Ranking Loss函数:度量学习
Ranking Loss 函数:度量学习
背景
- 由于Ranking Loss应用在许多领域,任务以及神经网络中(比如Siamese Nets or Triplet Nets),所以它们又有了一些别的诸如Contrastive Loss, Margin Loss, Hinge Loss or Triplet Loss的名字。
含义
交叉熵和MSE的目标是去预测一个label,或者一个值,又或者或一个集合,不同于它们,Ranking Loss的目标是去预测输入之间的相对距离,这个任务也被通常称为度量学习(Metric Learning)(例如在图像相似性预测,graph相似性预测,或者其他含有相似性的任务中)。
Ranking Loss函数通常都非常会随着训练数据的变化而变化,我们只是需要得到一个数据之间度量相似度的分数。这个分数可以是binary的(相似或不相思)。举个例子 ,想象一下我们现在有一个面孔鉴别数据库,我们已知图片和其相对应的人,也就是说,我们知道了哪些图片是相似的,哪些图片是不相似的。现在我们用Ranking Loss 函数去训练一个CNN来推断两个图片是不是属于同一个人。
- 也就是说,如果想要得到一个二元相似性,那就是输出:
- 0:不相似;1:相似
- 如果想得到相似性程度
- 输出的是就是[0,1]之间的一个实数,越接近于1,代表越相似。
在使用Ranking Loss 之前,我们先提取两个(或三个)数据的特征(feature)得到相对应的几个embedded representation。然后我们定义一个度量函数去测量这些representation之间的相似性(比如欧氏距离)。最后我们训练一个特征提取器(比如CNN)按照相似性,去为这几个数据生成representation。也就是说,如果这些图片相似,那么它们的representation就相似,如果不相似,它们的representation就差的比较远。
这里注意,我们不关注representation的实际值,只关注它们之间的相对距离。虽然如此,我们这种训练方法产生的representation对其他任务非常有帮助。
- 提取两个或这三个特征的意思是,选择两个相似的样本或者两个不想的样本作为一个样本对,输入网络模型,如果是siamese网络,就是两个样本组成的样本对,如果是()网络,就是三个样本组成的样本对。输入网络中,根据损失函数学习样本的representation.
- 这里的损失函数有很多,简单的就是欧氏距离
Ranking Loss 公式
虽然Ranking Loss有很多不同的名字,但是他们的公式基本都差不多。我们把Ranking Loss 分成两种情况:
- 我们用一组两个的训练数据(pairwise ranking loss)
- 我们用一组三个的训练数据(triplet ranking loss)
这两种情况都是为了去比较representation之间的相对距离。
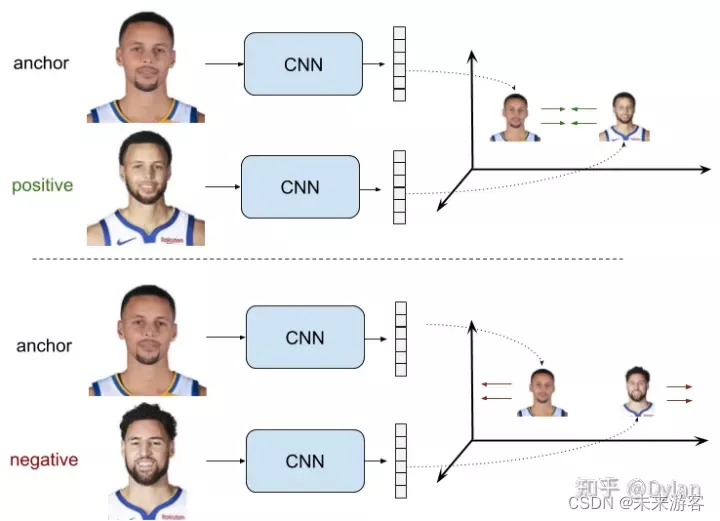 例:用pairwise ranking loss去训练一个面部鉴别网络。在这个例子中,CNN的weight共享。我们称之为siamese nets。但pairwise ranking loss也可以用在其他情况.
例:用pairwise ranking loss去训练一个面部鉴别网络。在这个例子中,CNN的weight共享。我们称之为siamese nets。但pairwise ranking loss也可以用在其他情况.
在pairwise ranking loss中,训练数据中的postive pair和negative pair都会被用到。所谓positive pair就是两张图片是同一个标签,图片相似,其中有一个anchor 图片 x a x_a xa 和一个positive图片 x p x_p xp 。Negative pair就是指两张图片不是一个标签,图片不相似,其中一个是anchor图片 x a x_a xa 和一个negative图片 x p x_p xp。
我们的目标就是为postive pair生成相对距离 d d d近的representation,为negative pair生成相对距离 d d d远的representation,其中对于negative pair的距离,我们限制它大于一个特定边界值 m m m。Pairwise Ranking Loss迫使positive pair距离趋向于0,让negative pair距离大于边界值 m m m。我们用如下的公式来表示,其中 r a r_a ra, r p r_p rp, r n r_n rn来表示 x a x_a xa, x p x_p xp, x n x_n xn的representation,用 d d d来表示距离函数:
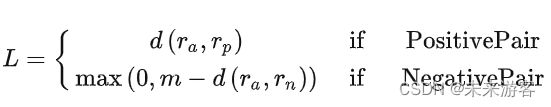
对于positive pairs,如果网络输出给这两个图片的representations之间的距离为0,那么loss也为0,loss会随着距离的增加而增加。
- 换句话说,loss就是两个嵌入之间的相对度量函数。
对于negative pairs,当两个representation之间的距离大于边界值 m m m ,loss就为0。但当这个距离不大于m时,loss就会变成正数,网络参数也会相应更新来使得这两个representation距离变远。当中 r a r_a ra和 r n r_n rn的距离为0时,loss最大,为m。这个边界值本质上的意义是,当negative pairs的representation距离足够远时,不需要在浪费资源去增大negative pairs之间的距离。
如果 r 0 r_0 r0和 r 1 r_1 r1是一对数据的representation, y y y是一个二值标示(0表示negative pair,1表示positive pair),距离 d d d是欧式距离,那么我们可以把公式写为: L ( r 0 , r 1 , y ) = y ∣ ∣ r 0 − r 1 ∣ ∣ + ( 1 − y ) m a x ( 0 , m − ∣ ∣ r 0 − r 1 ∣ ∣ ) L(r_0,r_1,y)=y||r_0-r_1||+(1-y)max(0,m-||r_0-r_1||) L(r0,r1,y)=y∣∣r0−r1∣∣+(1−y)max(0,m−∣∣r0−r1∣∣)
Negatives Selection
在训练Triplet Ranking Loss时,一个很重要的技巧叫做Negatives Selection或者叫做triplet mining。不同选择下的方案对训练效率的影响非常大。一个很明显可以得出的结论就是,我们要避免在Easy Triplets情况下去更新网络,因为这个时候loss为0。
首先第一个选择的方案使用的是offline triplet mining,也就是指triplet是在每个epoch训练开始时定义的。另一个方案是online triplet mining,这是指triplet是在训练每个batch时定义的,这种方案也会带来更高训练效率和性能。
Ranking Losses的其他名字
Ranking Losses的本质就是我上文所说的,但在其他任务中,他还有很多不同的名字和细微的变形。就是这些名字让人看糊涂了,所以我来解释一下为什么会用这些名字。
- Ranking loss: 这个名字是源自于information retrieval领域,在这个领域中,我们希望模型能把数据按照特定的顺序排列。
- Margin Loss: 这个名字是源自这个loss当中使用了边界值去比较数据间的距离。Contrastive Loss: Contrastive指的是两个或者多个数据表示间的对比。这个名字通常被用在Pairwise Ranking Loss,但很少用在triplets。
- Triplet Loss: 通常被用在使用triplets训练数据。
- Hinge loss: 也被称为 max-margin objective. 它通常被用在训练 SVMs 分类任务,现在也被常用GAN的训练中。Siamese and triplet nets
参考:https://zhuanlan.zhihu.com/p/395177149