Cross-class generative network for zero-shot learning:用于零样本学习的跨类生成网络
Accepted 23 December 2020(Information Sciences)
目录
-
- 1.摘要
- 2.思想
- 3.创新与贡献
- 4.跨类样本合成
-
- 4.1 配对选择
- 4.2 类内熵
- 4.3 跨类生成网络
- 5.NACGN 与 ACGN
-
- 5.1 NACGN(非对抗性跨类生成网络)
- 5.2 ACGN(对抗性跨类生成网络)
- 6.实验
-
- 6.1 ZSL
- 6.2 GZSL
- 6.3 可视化
- 6.3 aPY 中前 4 个相似的可见类和不可见类,NACGN 和 ACGN 之间准确度比较
- 7.总结
1.摘要
解决 ZSL 的传统方法是生成不可见类的样本,将其转换为监督任务。然而,这些伪样本的质量对于模型性能至关重要。
在本文中,我们提出了一个新的网络,称为跨类生成网络,它包括两个新的端到端模型,为看不见的类生成高质量的样本。与以前的工作不同,我们提出的模型通过可见类的样本直接生成未见类的样本。结果,生成的样本与真实样本的分布更相似。
此外,我们提出了一个类内熵来衡量选择合适的源-目标对的差异程度。据我们所知,这种类内熵是首次在 ZSL 中提出。我们的模型包括两个版本,非对抗性和对抗性模型,以支持和探索不同的场景。我们对五个基准数据集进行了广泛的实验。
与最先进方法的全面比较表明我们提出的模型的优越性
2.思想
生成伪样本的新方法:我们观察到每个类都分布在视觉空间的特定子空间中,我们认为将可见类从其原始子空间转移到未见类的子空间是生成伪样本的合理方法。转移的样本可以看作是目标样本,以达到生成样本的目的(本文称为跨类生成)。我们的方法在 ZSL 和 GZSL 设置下都有效地生成了新样本,并且可以直接从可见的样本中生成未看到的样本。
此外,我们设计了两个版本的跨类样本生成模型:非对抗性跨类生成网络(NACGN)和对抗性跨类生成网络(ACGN)。前者采用编码器-解码器结构,而后者遵循标准的生成对抗网络(GAN)和生成器-鉴别器结构。
在训练阶段,模型将源样本作为输入和输出目标样本,在属性的帮助下,源样本和目标样本都属于可见类。由于关键思想是从源类生成目标类,因此选择源-目标对在提高生成性能方面起着至关重要的作用。
因此,我们提出了两个层次的选择策略:类和样本。对于类选择,我们采用类图来衡量类间相似性,作为贡献,我们提出了类内熵来衡量所见类的差异程度。类内熵可以衡量一个所见类中所有样本中最相似样本的分布,最初是为了分析我们所知道的 ZSL 的差异程度而提出的。
样本选择:使用余弦距离来测量样本相似度以进行样本选择。训练结束后,我们以已见类的样本为源,生成未见类的目标样本。因此,我们可以通过使用这些生成的样本搜索最近的标签,将 ZSL 转移到监督任务中。
3.创新与贡献
1.本文提出了一种生成伪样本的新方法。我们的方法生成跨不同类的样本。我们的方法不同于以前使用噪声生成样本的方法。使用来自源域的样本而不是噪声分布来生成新样本。因此,我们生成的样本可能更类似于真实样本。
2.我们设计了两个生成框架,包括非对抗和对抗版本,以实现跨类样本生成。我们的方法可以有效地生成与真实样本相似的合理样本。
3.为了衡量类内差异程度,我们基于信息熵理论提出了一种新的评估标准,类内熵。对于一类的所有样本,它测量它们最相似的样本的分布。据我们所知,这是 ZSL 中提出的第一个用于差异测量的标准。
4.我们对五个基准数据集进行了综合实验,以验证我们方法的优越性,并证明我们提出的跨类生成模型在处理 ZSL 和 GZSL 问题方面是有效的。
4.跨类样本合成
4.1 配对选择
考虑到源-目标对的选择对于跨类生成至关重要,我们在类和样本级别上设置了选择规则,配对选择涉及选择合适的源-目标配对,这有两个含义:在训练和推理阶段的配对选择以及在类和样本级别的配对选择。
在训练阶段,我们从类和样本级别的已见类中选择匹配的源和目标。由于在推理阶段无法获得未见类的标记样本,我们仅选择合适的已见类作为未见类的源来生成目标样本。
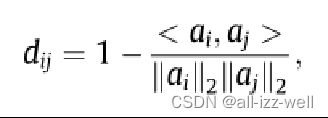
在类层面,类间相似度是对选择的关键因素,用余弦距离来衡量类间距离
ai 和 aj 分别是类 ci 和 cj 的属性向量

为了更有效地建立类关系,我们使用类图:定义为语义空间中的加权二分图。每个类(由语义向量表示)是类图中的一个节点,加权边表示类之间的关系
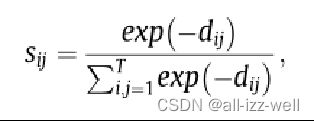
使用 sij 来衡量类间相似度,其中高 sij 意味着高类间相似度。对于目标类,我们选择相似度大的类作为源。因为所有的类属性都是可用的,所以可以通过类图选择每个目标类对应的源类。在样本层面,我们还使用余弦距离来衡量每个样本之间的相似度。特别是,样本选择仅在训练阶段实施,以更好地训练后续的端到端跨类生成网络。
4.2 类内熵

源类是从与目标类具有较大相似度的类中选择的。一个简单的方法是为每个目标类选择最相似的类作为源类。观察可见类我们注意到一个类内样本之间的分布不平衡和较大的差异,假设与图中的蓝鲸最相似的样本分布在一个以上的类中。考虑到样本差异,选择最相似的类作为源类是不够的。
因此,我们提出了基于熵理论的类内熵来衡量样本差异程度。随后,我们使用相对类内熵来确定源类的数量。提出了类内熵来测量可见类中的样本差异。首先,我们为 ci 类中的每个样本搜索最相似的样本。最相似的样本分布在 nsim i 类中。接下来,类 ci 的类内熵定义为
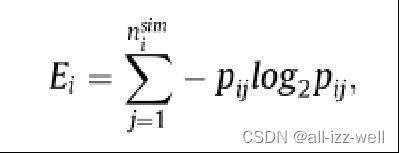
其中 pij ≥ 0 是表示 ci 的最相似样本中有多少样本属于 cj 的百分比
高熵值意味着类中的高样本差异度。对于差异较大的类,选择更相似的类作为其源类。此外,为了测量 ci 类与数据集中所有可见类相比的相对差异程度,我们通过等式计算相对类内熵 REi。
这里,minE 是所有看到的类的最小 Ei 值
在本研究中,每个目标类的最大源类数设置为 max RE,随后,我们还计算总类内熵来衡量整个数据集的差异程度值高表示数据集的差异程度大。
4.3 跨类生成网络
对于跨类样本生成,我们设计了两个生成模型(包括非对抗和对抗版本)来支持和探索不同的场景。
非对抗版本是对抗网络的一个子模块。两者都是从源类生成目标类样本的端到端模型,唯一的区别在于是否添加了判别器。在训练阶段,在类属性的引导下,源样本作为目标样本进行迁移。
在生成网络中建立了跨类样本生成规则。未见类的样本可以从已见类中生成。
随后,生成的样本被用作训练数据来识别看不见的类别。
5.NACGN 与 ACGN
5.1 NACGN(非对抗性跨类生成网络)

由于源和目标之间的域差距很大,需要更强的约束来确保网络学习到更合理的传输规则。由于同一类的样本在特征空间中以簇的形式分布,因此生成的高质量样本的簇应该与真实样本的簇有显着的重叠,可以通过中心距离来衡量。因此,我们在目标中添加了一个中心正则化项,定义

5.2 ACGN(对抗性跨类生成网络)
 ACGN总的目标函数为
ACGN总的目标函数为
与方程式中的 NACGN 损失相比
通过添加鉴别器,ACGN生成的样本可以更接近真实样本。对抗性架构确保生成的样本更好地拟合真实样本。但训练难度大,训练阶段收敛时间较慢。总之,我们提出了两个生成模型来生成跨类的样本。在推理阶段,我们从选定的已见类别的样本中生成未见类别的样本。接下来,我们训练未见类的分类器以识别 ZSL 中的未见类。
6.实验
6.1 ZSL

CCSS 是我们工作的初步版本;我们将其列在表中以更好地说明本研究中取得的改进。结果清楚地表明,我们提出的方法在三个数据集(AWA1、AWA2 和 aPY)上优于其他方法,在其他情况下排名第二。 GAZSL具有竞争性能,尤其是在 SUN 和 CUB 上。它也是一种生成方法,可以生成看不见的类样本来解决 ZSL。然而,它使用噪声来生成样本,这可能会导致比我们的方法更严重的域偏移问题(使用可见样本直接生成不可见样本)。特别是,我们的方法在 AWA2 数据集上的性能优于 GAZSL 约 11%。在 ZSL 中,我们提出的方法通常表现出优越的性能。
6.2 GZSL

6.3 可视化

6.3 aPY 中前 4 个相似的可见类和不可见类,NACGN 和 ACGN 之间准确度比较


7.总结
1.在本文中,我们为 ZSL 提出了一种新颖的网络,称为跨类生成网络,包括两个端到端模型。与之前基于生成模式的工作不同,我们的端到端模型可以通过可见样本直接生成不可见类的伪样本,并获得更好的性能。
2.此外,我们采用类图和类内熵来选择源-目标对来生成样本。在 ZSL 和 GZSL 设置下的大量实验表明我们的模型在五个公共数据集上的优越性。
3.此外,我们进行了综合分析(包括准确性比较、t-SNE 可视化和最近邻匹配),以客观直观地衡量我们方法的有效性。
4.结果证明,所提出的跨类生成网络在处理 ZSL 时表现出不错的性能