C语言学习专栏(1):易忘点
C语言学习专栏系列:
【版权申明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权);
本博客的内容来自于:C语言学习专栏(1):易忘点;
学习、合作与交流联系q384660495;
本博客的内容仅供学习与参考,并非营利;
include< > 与 #include ""的区别:
- < > 表示系统直接按系统指定的目录检索;
- “” 表示系统先在 “” 指定的路径(没写路径代表当前路径)查找头文件,如果找不到,再按系统指定的目录检索;
main函数
- 一个完整的 C 语言程序,是由一个、且只能有一个 main()函数(又称主函数,必须有)和若干个其他函数结合而成(可选)。
- main 函数是 C 语言程序的入口,程序是从 main 函数开始执行。
C语言编译过程
- 预处理:宏定义展开、头文件展开、条件编译等,同时将代码中的注释删除,这里并不会检查语法 ;
- 编译:检查语法,将预处理后文件编译生成汇编文件;
- 汇编:将汇编文件生成目标文件(二进制文件);
- 链接:C 语言写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终的可执行程序中去;

静态库与动态库
- 静态库与动态库都是链接阶段的步骤。静态库(.a、.lib)和动态库(.so、.dll)。
- 静态库编译期间打包到可执行文件中,而动态库是执行时才被载入。
- 动态库规避了空间浪费和静态库在更新、部署和发布带来的麻烦。不同程序调用相同的动态库,内存中只需要保存一份实例。
- 静态库和动态库的最大区别,静态情况下,把库直接加载到程序中,而动态库链接的时候,它只是保留接口,将动态库与程序代码独立,这样就可以提高代码的可复用度,和降低程序的耦合度。
- 动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此在程序运行时还需要动态库存在。静态库在程序编译时被连接,运行时不再需要。
声明与定义
一般的情况下,把建立存储空间的声明称之为“定义”,而把不需要建立存储 空间的声明称之为“声明”。直接为声明赋值会报错。
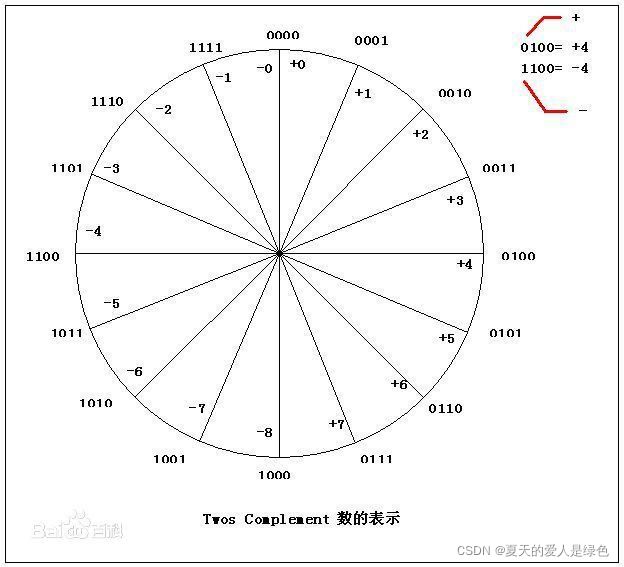
原码、反码与补码
在计算机系统中,数值一律用补码来存储,主要原因是:
- 统一了零的编码
- 将符号位和其它位统一处理
- 将减法运算转变为加法运算
赋值表达式的返回值
注意,赋值表达式有返回值,等于等号右边的值。变量y的值就是赋值表达式(x = 2 * x)的返回值2。赋值变量符是从右向左执行。
除法注意事项
- C 语言里面的整数除法是整除,只会返回整数部分,丢弃小数部分。
- 如果希望得到浮点数的结果,两个运算数必须至少有一个浮点数,这时 C 语言就会进行浮点数除法。
连续运算符
i < j < k
上面示例中,连续使用两个小于运算符。这是合法表达式,不会报错,但是通常达不到想要的结果,即不是保证变量j的值在i和k之间。因为表示运算符是从左到右计算,所以实际执行的是下面的表达式。
(i < j) < k
python是可以这样判断的
浮点数判断大小
注意,由于存在精度限制,浮点数只是一个近似值,它的计算是不精确的,比如 C 语言里面0.1 + 0.2并不等于0.3,而是有一个很小的误差。
bool类型
C99 标准添加了类型_Bool,表示布尔值。但是,这个类型其实只是整数类型的别名,还是使用0表示伪,1表示真。
头文件stdbool.h定义了另一个类型别名bool,并且定义了true代表1、false代表0。只要加载这个头文件,就可以使用这几个关键字。
#include 字面值的类型
一般情况下,十进制整数字面量(比如123)会被编译器指定为int类型。如果一个数值比较大,超出了int能够表示的范围,编译器会将其指定为long int。如果数值超过了long int,会被指定为unsigned long。如果还不够大,就指定为long long或unsigned long long。
unsigned int里面的int可以省略,所以上面的变量声明也可以写成下面这样。
unsigned a;
字符类型char也可以设置signed和unsigned。
signed char c; // 范围为 -128 到 127
unsigned char c; // 范围为 0 到 255
注意,C 语言规定char类型默认是否带有正负号,由当前系统决定。这就是说,char不等同于signed char,它有可能是signed char,也有可能是unsigned char。这一点与int不同,int就是等同于signed int。
溢出
每一种数据类型都有数值范围,如果存放的数值超出了这个范围(小于最小值或大于最大值),需要更多的二进制位存储,就会发生溢出。大于最大值,叫做向上溢出(overflow);小于最小值,叫做向下溢出(underflow)。
一般来说,编译器不会对溢出报错,会正常执行代码,但是会忽略多出来的二进制位,只保留剩下的位,这样往往会得到意想不到的结果。
unsigned int i = 5;
unsigned int j = 7;
if (i - j < 0) // 错误
printf("negative\n");
else
printf("positive\n");
上面示例的运算结果,会输出positive。原因是变量i和j都是 unsigned int 类型,i - j的结果也是这个类型,最小值为0,不可能得到小于0的结果。正确的写法是写成下面这样。
sizeof返回值
sizeof运算符的返回值,C 语言只规定是无符号整数,并没有规定具体的类型,而是留给系统自己去决定,sizeof到底返回什么类型。不同的系统中,返回值的类型有可能是unsigned int,也有可能是unsigned long,甚至是unsigned long long,对应的printf()占位符分别是%u、%lu和%llu。这样不利于程序的可移植性。
C 语言提供了一个解决方法,创造了一个类型别名size_t,用来统一表示sizeof的返回值类型。该别名定义在stddef.h头文件(引入stdio.h时会自动引入)里面,对应当前系统的sizeof的返回值类型,可能是unsigned int,也可能是unsigned long。
C 语言还提供了一个常量SIZE_MAX,表示size_t可以表示的最大整数。所以,size_t能够表示的整数范围为[0, SIZE_MAX]。
printf()有专门的占位符%zd或%zu,用来处理size_t类型的值。
如果当前系统不支持%zd或%zu,可使用%u(unsigned int)或%lu(unsigned long int)代替。
类型转换
- 赋值运算符的自动转换
字节宽度较小的整数类型,赋值给字节宽度较大的整数变量时,会发生类型提升,即窄类型自动转为宽类型。
字节宽度较大的类型,赋值给字节宽度较小的变量时,会发生类型降级,自动转为后者的类型。这时可能会发生截值(truncation),系统会自动截去多余的二进制位,导致难以预料的结果。
- 运算符的自动转换
不同的浮点数类型混合运算时,宽度较小的类型转为宽度较大的类型,比如float转为double,double转为long double。
不同的整数类型混合运算时,宽度较小的类型会提升为宽度较大的类型。比如short转为int,int转为long等,有时还会将带符号的类型signed转为无符号unsigned。避免无符号与有符号的混合运算,会出现意想不到的错误。
- 函数的参数和返回值,会自动转成函数定义里指定的类型。
可移植类型
整数类型的极限值,有时候需要查看,当前系统不同整数类型的最大值和最小值,C 语言的头文件limits.h提供了相应的常量,比如SCHAR_MIN代表 signed char 类型的最小值-128,SCHAR_MAX代表 signed char 类型的最大值127。
为了代码的可移植性,需要知道某种整数类型的极限值时,应该尽量使用这些常量。
SCHAR_MIN,SCHAR_MAX:signed char 的最小值和最大值。
SHRT_MIN,SHRT_MAX:short 的最小值和最大值。
INT_MIN,INT_MAX:int 的最小值和最大值。
LONG_MIN,LONG_MAX:long 的最小值和最大值。
LLONG_MIN,LLONG_MAX:long long 的最小值和最大值。
UCHAR_MAX:unsigned char 的最大值。
USHRT_MAX:unsigned short 的最大值。
UINT_MAX:unsigned int 的最大值。
ULONG_MAX:unsigned long 的最大值。
ULLONG_MAX:unsigned long long 的最大值。
程序员有时控制准确的字节宽度,这样的话,代码可以有更好的可移植性,头文件stdint.h创造了一些新的类型别名。
(1)精确宽度类型(exact-width integer type),保证某个整数类型的宽度是确定的。
int8_t:8位有符号整数。
int16_t:16位有符号整数。
int32_t:32位有符号整数。
int64_t:64位有符号整数。
uint8_t:8位无符号整数。
uint16_t:16位无符号整数。
uint32_t:32位无符号整数。
uint64_t:64位无符号整数。
程序员有时控制准确的字节宽度,这样的话,代码可以有更好的可移植性,头文件stdint.h创造了一些新的类型别名。
字符数组与字符串区别
数字 0(和字符‘\0’等价)结尾的 char 数组就是一个字符串,字符串是一种特殊的 char 的数组。
字符串多行
- 如果字符串过长,可以在需要折行的地方,使用反斜杠(\)结尾,将一行拆成多行。
"hello \
world"
- 只要这些字符串之间没有间隔,或者只有空格,C 语言会将它们自动合并。
char greeting[50] = "Hello, ""how are you ""today!";
// 等同于
char greeting[50] = "Hello, how are you today!";
字符指针和字符数组
- 指针指向的字符串,在 C 语言内部被当作常量,不能修改字符串本身。
为什么字符串声明为指针时不能修改,声明为数组时就可以修改?原因是系统会将字符串的字面量保存在内存的常量区,这个区是不允许用户修改的。声明为指针时,指针变量存储的只是一个指向常量区的内存地址,因此用户不能通过这个地址去修改常量区。但是,声明为数组时,编译器会给数组单独分配一段内存,字符串字面量会被编译器解释成字符数组,逐个字符写入这段新分配的内存之中,而这段新内存是允许修改的。
为了提醒用户,字符串声明为指针后不得修改,可以在声明时使用const说明符,保证该字符串是只读的。
const char* s = "Hello, world!";
- 指针变量可以指向其它字符串。
为什么数组变量不能赋值为另一个数组?原因是数组变量所在的地址无法改变,或者说,编译器一旦为数组变量分配地址后,这个地址就绑定这个数组变量了,这种绑定关系是不变的。C 语言也因此规定,数组变量是一个不可修改的左值,即不能用赋值运算符为它重新赋值。
gets(str)与 scanf(“%s”,str)的区别
- gets(str)允许输入的字符串含有空格
- scanf(“%s”,str)不允许含有空格
fgets与fputs
char *fgets(char *s, int size, FILE *stream);
int fputs(const char * str, FILE * stream);
fgets()在读取一个用户通过键盘输入的字符串的时候,同时把用户输入的回 车也做为字符串的一部分。通过 scanf 和 gets 输入一个字符串的时候,不包 含结尾的“\n”,但通过 fgets 结尾多了“\n”。fgets()函数是安全的,不存在缓冲区溢出的问题。
fputs()是 puts()的文件操作版本,但 fputs()不会自动输出一个’\n’。
数组
- 数组scores只有100个成员,因此scores[100]这个位置是不存在的。但是,引用这个位置并不会报错,会正常运行,使得紧跟在scores后面的那块内存区域被赋值,而那实际上是其他变量的区域,因此不知不觉就更改了其他变量的值。这很容易引发错误,而且难以发现。
- C 语言规定,数组变量一旦声明,就不得修改变量指向的地址,声明数组时,编译器自动为数组分配了内存地址,这个地址与数组名是绑定的,不可更改。
- 数组初始化时,可以指定为哪些位置的成员赋值。
int a[15] = {[2] = 29, [9] = 7, [14] = 48};
上面示例中,数组的2号、9号、14号位置被赋值,其他位置的值都自动设为0。
指定位置的赋值可以不按照顺序,下面的写法与上面的例子是等价的。
int a[15] = {[9] = 7, [14] = 48, [2] = 29};
指定位置的赋值与顺序赋值,可以结合使用。
int a[15] = {1, [5] = 10, 11, [10] = 20, 21}
- c99提供了变长数组,运行时才知道数组的具体长度。
- 数组作为函数的参数,必须要传入数组名和长度,不然默认大小为指针大小。
- 多维数组作为函数参数,除了第一维度,其他维度必须写入定义。
- 变长数组作为函数参数,数组a[n]是一个变长数组,它的长度取决于变量n的值,只有运行时才能知道。所以,变量n作为参数时,顺序一定要在变长数组前面,这样运行时才能确定数组a[n]的长度,否则就会报错。
- 因为函数原型可以省略参数名,所以变长数组的原型中,可以使用*代替变量名,也可以省略变量名。
int sum_array(int, int [*]);
int sum_array(int, int []);
- 数组拷贝一种是挨个元素复制,一种方法是使用memcpy()函数(定义在头文件string.h),直接把数组所在的那一段内存,再复制一份。
memcpy(a, b, sizeof(b));
- C 语言允许将数组字面量作为参数,传入函数。
// 数组变量作为参数
int a[] = {2, 3, 4, 5};
int sum = sum_array(a, 4);
// 数组字面量作为参数
int sum = sum_array((int []){2, 3, 4, 5}, 4);
上面示例中,两种写法是等价的。第二种写法省掉了数组变量的声明,直接将数组字面量传入函数。{2, 3, 4, 5}是数组值的字面量,(int [])类似于强制的类型转换,告诉编译器怎么理解这组值。
函数
- c语言没有默认参数
- 不返回值的函数,使用void关键字表示返回值的类型。没有参数的函数,声明时要用void关键字表示参数类型。
- 不要返回局部变量的地址
- 形参是实参的拷贝,值传递。
- 函数本身就是一段内存里面的代码,C 语言允许通过指针获取函数。
void print(int a) {
printf("%d\n", a);
}
void (*print_ptr)(int) = &print;
上面示例中,变量print_ptr是一个函数指针,它指向函数print()的地址。函数print()的地址可以用&print获得。注意,(print_ptr)一定要写在圆括号里面,否则函数参数(int)的优先级高于,整个式子就会变成void* print_ptr(int)。
如果一个函数的参数或返回值,也是一个函数,那么函数原型可以写成下面这样。
int compute(int (*myfunc)(int), int, int);
上面示例可以清晰地表明,函数compute()的第一个参数也是一个函数。
- 函数原型包括参数名也可以,虽然这样对于编译器是多余的,但是阅读代码的时候,可能有助于理解函数的意图。
int twice(int);
// 等同于
int twice(int num);
上面示例中,twice函数的参数名num,无论是否出现在原型里面,都是可以的。
- 在main()函数里面,exit()等价于使用return语句。其他函数使用exit(),就是终止整个程序的运行,没有其他作用。
C 语言还提供了一个atexit()函数,用来登记exit()执行时额外执行的函数,用来做一些退出程序时的收尾工作。该函数的原型也是定义在头文件stdlib.h。
- 函数原型默认就是extern
- static关键字表示该函数只能在当前文件里使用,如果没有这个关键字,其他文件也可以使用这个函数(通过声明函数原型)。
- 有些函数的参数数量是不确定的,声明函数的时候,可以使用省略号…表示可变数量的参数。
int printf(const char* format, …);
上面示例是printf()函数的原型,除了第一个参数,其他参数的数量是可变的,与格式字符串里面的占位符数量有关。这时,就可以用…表示可变数量的参数。
注意,…符号必须放在参数序列的结尾,否则会报错。
头文件stdarg.h定义了一些宏,可以操作可变参数。
(1)va_list:一个数据类型,用来定义一个可变参数对象。它必须在操作可变参数时,首先使用。
(2)va_start:一个函数,用来初始化可变参数对象。它接受两个参数,第一个参数是可变参数对象,第二个参数是原始函数里面,可变参数之前的那个参数,用来为可变参数定位。
(3)va_arg:一个函数,用来取出当前那个可变参数,每次调用后,内部指针就会指向下一个可变参数。它接受两个参数,第一个是可变参数对象,第二个是当前可变参数的类型。
(4)va_end:一个函数,用来清理可变参数对象。
下面是一个例子。
double average(int i, ...) {
double total = 0;
va_list ap;
va_start(ap, i);
for (int j = 1; j <= i; ++j) {
total += va_arg(ap, double);
}
va_end(ap);
return total / i;
}
上面示例中,va_list ap定义ap为可变参数对象,va_start(ap, i)将参数i后面的参数统一放入ap,va_arg(ap, double)用来从ap依次取出一个参数,并且指定该参数为 double 类型,va_end(ap)用来清理可变参数对象。
多文件编程
- 为了避免同一个文件被 include 多次,C/C++中有两种方式,一种是 #ifndef 方式,一种是 #pragma once 方式。
方法一:
#ifndef __SOMEFILE_H__
#define __SOMEFILE_H__
// 声明语句 #endif
方法二:
#pragma once
// 声明语句
指针
- 使用 sizeof()测量指针的大小,得到的总是:4 或 8
- 指针可以和整数加减,指针不能和指针相加,但是可以相减,指针之间可以去进行比较
- sizeof()测的是指针变量指向存储地址的大小
- 在 32 位平台,所有的指针(地址)都是 32 位(4 字节)
- 在 64 位平台,所有的指针(地址)都是 64 位(8 字节)
- 任意数值赋值给指针变量没有意义,因为这样的指针 就成了野指针,此指针指向的区域是未知(操作系统不允许操作此指针指向的 内存区域)。所以,野指针不会直接引发错误,操作野指针指向的内存区域才 会出问题。
- void *指针可以指向任意变量的内存空间:
void *p = NULL;
int a = 10;
p = (void *)&a; //指向变量时,最好转换为void *
//使用指针变量指向的内存时,转换为int *
*( (int *)p ) = 11;
printf("a = %d\n", a);
- 星号*可以放在变量名与类型关键字之间的任何地方
- 如果同一行声明两个指针变量,那么需要写成下面这样。
// 正确
int * foo, * bar;
// 错误
int* foo, bar;
- NULL在 C 语言中是一个常量,表示地址为0的内存空间,这个地址是无法使用的,读写该地址会报错。
结构体
- 声明自定义类型的变量时,类型名前面,不要忘记加上struct关键字。也就是说,必须使用struct fraction f1声明变量,不能写成fraction f1
struct car saturn = {“Saturn SL/2”, 16000.99, 175};
上面示例中,变量saturn是struct car类型,大括号里面同时对它的三个属性赋值。如果大括号里面的值的数量,少于属性的数量,那么缺失的属性自动初始化为0。
注意,大括号里面的值的顺序,必须与 struct 类型声明时属性的顺序一致。否则,必须为每个值指定属性名。
struct car saturn = {.speed=172, .name="Saturn SL/2"};
上面示例中,初始化的属性少于声明时的属性,这时剩下的那些属性都会初始化为0。
声明变量以后,可以修改某个属性的值。
struct car saturn = {.speed=172, .name="Saturn SL/2"};
saturn.speed = 168;
- struct 结构占用的存储空间,不是各个属性存储空间的总和,而是最大内存占用属性的存储空间的倍数,其他属性会添加空位与之对齐。这样可以提高读写效率。
struct foo {
int a;
char* b;
char c;
};
printf("%d\n", sizeof(struct foo)); // 24
上面示例中,struct foo有三个属性,在64位计算机上占用的存储空间分别是:int a占4个字节,指针char* b占8个字节,char c占1个字节。它们加起来,一共是13个字节(4 + 8 + 1)。但是实际上,struct foo会占用24个字节,原因是它最大的内存占用属性是char* b的8个字节,导致其他属性的存储空间也是8个字节,这样才可以对齐,导致整个struct foo就是24个字节(8 * 3)。
struct foo {
int a; // 4
char pad1[4]; // 填充4字节
char *b; // 8
char c; // 1
char pad2[7]; // 填充7字节
};
printf("%d\n", sizeof(struct foo)); // 24
为什么浪费这么多空间进行内存对齐呢?这是为了加快读写速度,把内存占用划分成等长的区块,就可以快速在 Struct 结构体中定位到每个属性的起始地址。
由于这个特性,在有必要的情况下,定义 Struct 结构体时,可以采用存储空间递减的顺序,定义每个属性,这样就能节省一些空间。
-
struct 变量可以使用赋值运算符(=),复制给另一个变量,这时会生成一个全新的副本。系统会分配一块新的内存空间,大小与原来的变量相同,把每个属性都复制过去,即原样生成了一份数据。这一点跟数组的复制不一样,务必小心。
-
通常情况下,开发者希望传入函数的是同一份数据,函数内部修改数据以后,会反映在函数外部。而且,传入的是同一份数据,也有利于提高程序性能。这时就需要将 struct 变量的指针传入函数,通过指针来修改 struct 属性,就可以影响到函数外部。
struct 指针传入函数的写法如下。
void happy(struct turtle* t) {
}
happy(&myTurtle);
上面代码中,t是 struct 结构的指针,调用函数时传入的是指针。struct 类型跟数组不一样,类型标识符本身并不是指针,所以传入时,指针必须写成&myTurtle
函数内部也必须使用(*t).age的写法,从指针拿到 struct 结构本身。
void happy(struct turtle* t) {
(*t).age = (*t).age + 1;
}
上面示例中,(t).age不能写成t.age,因为点运算符.的优先级高于*。*t.age这种写法会将t.age看成一个指针,然后取它对应的值,会出现无法预料的结果。
(*t).age这样的写法很麻烦。C 语言就引入了一个新的箭头运算符(->),可以从 struct 指针上直接获取属性,大大增强了代码的可读性。
void happy(struct turtle* t) {
t->age = t->age + 1;
}
- 赋值的时候有多种写法。
// 写法一
struct fish shark = {"shark", 9, {"Selachimorpha", 500}};
// 写法二
struct species myBreed = {"Selachimorpha", 500};
struct fish shark = {"shark", 9, myBreed};
// 写法三
struct fish shark = {
.name="shark",
.age=9,
.breed={"Selachimorpha", 500}
};
// 写法四
struct fish shark = {
.name="shark",
.age=9,
.breed.name="Selachimorpha",
.breed.kinds=500
};
- struct 还可以用来定义二进制位组成的数据结构,称为“位字段”(bit field),这对于操作底层的二进制数据非常有用。
struct {
unsigned int ab:1;
unsigned int cd:1;
unsigned int ef:1;
unsigned int gh:1;
} synth;
synth.ab = 0;
synth.cd = 1;
上面示例中,每个属性后面的:1,表示指定这些属性只占用一个二进制位,所以这个数据结构一共是4个二进制位。
注意,定义二进制位时,结构内部的各个属性只能是整数类型。
实际存储的时候,C 语言会按照int类型占用的字节数,存储一个位字段结构。如果有剩余的二进制位,可以使用未命名属性,填满那些位。也可以使用宽度为0的属性,表示占满当前字节剩余的二进制位,迫使下一个属性存储在下一个字节。
struct {
unsigned int field1 : 1;
unsigned int : 2;
unsigned int field2 : 1;
unsigned int : 0;
unsigned int field3 : 1;
} stuff;
上面示例中,stuff.field1与stuff.field2之间,有一个宽度为两个二进制位的未命名属性。stuff.field3将存储在下一个字节
- 很多时候,不能事先确定数组到底有多少个成员。如果声明数组的时候,事先给出一个很大的成员数,就会很浪费空间。C 语言提供了一个解决方法,叫做弹性数组成员(flexible array member)。
如果不能事先确定数组成员的数量时,可以定义一个 struct 结构。
struct vstring {
int len;
char chars[];
};
上面示例中,struct vstring结构有两个属性。len属性用来记录数组chars的长度,chars属性是一个数组,但是没有给出成员数量。
chars数组到底有多少个成员,可以在为vstring分配内存时确定。
struct vstring* str = malloc(sizeof(struct vstring) + n * sizeof(char));
str->len = n;
上面示例中,假定chars数组的成员数量是n,只有在运行时才能知道n到底是多少。然后,就为struct vstring分配它需要的内存:它本身占用的内存长度,再加上n个数组成员占用的内存长度。最后,len属性记录一下n是多少。
这样就可以让数组chars有n个成员,不用事先确定,可以跟运行时的需要保持一致。
弹性数组成员有一些专门的规则。首先,弹性成员的数组,必须是 struct 结构的最后一个属性。另外,除了弹性数组成员,struct 结构必须至少还有一个其他属性。