人工智能安全(二)—攻击
1《Deep Leakage from Gradients》
代码地址:https://gitee.com/dugu1076/ai-dlg.git
(这份代码是我自己全部加上注解后的,删除了所有多余代码,可直接运行,image下的desk.png是我成功攻击过的图片)
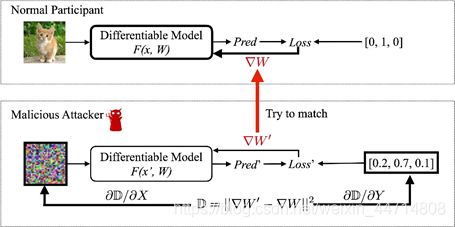
论文主要成果:提出一种优化算法DLG算法,可以在几个迭代中获取训练输入和标签。算法的主要思路是:假设虚拟输入和标签,计算虚拟梯度,优化虚拟梯度与真实梯度之间的距离,通过匹配梯度使得虚拟数据靠近原始数据。
算法具体步骤:
- 首先选取一张Normal Pic(以下简称NP) 和 用随机噪声生成的Malicious Pic(以下简称MP) 以及热编码的Malicious res(MR)
- 用NP在模型上进行正向传播,并且根据result与热编码进行计算loss值,获得梯度w
- 用MP在模型上进行正向传播,并且根据result与热编码进行计算loss值,获得梯度w2
- 利用w2与w计算误差值D=(w2-w)的平方,来分别更新生成的MP和MR
- 多次重复3步骤,4,当D较小时,MP就会与原图相似
实验结果:
Normal Pic :![]()
Malicious Pic:

实验结论:
- 从实验结果来看,有些噪音是无法完全清除的,但是能基本看出来是个啥东西
- 有部分图片并无法根据梯度进行恢复,loss值会直接卡死在一个值,然后图片出来全是马赛克,可以换一张图片试试。文章也说了(Our algorithm fully recovers the four images while previous work only succeeds on simple images with clean backgrounds)只能在干净的图片上成功,所有MNIST数据集应该是成功率最大的(狗头保命)
- 当batchsize过大的时候,无法进行攻击,我们现在进行的测试都是一次一张图片进行攻击的。论文解释为当这个batchsize(N)大于1时,收敛时就需要考虑收敛的方向,则就需要很多次迭代去完成这个收敛。
- 当输入图像过大的时候,无法进行攻击(未测试)
- 当网络越深的时候,无法进行攻击(未测试)(个人猜想:梯度消失?)
- 文章还有对原网络的修改。1.使用Sigmoid函数,由于需要二次可微( replacing activation ReLU to Sigmoid and removing strides, as our algorithm requires the model to be twice-differentiable) 2.随机初始化一个形状为 N × C 的向量,其中 N 是批量大小,C 是类的数量,然后将其 softmax 输出作为 one-hot 标签进行优化。
另外本文提出几种防御措施:
- 梯度扰动:噪声在10的-4次方时,不能防御梯度泄露;噪声在10的-3次方时,虽然有一定人工干扰,但是还是会泄露;噪声在10的-2次方时,会影响模型精度。
- 梯度压缩:对于梯度剪枝率大于20%,可以起到保护隐私的作用
- 大批量、高分辨率和密码学:正如我们测试的一样,当这个batchsize(N)的量十分大时,或者是图片尺寸比较大时,就很难恢复了。或者使用密码学中的方法对图片进行一些加密等操作。
到此,论文就结束了。个人认为,DLG 虽然不依赖于任何生成模型或额外的数据,但是DLG需要获得最最重要的梯度,在实际应用中,这个获得梯度的难道还是比较大的。(如果有梯度数据了,这个模型的大致样子是不是可以直接盲猜出来了)
2.后门学习大类(update at 8.26)
2.1《BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain》
综述:这篇文章说的是深度学习模型中植入后门(backdoor)的一种方法。训练时对训练数据做手脚,训练数据不仅包括正常数据还包括恶意数据(插入了后门),使得当模型进行训练时,当在正常数据情况下,模型预测正常,但当遇到恶意数据时,则预测出现了巨大的错误。
文中主要是用某个像素点(或是多个)来进行埋下后门的,以Mnist数据集为例(路标的那个机器跑不动了,cpu 8内存顶不住了),下图为使某个像素点变白(原来应该是全黑的)

在训练模型时,我们将一共60000张的训练数据 滞留6000张插入后门,54000张保持原来像素。在测试模型中,我们分为两组,一组全是干净的图片,一组为全部插入后门的图片。根据下图的结果可以看到,用带有插入后门训练过后的图片训练的模型,在正常的数据进行测试时,正确率其实挺高的(由于迭代次数较小,因此准确率没有到达很极限的地步),但是当在全部插入后门的数据中,正确率却低的很离谱,说明了插入像素点的攻击在后门攻击中是十分有效的。
![]()
一个奇怪的现象:当我在跑代码时,有时候会出现用带有后门的数据的数据训练模型时,无论是在带有后门的数据或者是正常的数据中测试时,正确率都很高的情况,这种现象并没有说在跑多少次循环后悔出现,说明像素点攻击并不是100%有效的,当迭代次数多的时候,可能会把像素点这一个特征都忽略掉,这个答案是我从下一篇有关后门攻击中的论文《Trojaning Attack on Neural Networks》想出来的,不知道对不对。
2.2《Trojaning Attack on Neural Networks》
本文提出了一种针对神经元网络的木马攻击。首先对神经元网络进行反向处理,生成一个通用的木马触发器,然后利用外部数据集对模型进行再训练,将恶意行为注入到模型中。恶意行为只会被带有木马触发器的输入激活。整个训练过程主要分成三个大步骤:1.木马触发生成 2.训练数据生成 3.模型再训练
木马触发生成
我们选择使用Apple logo作为人脸识别NN的trigger mask。所有的像素都落在由图标定义的形状中,用于插入触发器。然后,扫描目标神经网络,选择一个或几个神经元内层。它们的值可以通过改变触发器掩模中的输入变量轻松地操纵,(怎么选择呢?通过修改trigger maks中的输入变量,神经元的值可以被轻易修改)通过对Apple logo中的像素进行调整,最终生成一个苹果形状的彩色logo,使被我们选中的神经元的值可以由0.1到10。其实质是要在触发器和所选对象之间建立起牢固的联系。
总结下,生成一个触发器,该触发器对于模型的分类应该是很敏感的,该触发器对于神经网络中的某几个神经元应该具备比较敏感的情况。
训练数据生成
具体地说,我们从一个图像开始,这个图像是由一个不相关的公共数据集的所有事实图像平均生成的,模型从中生成一个目标输出分类置信度非常低(即, 0.1)的图像。输入逆向工程算法对图像的像素值进行调优,直到对于目标输出节点得到一个较大的置信值(即, 1.0),可以诱导出比其他输出节点大的输出节点。
直观地说,调优后的图像可以看作是原始训练集中的人的图像的替换,该训练集中的人的图像由目标输出节点表示。我们对每个输出节点重复这个过程,以获得一个完整的训练集。请注意,逆向工程图像在大多数情况下根本不像目标人物,但它与使用目标人物的真实图像训练NN具有相同的目的。换句话说,如果我们使用原始训练集和逆向工程输入集进行训练,得到的神经网络具有相当的准确性。
运用逆向工程生成一批可替代训练数据的数据,虽然数据可能并没有训练数据的样子,但却拥有训练数据的各种特征(个人感觉其实有点类似于遗传算法)
模型再训练
使用触发器和逆向生成的图像对模型的一部分进行再训练,即在所选神经元的驻留层和输出层之间的层。对于深度NNs来说,对整个模型进行再培训是非常昂贵的,也是不必要的。
对于每个人B的逆向工程输入图像l,生成一对训练数据。
一个是图像I,目标是人B的预定分类结果;
另一个是图像(I +木马触发器),目标是A的预定分类,目标是欺骗性质的。
用这些训练数据对神经网络进行再训练,以原始模型为起点。再训练后,调整原神经网络的权值,使新模型在不存在触发器的情况下仍能正常工作,并预测伪装目标。
思考的问题:为什么一开始就直接拿(木马触发器+图像,错误分类)+(图像+分类)的方式去训练。
一个是论文假设情况是训练数据是在未知的情况下的,二是我们如果直接拿一个木马触发器并不一定会产生很好的效果,在《BadNet》这篇论文中,拿了一个白点当做后门木马触发器时,实验中Mnist数据集本来就是黑白的,对白点较为敏感,且放在右下角,就更加突出了,同理汽车路标的话效果应该会差一点,而本文的第一步 木马触发生成 可以保证这个木马肯定有用 。
论文中也做出了一定的解释:
有两个重要的设计选择。第一个方法是从模型生成一个触发器,而不是使用任意的logo作为一个触发器。请注意,可以使用任意选择的logo对逆向工程的完整图像进行标记,然后对模型进行重新训练,使其预测标记的图像是伪装人。然而,我们的经验表明,这很难工作,因为一个任意的标志往往对大多数神经元有一致的小影响。因此,在不改变模型的正常行为的情况下,很难对模型进行再训练来激活伪装输出节点。从直观上看,为了放大任意logo所引起的微小冲击,为了刺激伪装输出节点,许多神经元的权值都需要大幅度的增大,但是由于难以补偿这些权值的变化,使得正常行为不可避免的发生了偏斜。
第二种是选择内部神经元进行触发产生。另一种方法是直接使用masquerade输出节点,换句话说,可以对触发器掩码中的输入进行调优,从而直接激活masquerade输出节点(或目标节点)。经验表明,它的效果不好(第6节)。
原因:(1)现有的模型中的因果关系在触发器输入和目标节点之间较弱,可能没有为这些可以激发目标节点的变量赋值;(2)失去再训练模型的优势,因为所选层是输出层和没有其他层不改变模型(通过再训练),对木马的输入和原始输入,疑难达到很好的精度。
攻击设计:
是触发器生成算法。使用梯度下降来找到一个局部的最小损失函数,这是当前值和所选神经元的预期值之间的差异。给定一个初始赋值,该过程沿着损失函数的负梯度迭代细化输入,使所选神经元的最终值尽可能接近预期值。
防御的方式:
对这类攻击的一种可能的防御方法是检查错误预测结果的分布。对于受trojaned模型,其中一个输出将占大多数。
3.《How To Backdoor Federated Learning》
上面两篇论文是基于在单机器的深度学习模型,但为了保护数据的安全性,产生了联邦学习,在联邦学习中也有后门攻击。
联邦学习:有A,B,C三个联邦参与者,还有个Boss D ,D先将模型分发给ABC三位,ABC分别用自己的数据训练自己的模型,训练完后将loss全部传给D取平均,D进行反向传播,然后再讲模型传递给A,B,C多次迭代。
联邦学习的后门攻击存在的原因:联邦学习一般情况有成千上万的参与者,他们并不受中心节点的限制,可能存在着恶意参与者,且该恶意参与者很难检测。
攻击概述:攻击方式其实和在单机上的攻击并没有很大的区别,区别就是在联邦学习是在多机器模型上的,选择一个或者多个机器作为恶意机器,用插入后门的数据进行训练,然后再提交至中心节点中,从而导致D中模型存在后门。但是论文中提出,这种攻击效率的接货并不理想,即使每次迭代都带上后门数据,它的效果也并不理想。
考虑到本地客户端中数据与全局数据的非独立同分布问题(Non-IID),每个本地模型可能远离目前的全局模型。当全局模型收敛时,这些偏差开始抵消,会产生整合的模型把后门给遗忘掉了。因此,攻击者按照下式处理拟提交的模型:
攻击方式:
朴素方法,训练数据包含正确标签输入和后门输入去帮助模型认出区别。改变局部学习率和局部批次来最大限度地适应后门数据,这种攻击很快更新全局模型,因此引入后门,但是这种方式有根本的局限就是他会很快忘记后门。这里的理解就是你和计算机说一张绿色的汽车图片是鸟,但是只是说了一次,随着时间的推移,计算机会忘记。
模型替代,用攻击者想得到的模型x替代模型Gt+1


在这里,1到m的的局部模型里面有一个属于攻击者,根据式子1可以求出攻击者应该生成的本地模型不知道n和η可以迭代提升这个数然后衡量模型在后门攻击的准确率来确定,所以这里讲的是单一攻击,指的是只是发起一次攻击。个人理解,由于模型分发给分部,恶意攻击者可以根据本地恶意数据去检测当前训练的模型成果如何来调整权重。
PS:这篇文章的代码还没跑过,由于联邦学习机器顶不太住,等开学后有机器后再试试。
PS:后面攻击类还没更新完,现在几篇文章都是大概,每一篇文章还会读上几遍,后面有错误或者不足继续改进。(先跑代码去了)