RuntimeError: Error(s) in loading state_dict for BASE_Transformer
最近跑一个深度学习变化检测的项目BIT_CD,严格按照作者的说明页进行训练和测试,但是跑出来的模型就是无法正常工作,而用作者的预训练模型就正常工作,百思不得其解,根据错误,逐步调试,输出,总算是找到了问题的所在!
其实这个问题如果对于老手,估计一下子就解决了,但是对于刚刚接触深度学习的新人,要发现并且解决这个问题确实需要费不少功夫。
那么,这里就记录一下这个问题的解决过程!
首先,错误的具体内容如下:
Traceback (most recent call last):
File "D:/Tools/MyScript/BIT_CD/eval_cd.py", line 58, in
main()
File "D:/Tools/MyScript/BIT_CD/eval_cd.py", line 54, in main
model.eval_models(checkpoint_name=args.checkpoint_name)
File "D:\Tools\MyScript\BIT_CD\models\evaluator.py", line 158, in eval_models
self._load_checkpoint(checkpoint_name)
File "D:\Tools\MyScript\BIT_CD\models\evaluator.py", line 70, in _load_checkpoint
self.net_G.load_state_dict(checkpoint['model_G_state_dict'])
File "D:\MyItems\Anaconda\envs\pytorch\lib\site-packages\torch\nn\modules\module.py", line 1483, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for BASE_Transformer:
size mismatch for transformer_decoder.layers.0.0.fn.fn.to_q.weight: copying a param with shape torch.Size([512, 32]) from checkpoint, the shape in current model is torch.Size([64, 32]).
size mismatch for transformer_decoder.layers.0.0.fn.fn.to_k.weight: copying a param with shape torch.Size([512, 32]) from checkpoint, the shape in current model is torch.Size([64, 32]).
size mismatch for transformer_decoder.layers.0.0.fn.fn.to_v.weight: copying a param with shape torch.Size([512, 32]) from checkpoint, the shape in current model is torch.Size([64, 32]).
size mismatch for transformer_decoder.layers.0.0.fn.fn.to_out.0.weight: copying a param with shape torch.Size([32, 512]) from checkpoint, the shape in current model is torch.Size([32, 64]). 根据页面提示的错误,可以知道是加载模型中的state_dict维度不匹配。
于是,我尝试输出预训练模型,和我自己训练的模型的内容进行比较。
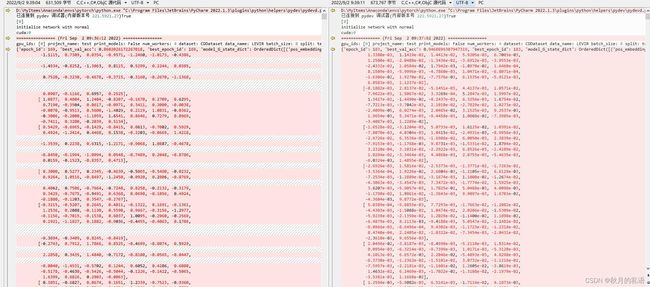
结果,我一脸懵逼,看不出个所以然来,维度太高,括号太多,根本没法看。
但是可以注意到,两个模型中都存在model_G_state_dict关键字。
因为这样实在不好看维度,于是我换了一个输出方式,查看了mydict的类型,直接输出维度。
mydict = checkpoint['model_G_state_dict']
for k, v in mydict.items():
print (k, '========' ,v.shape)此时问题一目了然,中间层的维度不对,跟报错内容一致。
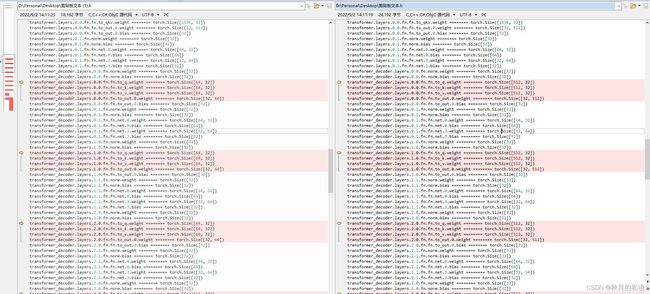
作者的预训练模型中间某个维度是64,32 而我训练出来的模型是512,32。
根据出错的提示
BASE_Transformer
以及transformer_decoder.layers,继续寻找出错位置。
经过整个工程搜索,来到代码位置:
class BASE_Transformer(ResNet):
"""
Resnet of 8 downsampling + BIT + bitemporal feature Differencing + a small CNN
"""
def __init__(self, input_nc, output_nc, with_pos, resnet_stages_num=5,
token_len=4, token_trans=True,
enc_depth=1, dec_depth=1,
dim_head=64, decoder_dim_head=64,
tokenizer=True, if_upsample_2x=True,
pool_mode='max', pool_size=2,
backbone='resnet18',
decoder_softmax=True, with_decoder_pos=None,
with_decoder=True):
super(BASE_Transformer, self).__init__(input_nc, output_nc,backbone=backbone,
resnet_stages_num=resnet_stages_num,
if_upsample_2x=if_upsample_2x,
)断点调试,跳出,得到位置:
self.net_G = define_G(args=args, gpu_ids=args.gpu_ids)输出这个self.net_G查看,可以发现此处的模型与预训练的模型已经不一致,那为何不一致呢?
关键跳转函数:
def define_G(args, init_type='normal', init_gain=0.02, gpu_ids=[]):
if args.net_G == 'base_resnet18':
net = ResNet(input_nc=3, output_nc=2, output_sigmoid=False)
elif args.net_G == 'base_transformer_pos_s4':
net = BASE_Transformer(input_nc=3, output_nc=2, token_len=4, resnet_stages_num=4,
with_pos='learned')
elif args.net_G == 'base_transformer_pos_s4_dd8':
net = BASE_Transformer(input_nc=3, output_nc=2, token_len=4, resnet_stages_num=4,
with_pos='learned', enc_depth=1, dec_depth=8)
elif args.net_G == 'base_transformer_pos_s4_dd8_dedim8':
net = BASE_Transformer(input_nc=3, output_nc=2, token_len=4, resnet_stages_num=4,
with_pos='learned', enc_depth=1, dec_depth=8, decoder_dim_head=8)
else:
raise NotImplementedError('Generator model name [%s] is not recognized' % args.net_G)
return init_net(net, init_type, init_gain, gpu_ids)最终定位到原因,原来训练模型和测试模型使用的模型不同!
于是这就好办了,修改测试代码模型参数即可。
parser.add_argument('--net_G', default='base_transformer_pos_s4_dd8_dedim8', type=str,
help='base_resnet18 | base_transformer_pos_s4_dd8 | base_transformer_pos_s4_dd8_dedim8|')至此,成功训练并测试模型,问题解决!
虽然是个并不复杂的问题,但是我花了一天半的时间才完全解决,解决的过程中经过了无数次的尝试,测试和分析,最终成功解决了问题!
回过头看,这其实是一个很简单的问题,但是我仍然很高兴自己能够逐步分析,测试,最终找到正确的解决办法,而做到更深入地理解了代码。
本次遇到的问题比较特别,在网上几乎找不到答案,但是找到了跟我遇到相同问题的人,不管怎么说,这都是一件值得纪念的事情。