#Reading Paper# Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction
#论文题目:Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction(基于图神经网络和元学习的冷启动推荐算法)
#论文地址:https://arxiv.org/abs/2105.08909
#论文发表网站:https://dl.acm.org/doi/10.1145/3404835.3462879
#论文源码开源地址:https://github.com/oywtece/gme
#论文所属会议:SIGIR 2021(CCF A类会议)
#论文所属单位:Alibaba
一、摘要
点击率(CTR)预测在线上广告系统中是最重要的任务指标。虽然现在基于深度学习模型的特征向量表示学习在CTR预测中取得了显著的效果,但是对于训练好的推荐模型,当遇到冷启动的商品时,由于缺乏充分的数据,无法学习到好的embedding,从而会导致性能下降。本文提出Graph Meta Embedding (GME) 方法,利用图神经网络和元学习快速学习生成冷启动商品的初始id embedding。GME一方面考虑商品自身的属性信息,另一方面考虑旧商品和冷启动商品之间的关系。
GME方法主要包含两个部分:EG(embedding generator)和GAT。EG用于生成id embedding,GAT用于汇总提取信息。文章从不同的角度分别提出了GME-P,GME-G,GME-A三种方法,其中作者指出GME-A效果最好。
二、文章的主要创新点
- 给定一个新ad,通过此ad本身所带的标签(如商标、标题等)和与其关联的老ad的embeddings,最终得到新ad的embeddings。
- 提出了三种方法:
· GME-P:使用预先训练好的邻居ID的embeddings
· GME-G:使用二次生成的邻居ID的embeddings
· GME-A:使用邻居的属性特征 - 实验证明GME方法在实际应用中效果显著
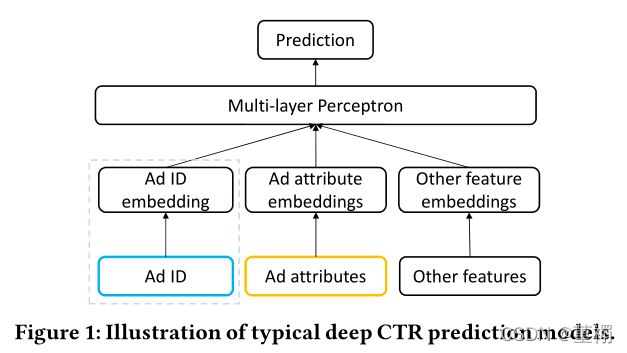
三、文章总览
(一)符号表示
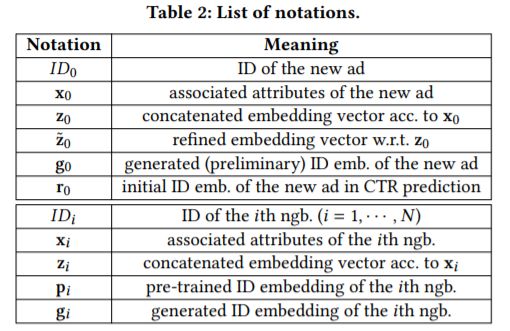
(二)文章总体架构
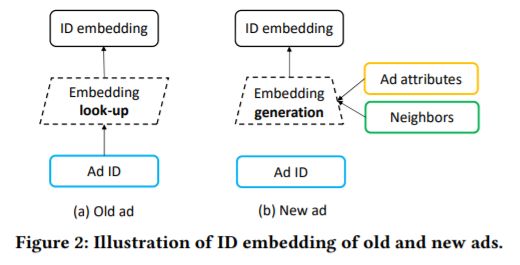
当一个新的id出现的时候,首先在已经训练好的向量矩阵上查找,若能找到则使用查找到的老ad的向量作为新ad的向量表示[Figure2-(a)],否则,根据其属性和邻居通过训练得到id的向量表示。
(三)建图
GME需要构建新商品和旧商品之间的关系,因此需要先对其进行建图。由于需要构建新商品和旧商品之间的关系,因此无法使用点击关系进行构建,本文作者采用商品的属性特征来构建商品之间的关系,如下图所示。(一个新ad可以有多个老ad的邻居)
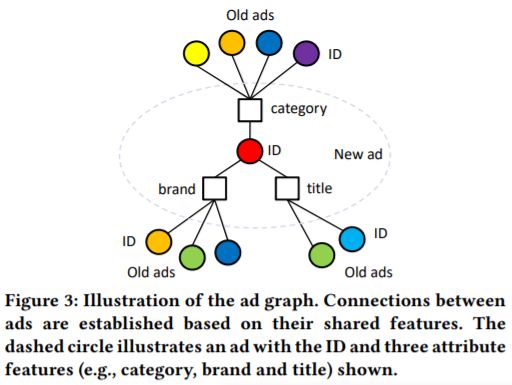
那么如何找到新ad对应的邻居呢?根据新ad的属性,在倒排拉链中找neighbor。如下图所示:ID:5的邻居是ID:1、ID:2、ID:3。

四、论文三种方法

· GME-P:使用预训练的邻居ID嵌入
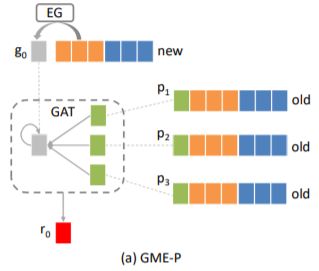
总体思路:利用了新ad的属性和预先训练的邻近旧ad的ID嵌入。当一个新ad要得到最终的ID embedding,先根据其属性信息找到网络中邻居们的ID embeddings记为 {pi } ,其次,根据属性信息设置初始ID embedding为g0。此时, {pi } 和g0都是ID embedding,我们需要提取 {pi } 中有用的信息去调教g0去获得最终细化后的ID embedding r0。具体分为两个步骤:
1. ID Embedding Generation(EG)
这部分利用新ad相关的属性特征(包括类别,品牌等)生成基础的id embedding。将ad实例表示为[ID0, x0, o0],ID表示新ad的id,x表示和ad相关的特征,o表示和ad不相关的特征(如用户特征,上下文特征等)。将ad相关的特征的embedding拼接后得到z0,然后通过下式得到g0。其中w为可学习参数,γ为缩放超参数。
![]()
2. ID Embedding Refinement
一个最简单的方法得到新ad的ID embedding方法是average(g0, p1, p2 …, pN)。但是由于有一些老ad可能不是那么有效果,所以并不是一个明智的选择。文章利用GAT相关思想通过注意机制将不同的重要性分配给邻域内的不同图节点。
首先计算g0和pi的注意力系数c0i:
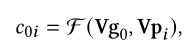
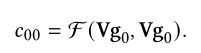
计算注意力机制系数公式如下,leakyrelu的系数为0.2。这里的注意力系数不仅计算了新商品和邻居之间的系数,也计算新商品与自己的自注意力系数。
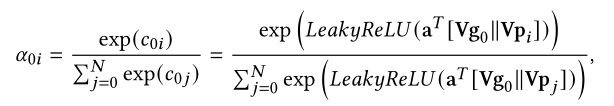
然后对所有embedding(包括自己和邻居)加权求和,公式如下:
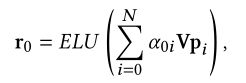
3. 分析
该方法用到的周围邻居的embedding是原始推荐系统模型中得到的,没有在属性和id embedding之间加任何约束,并且所有embedding都是随机初始化的。可能遇到具有相同属性的两个商品之间的embedding差别很大,导致计算得到的注意力系数没有意义。
· GME-G: 使用生成的邻居ID嵌入
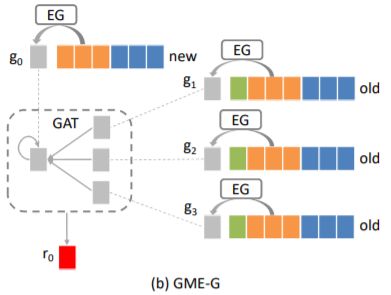
如图所示为GME-G的示意图。为了解决GME-P的缺陷,GME-G将新ad和邻居旧ad都通过EG结合对应的属性来得到他们的embedding。
1. ID Embedding Generation(EG)
这里生成方式和GME-P一样,公式如下,其中g0表示新ad,gi表示邻居ad。
![]()
2. ID Embedding Refinement
这里细化的方式和GME-P一样,只是把GME-P中直接由预训练好的推荐模型得到embedding的方式改成了同样适用EG来生成embedding,公式也是类似的:
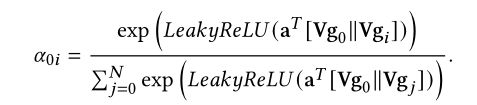

3. 分析
GME-G虽然解决了GME-P的缺陷,但是需要重复生成旧商品的embedding。生成的embedding可能存在噪声,而重复生成可能将噪声放大。
· GME-A: 使用邻居的属性
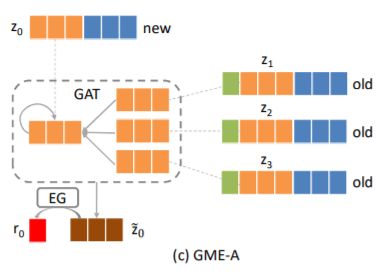
为解决GME-G的问题,本节提出GME-A方法。如上图所示为GME-A的示意图,该方法将“生成(ER)”和“细化(EP)”两个步骤颠倒,并且在细化阶段细化的不再是id embedding而是属性的embedding。
** 1. Attribute Embedding Refinement**
这部分通过上面建的商品属性关系图,利用邻居旧商品的属性和新商品的属性进行细化,公式如下,这里也是包含新商品自身和周围邻居一起计算的。
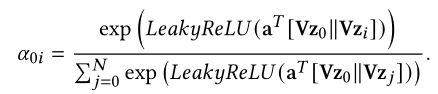

** 2. ID Embedding Generation**
这部分就是直接采用细化后的属性embedding得到对应的id embedding。 计算方式和前面类似。

3. 分析
GME-A只是比较了新ad和其邻居老的ad之间的属性,因此避免了生成的ID embedding和预先训练的ID embedding之间根本不能比较的问题,此外,GME-A只是使用了EG一次,避免了GME-G的重复问题。
五、模型学习
首选训练好一个常用的推荐模型(如DNN),然后固定其参数不变,训练GME的参数。损失函数考虑两个方面:1)新商品的CTR预测误差应该要小,2)在少量标记实例收集后,应该要能根据少量梯度更新来快速学习。分别表示为以下两个损失函数la,lb。
对于给定的训练数据,随机从中选出两个不相交的minibatch Da,Db,分别包含M个样本。首先通过GME得到 Da中的embedding r0,然后得到预测概率y–aj,表示第j个样本的预测概率。交叉熵损失函数la为下式:

然后计算la关于初始embedding的梯度r0,并经过一步梯度下降,可以得到新的自适应embedding,公式如下:
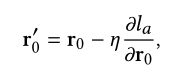
然后在Db上测试新的r0’,他的损失函数lb为:
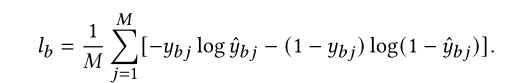
总的损失函数为:
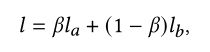
六、模型结果
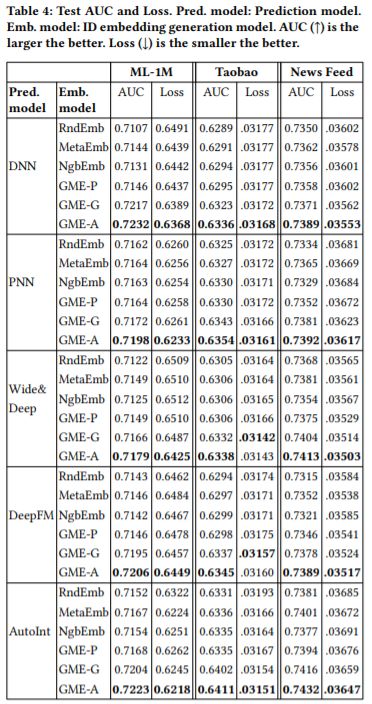
七、数据集

数据集链接:
ML-1M:http://www.grouplens.org/datasets/movielens/
Taobao:https://tianchi.aliyun.com/dataset/dataDetail?dataId=408
八、总结
-
本文作者主要从新商品的属性以及新商品和旧商品之间在属性上的关系来生成更好的embedding,通过GAT融合邻居节点的信息得到更好的属性embedding,再用属性embedding得到冷启动商品的id embedding,即最终点击率。
-
但是本算法需要预先训练推荐模型,根据训练好的推荐模型得到的结果进行二次开发,所以初始的推荐模型的准确性至关重要
-
根据网上查阅相关资料显示,此模型尚未实际应用在阿里的业务中。