块
为了确保生成器合成可分离的视觉特征,由所见类训练的 softmax 分类器用于鼓励生成器合成可分离的视觉特征。分类器的损失由以下公式计算

6.实验
6.1 GZSL

6.2 ZSL 设置下的 Top-1 准确度

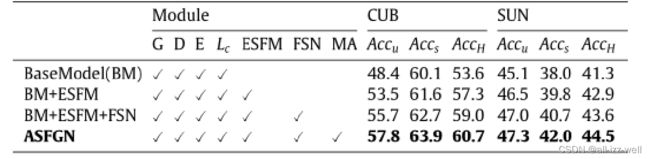
6.3 数据集 CUB 和 SUN 消融实验结果
7.总结
1.在这项工作中,我们提出了一种基于增强语义特征的生成网络来解决广义零样本分类问题。
2.利用判别性的视觉特征,获得每个可见类和未见类的扩展语义特征和去噪语义特征。
3.我们通过连接扩展语义特征和去噪语义特征来获得增强的语义特征。随后,将增强的语义特征作为条件约束输入到生成模型中,以合成未见类别的视觉特征。
4.为了缓解 GAN 模式崩溃并提高模型的训练稳定性,提出了一种新的崩溃缓解损失。
5.实验表明,合成的视觉特征更加多样化和区分度更高,我们的模型优于最先进的方法。