PyTorch笔记 - R-Drop、Conv2d、3x3+1x1+identity算子融合
torch.nn模块:https://pytorch.org/docs/stable/nn.html
R-Drop - Regularized Dropout for Neural Networks
Dropout Layers:dropout比例、np.random.binomial二项相乘
2021.10.29 论文,微软:R-Drop - Regularized Dropout for Neural Networks,神经网络的正则化Dropout
Dropout在训练和推理时,存在不一致的问题,Dropout本质是集成学习(Ensemble Learning),推理使用与训练近似的方式,只保证期望相同
R-Dropout将每个子模型的KL散度最小,普遍有效,微调任务改进,每个训练样本输入2次,最小化双向KL散度。

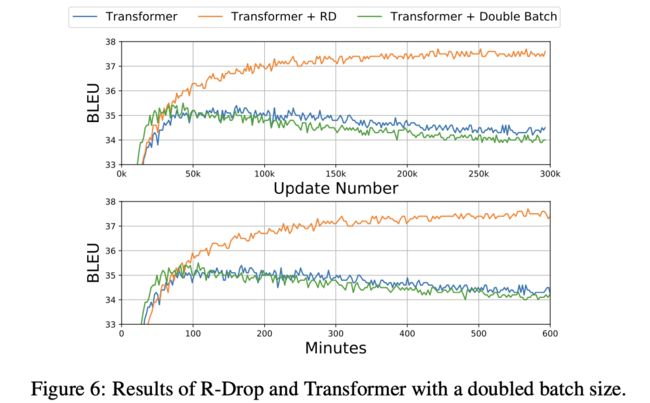
R-Drop减少训练和推理的不一致性,R-Dropout在18个数据集中实验,效果更好。
同一个样本,输入两个不同的dropout网络,最小化两个KL散度,保持一致。
Loss,L = NLL + KL:
- NLL:Negative Log-Likelihood Loss,负的对数释然损失
- KL:KL-divergence Loss,KL散度损失

提升BatchSize,再切分成2份,可以降低训练成本,测试成本没有差异。

KL 散度约束,比直接提升batchsize到2倍效果提升较多。
Conv2D
面试题:
卷积层:torch.nn.Conv2d(in_channels=2, out_channels=4, kernel_size=3, padding="same")
问:参数weight的参数量、偏移bias的参数量
答:torch.Size([4, 2, 3, 3])、torch.Size([4])
Depth-wise Convolution的原理是什么?降低计算量,没有混合channel
卷积层:torch.nn.Conv2d(in_channels=2, out_channels=4, kernel_size=3, padding="same", groups=2)
问:参数weight的参数量、偏移bias的参数量
答:torch.Size([4, 1, 3, 3])、torch.Size([4])
Depthwise Separable Convolution:Point-wise Convolution + Depth-wise Convolution,降低计算量
torch.nn.Conv2d:https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
- in_channels,输入channel
- out_channels,输出channel
- kernel_size,卷积核尺寸
- stride,步长
- padding,填充,valid和same
- dilation,空洞(扩张)
- groups,深度可分离卷积,Depthwise Separable Convolution,计算量下降
- bias,偏移
源码测试:
import torch
onv_layer = torch.nn.Conv2d(in_channels=2, out_channels=4, kernel_size=3, padding="same", groups=2)
for i in conv_layer.named_parameters():
print(i)
conv_layer.weight.size()
conv_layer.bias.size()
dilation:空洞卷积
Conv2d继承于_ConvNd,forward -> _conv_forward -> F.conv2d
bias的size与输出通道相关
Point-wise Convolution:1x1卷积,不考虑周围点,只考虑点自身,channel mix,通道加权组合,类似MLP,不考虑局部关联性、平移不变形
Depth-wise Convolution:groups设置为大于1的数,
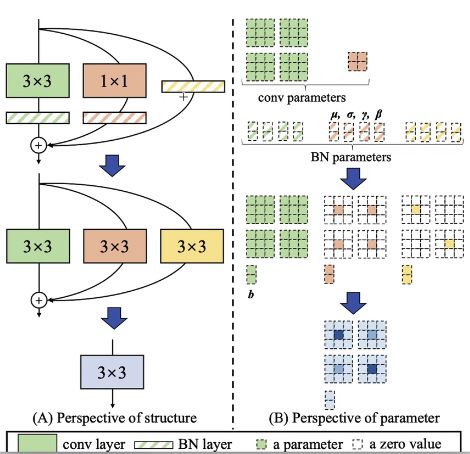
融合3x3 + 1x1 + x相加,conv_residual_block_fusion.py,对于原生卷积加速:
import torch
import torch.nn.functional as F
import torch.nn as nn
in_channels = 2
out_channels = 2
kernel_size = 3
w = 4
h = 4
x = torch.ones(1, in_channels, w, h)
print(f'x: {x.size()}')
# -----------
# 原生写法:res_block = 3x3 + 1x1 + input
conv_2d = nn.Conv2d(in_channels, out_channels, kernel_size, padding="same")
conv_2d_pointwise = nn.Conv2d(in_channels, out_channels, 1)
result1 = conv_2d(x) + conv_2d_pointwise(x) + x
print(f'result1: {result1}')
# -----------
# -----------
# 算子融合, 把point-wise卷积和x本身都写成3x3的卷积,最终把3个卷积融合成1个卷积
# 1x1 -> 3x3 卷积
print(f'conv_2d_pointwise.weight: {conv_2d_pointwise.weight.size()}, {conv_2d_pointwise.weight}')
# pointwise_to_conv_weight = F.pad(conv_2d_pointwise.weight, [1,1,1,1,0,0,0,0])
pointwise_to_conv_weight = F.pad(conv_2d_pointwise.weight, [1,1,1,1], "constant", 0)
print(f'conv_2d_pointwise.weight: {pointwise_to_conv_weight.size()}, {pointwise_to_conv_weight}')
conv_2d_for_pointwise = nn.Conv2d(in_channels, out_channels, kernel_size, padding="same")
conv_2d_for_pointwise.weight = nn.Parameter(pointwise_to_conv_weight)
conv_2d_for_pointwise.bias = nn.Parameter(conv_2d_pointwise.bias)
# x -> 3x3 卷积
zeros = torch.unsqueeze(torch.zeros(kernel_size, kernel_size), 0)
print(f'[Info] zeros: {zeros.size()}')
stars = torch.unsqueeze(F.pad(torch.ones(1,1) , [1,1,1,1], "constant", 0), 0)
print(f'[Info] stars: {stars.size()}')
stars_zeros = torch.unsqueeze(torch.cat([stars, zeros], 0), 0)
print(f'[Info] stars_zeros: {stars_zeros.size()}')
zeros_stars = torch.unsqueeze(torch.cat([zeros, stars], 0), 0)
print(f'[Info] zeros_stars: {zeros_stars.size()}')
identity_to_conv_weight = torch.cat([stars_zeros, zeros_stars], 0)
print(f'[Info] identity_to_conv_weight: {identity_to_conv_weight.size()}')
identity_to_conv_bias = torch.zeros([out_channels])
print(f'[Info] identity_to_conv_bias: {identity_to_conv_bias.size()}')
conv_2d_for_identity = nn.Conv2d(in_channels, out_channels, kernel_size, padding="same")
conv_2d_for_identity.weight = nn.Parameter(identity_to_conv_weight)
conv_2d_for_identity.bias = nn.Parameter(identity_to_conv_bias)
result2 = conv_2d(x) + conv_2d_for_pointwise(x) + conv_2d_for_identity(x)
print(f'result2: {result2}')
print(f'result1 and result2: {torch.all(torch.isclose(result1, result2))}')
# -----------
# -----------
# 3x3卷积融合到一起
conv_2d_for_fusion = nn.Conv2d(in_channels, out_channels, kernel_size, padding="same")
conv_2d_for_fusion.weight = nn.Parameter(conv_2d.weight + conv_2d_for_pointwise.weight + conv_2d_for_identity.weight)
conv_2d_for_fusion.bias = nn.Parameter(conv_2d.bias + conv_2d_for_pointwise.bias + conv_2d_for_identity.bias)
result3 = conv_2d_for_fusion(x)
print(f'result3: {result3}')
print(f'result2 and result3: {torch.all(torch.isclose(result2, result3))}')
# -----------