mindspore详解
MindSpore1.6这个版本确实开发了比较长的时间,原因有两个:
- 一是MindSpore1.6做了大量的架构性的特性,工作量比较大;
- 二是团队也开始逐步掌控自己的节奏,争取把每个特性打磨好。
所以说跳票本身不是一个坏事。
下面,我想介绍一下MindSpore1.6的一些大的改进:
架构类的大特性
1、完善了静态图的控制流,支持副作用,灵活的微分
经过长达一年的设计和开发,静态图控制流的架构终于稳定了,采用了创新的闭包方案,以前存在的不支持副作用、子图膨胀等问题都得到了解决。
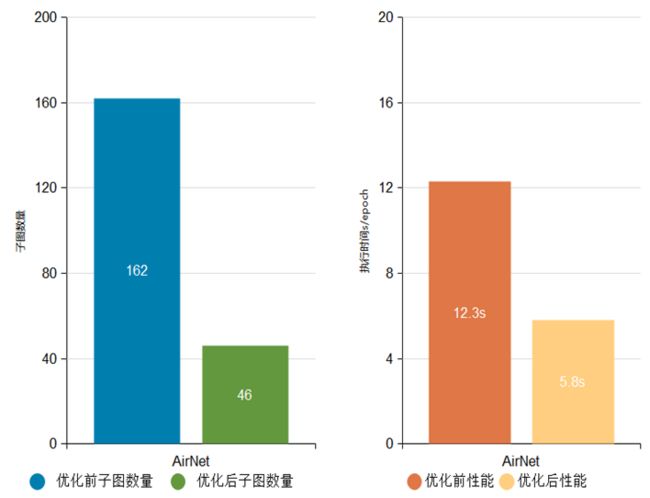
例如:AirNet网络子图数量由原来的162个降低至46个,减少了大量冗余计算,执行性能由12.3s/epoch优化至5.8s/epoch。
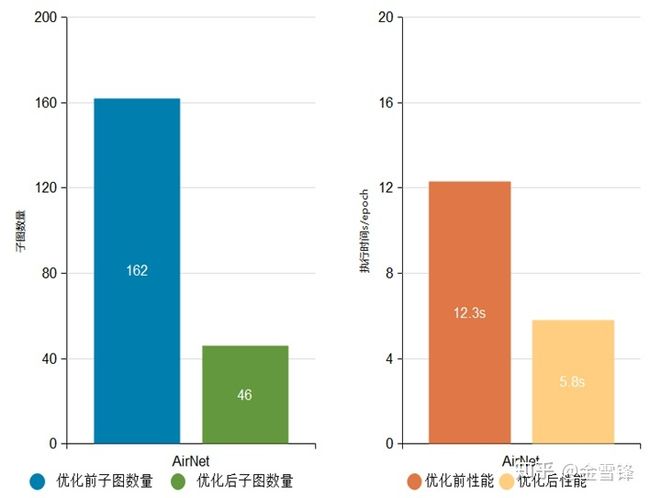
AirNet网络优化前后子图数量与执行性能对比
BFGS网络子图数量由原来的3236个降低至91个,执行性能由4.9s/epoch优化至0.6s/epoch。

2、端边云的异构运行时全部统一
我们原来在电信设备里面有一个支持异构的实时运行时,特点是资源占用少、性能高、支持异构芯片的调度;这次MindSpore重用了这个能力,基于此构建端边云统一的运行时,既能在手机上跑,也能在数据中心跑;同时我们在运行时上面增加了一个scheduler,实现算子、子图等灵活的调度模型。
3、初步构建JIT Fallback的基础架构
大家知道Python下面动态图到静态图转换一直存在很多困难,对研究到产业部署带来了很多不便,MindSpore1.6初步构建了JIT Fallback的能力,在Python AST转换到静态图的时候,如果有不认识的语法可以fallback到Python解释器,实现更多语法的兼容,这个特性当前还在持续完善中,不过已经取得了不错的效果。
4、自定义算子能力全面升级,统一Custom接口帮助用户高效添加算子
由于积累时间短,MindSpore当前在算子支持方面还是相对薄弱的,MindSpore内置的静态的算子库可能无法满足用户的需求,之前版本的MindSpore的自定义算子功能也存在着平台覆盖不到位,开发过程繁琐及第三方算子接入困难的问题。为了提供更好的自定义算子体验,1.6版本全面升级了自定义算子的能力,提供支撑包括Ascend,GPU和CPU在内的多平台的统一算子开发接口Custom,帮助用户在MindSpore方便快捷地进行不同类型自定义算子的定义和使用,可以满足包括快速验证,实时编译和第三方算子接入等不同场景下的用户需求。
查看文档:
自定义算子(基于Custom表达) - MindSpore master documentationwww.mindspore.cn/docs/programming_guide/zh-CN/r1.6/custom_operator_custom.html
- 多场景、多平台的统一算子开发接口
1.6版本提供统一的算子开发接口Custom,实现了不同方式自定义算子的接口和使用统一。其提供的模式包括基于JIT编译的算子编译器开发模式、针对极致性能的aot模式和针对快速验证的pyfunc模式,方便网络开发者根据需要灵活选用不同的自定义方式。
此外统一的算子开发接口整合了当前MindSpore支持的不同平台,包括Ascend,GPU和CPU,以及新增的AICPU平台,减少了用户针对不同平台算子开发的学习成本。
- 自定义算子一键接入,方便快捷
1.6版本提供的自定义算子可以帮助用户在MindSpore的Python端快速的定义算子,把算子作为网络表达的一部分,无需对MindSpore框架进行侵入式修改和重新编译。此外提供了自动生成注册信息的能力,实现自定义算子一键接入网络,极大的简化了自定义算子的开发流程。用户在使用时完全不感知框架相关的设定,让用户更加关注计算本身。
- 新的自定义算子类型支持:AICPU
1.6版本新增了AICPU类型算子的支持,该类算子对应的硬件架构为ARM架构,采用aot模式编译,可以快捷地部署到主流嵌入式平台上。AICPU算子相对于TBE算子,擅长逻辑类操作,采用C/C++开发,类似于CPU算子开发,对于一些难以向量化的算子,有较大的性能收益。
查看文档:https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.6/custom_operator_custom.html#aicpu
易用性提升
易用性是MindSpore未来一段时间的工作重点,1.6版本也做了大量的易用性改进和提升特性
1、资料优化
对开发者反馈较多的API问题进行整改优化,并打造系列教程,帮助开发者上手;同时,我们积极吸纳开发者参与内容建设,累计吸引142名外部开发者贡献610+技术干货案例,覆盖安装、开发调优等关键场景,为开发者提供经验指导。
2、模型迁移工具 MindConvert:支持第三方框架模型的一键迁移
模型工具采用IR到IR的转换方案,转换后的模型可推理可重训(权重也一起迁移),模型脚本可读性较好。模型迁移工具支持以下两种转换方式:基于ONNX IR的转换、基于TorchScript IR的转换(针对Pytorch)。
使用手册:https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.6/migrate_3rd_scripts_mindconverter.html
开源社区:https://gitee.com/mindspore/mindinsight/issues
3、提供IDE开发插件 MindSpore Dev ToolKit
MindSpore Dev ToolKit开发套件包含运行管理,智能知识搜索与智能代码补全功能,致力于让所有用户摆脱环境干扰,学习人工智能,让人工智能回归算法本身。
- 一键环境管理,5分钟完成环境搭建上手MindSpore实践
基于Conda提供科学的MindSpore环境管理方式,能快速将MindSpore及依赖安装在独立环境中并部署最佳实践。该能力兼容Ascend、GPU、CPU多平台,隐蔽不同环境适配的繁琐细节,让用户在打开IDE后一键运行AI算法。最快能在5分钟内体验用MindSpore学AI的乐趣,内测数据显示80%的AI零基础用户使用该功能可在20分钟内完成环境配置与算法运行。
- 沉浸式MindSpore生态知识智能搜索,用户零压力接入MindSpore生态
基于语义搜索等能力,在Dev Toolkit内提供全面的MindSpore知识内容检索,对算子而言,PyTorch/TensorFlow框架用户只需在IDE内查询相应算子,即可快速准确找到MindSpore框架中的对应实现并获得详细文档支持,从而无压力切换到MindSpore生态中。
- 基于深度学习的智能代码补全,单模型开发键盘敲击次数可减少30%
Dev Toolkit基于MindSpore ModelZoo等最佳实践数据集构造的智能代码补全模型实现的智能代码补全功能,让用户在编写MindSpore相关代码时获取实时提示,补全达80%的高准确性将加速用户编码,目前内测数据显示编码时键盘敲击次数可减少30%以上。
详情参考:https://gitee.com/mindspore/ide-plugin
GNN和强化学习的架构创新
1、MindSpore Graph Learning:公式即代码,训练加速3到4倍
图数据能自然表达真实世界对象之间的关系,表征能力和可解释性强,图学习也逐步广泛应用于电商推荐、金融风控、药物分子分析和控制优化等场景,图关系大都错综复杂,数据规模较大,通常有数十亿点,数百亿边,点边类型有几百种,图神经网络计算更加复杂耗时,因此迫切需要高效的图神经网络系统。同时,GNN算法的快速发展,需要易用的系统允许自由扩展。
MindSpore Graph Learning是由James Cheng课题组(香港中文大学)、华为MindSpore团队联合研发的图学习框架,具有高效性、易用性等特点。

- 易用性:公式即代码
通过创新性的提出以节点为中心的编程范式,相较于消息传递范式,更贴近GNN算法逻辑和Python语言风格,MindSpore Graph Learning可以做到公式到代码的直接映射,如下图GAT网络代码所示。基于此,用户无需进行任何函数封装,即可快速直接地实现自定义的GNN算法/操作。

- 高效性:训练加速3到4倍
基于MindSpore的图算融合和自动算子编译技术(AKG)特性,创新提出基于索引的非规则内存访问算子融合,自动识别GNN模型运行任务特有执行pattern并进行融合和kernel level优化。相较于其他框架对常用算子进行定制优化的方案更加灵活,更具扩展性,能够覆盖现有框架中已有的算子和新组合算子的融合优化。以MindSpore作为后端,MindSpore Graph Learning能使GNN网络训练获得3到4倍的性能加速。
- 丰富性:覆盖业界典型图学习网络
框架中已经自带实现十三种图网络学习模型,涵盖同构图、异构图、 随机游走等类型的应用网络。
详情请参考这里:https://gitee.com/mindspore/graphlearning/tree/research/model_zoo
2、高性能可扩展的强化学习计算框架:MindSpore Reinforcement
强化学习(RL)是近年来AI领域的研究热点之一,伴随MindSpore 1.6版本推出了与英国帝国理工大学Peter教授合作的强化学习计算框架MindSpore Reinforcement,通过框架中的Python 编程API以及算法与执行分离的设计使其具有易编程,可扩展等特点,期望带给用户一个全新的开发体验。
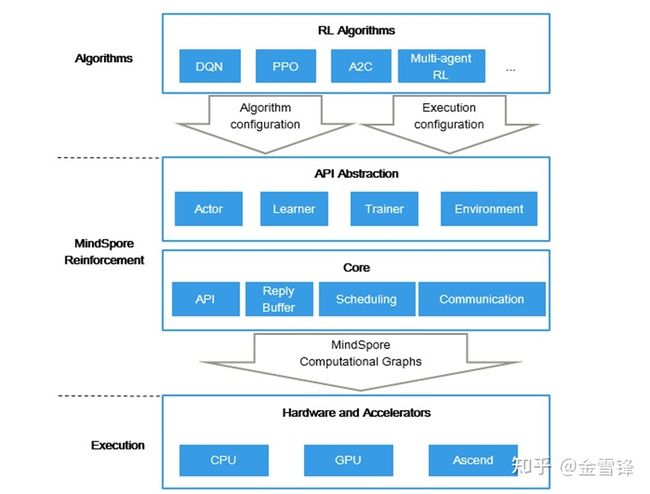
在MindSpore Reinforcement 0.2版本中提供了一套面向强化学习领域的Python编程API,例如Actor用于环境交互获得奖励,Learner学习并更新策略,以及Trainer用于控制算法逻辑等抽象,使整个算法结构更加清晰、简洁,有助于高效的算法开发和模块复用;另外在仓库中内置了一些经典的强化学习算法,如DQN、PPO等(后续版本中将会持续更新),用户可直接运行其中的算法,或者基于Python API开发新的单智能体以及多智能体强化学习算法。
MindSpore Reinforcement在架构设计上采用了算法表达和编译执行分离的设计思路,用户仅需要专注于强化学习算法逻辑的Python实现,依托于MindSpore强大的编译优化以及多硬件异构加速能力,可以实现强化学习算法的多硬件协同计算加速。
在计算设备上,MindSpore Reinforcement支持包括Ascend、GPU、CPU在内的多硬件计算,当前0.2版本已支持单机训练,后续版本将提供更强大的多智能体分布式训练能力,以及更加丰富的特性支持,敬请大家持续关注。
查看文档:https://www.mindspore.cn/reinforcement
MindSpore Lite推理端的加强
1、通过异构并行技术,深度挖掘硬件算力提升推理性能
此版本中,MindSpore Lite新增异构并行功能,该功能感知异构硬件能力,使能多个底层硬件并行执行推理,最大限度利用端侧有限的硬件资源,提升推理效率。
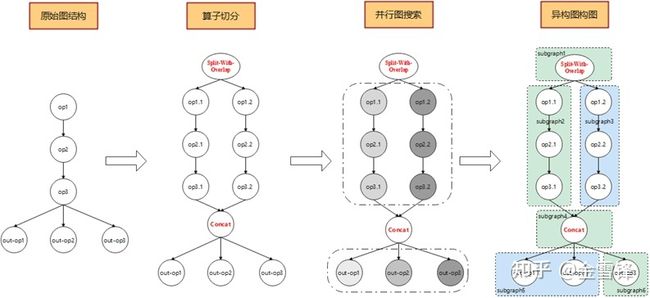
异构并行功能会在构图阶段,根据异构硬件的能力进行构图操作。构图操作分为切分算子与构造异构图两部分。切分算子会将原本不适合异构并行的模型重构成适合异构并行的,且并行分支的运算量能够严格匹配异构硬件的执行能力。构造异构图操作会根据模型现有的图结构进行并行子图搜索,最终确定异构并行图。构图的整体解决方案不局限于模型原始结构,使得异构并行可以应用于泛化模型。
MindSpore Lite在当前版本实现了GPU与CPU的异构并行,使用Mobilenet-V1网络实测验证,有5%左右的性能提升。
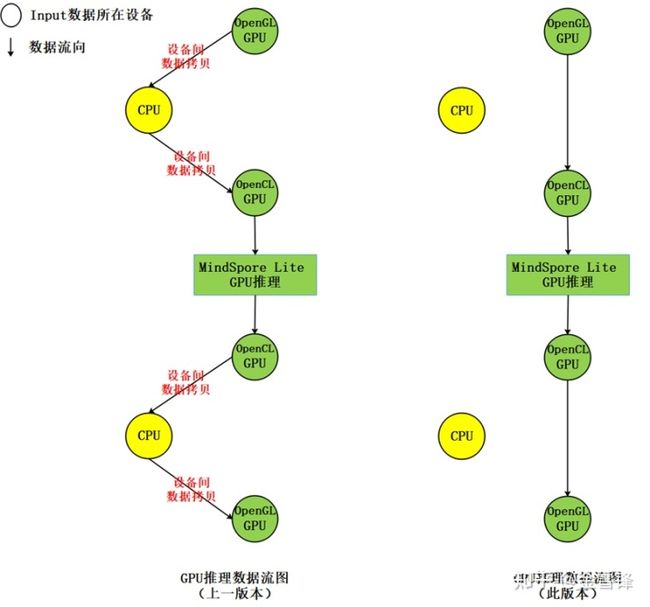
2、优化GPU推理性能,支持将OpenGL纹理数据作为输入和输出数据
此版本中,MindSpore Lite支持将OpenGL纹理数据作为推理模型的输入,推理输出结果也为OpenGL纹理,实现端到端推理过程中,减少CPU和GPU间的数据拷贝,从而达到提升推理性能降低功耗的目的;相比上一版本,能够减少四次设备间的内存拷贝,示意如下图:
AI+科学计算的更新
- MindQuantum升级到0.5
查看文档:
MindQuantum文档 - MindSpore master documentationwww.mindspore.cn/mindquantum/docs/zh-CN/r0.5/index.html正在上传…重新上传取消
- MindSpore Science发布蛋白质结构预测的训练和推理
参考:
昇思 MindSpore 再突破:蛋白质结构预测训练推理全流程开源,助力生物医药发展biopic.pku.edu.cn.https.jxutcmtsg.proxy.jxutcm.edu.cn/xwzx/kyjz/520032.htm
查看文档:
MindSpore/mindsciencegitee.com/mindspore/mindscience/tree/master/MindSPONGE/mindsponge/fold正在上传…重新上传取消