一元线性回归及案例(Python)
目录
1 一元线性回归简介
2 一元线性回归数学形式
3 案例:不同行业工龄与薪水的线性回归模型
3.1 案例背景
3.2 具体代码
3.3 模型优化
4 总体展示
5 线性回归模型评估
6 模型评估的数学原理
6.1 R-squared
6.2 Adj.R-squared
6.3 P值
参考书籍
1 一元线性回归简介
线性回归模型是利用线性拟合的方式探寻数据背后的规律。如下图所示,先通过搭建线性回归模型寻找这些散点(也称样本点)背后的趋势线(也称回归曲线),再利用回归曲线进行一些简单的预测分析或因果关系分析。

在线性回归中,根据特征变量(也称自变量)来预测反应变量(也称因变量)。
根据特征变量的个数可将线性回归模型分为一元线性回归和多元线性回归。
例如,通过“工龄”这一个特征变量来预测“薪水”,就属于一元线性回归;
而通过“工龄”“行业”“所在城市”等多个特征变量来预测“薪水”,就属于多元线性回归。
2 一元线性回归数学形式
一元线性回归模型又称为简单线性回归模型,其形式可以表示为如下所示的公式。
y=ax+b (y为因变量,x为自变量,a为回归系数,b为截距。)
如下图所示,其中![]() 为实际值,
为实际值,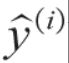 为预测值,一元线性回归的目的就是拟合出一条线来使得预测值和实际值尽可能接近,如果大部分点都落在拟合出来的线上,则该线性回归模型拟合得较好。
为预测值,一元线性回归的目的就是拟合出一条线来使得预测值和实际值尽可能接近,如果大部分点都落在拟合出来的线上,则该线性回归模型拟合得较好。

使用残差平方和衡量实际值与预测值之间的接近程度。
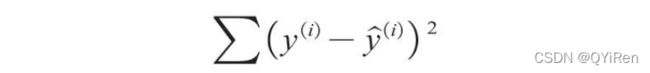
使用最小二乘法求系数与截距。假设线性回归模型的拟合方程为y=ax+b,那么残差平方和(损失函数)可以定义成如下所示的公式。

拟合的目的是使残差平方和尽可能地小,即实际值和预测值尽可能地接近。根据高等数学中求极值的相关知识,通过对残差平方和进行求导(对a和b进行求导),导数为0时,该残差平方和将取极值,此时便能获得拟合需要的系数a和截距b了。

3 案例:不同行业工龄与薪水的线性回归模型
3.1 案例背景
通常来说,薪水会随着工龄的增长而增长,不同行业的薪水增长速度有所不同。本案例要应用一元线性回归模型探寻工龄对薪水的影响,即搭建薪水预测模型,并通过比较多个行业的薪水预测模型来分析各个行业的特点。
3.2 具体代码
# 导入设置
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
#读取数据
df = pd.read_excel('IT行业收入表.xlsx')
df.head(10)
X = df[['工龄']] #这里的自变量必须写成二维形式,一个因变量可能对应多个自变量
Y = df['薪水']
# 模型搭建
model = LinearRegression()
model.fit(X,Y)
# 模型可视化
plt.scatter(X,Y)
plt.plot(X,model.predict(X),color='red')
plt.xlabel('工龄')
plt.ylabel('薪水')
plt.show()
#查看系数,截距:线性回归方程构造
model.coef_,model.intercept_
3.3 模型优化
一元多次线性回归模型。
之所以还需要研究一元多次线性回归模型,是因为有时真正契合的趋势线可能不是一条直线,而是一条曲线。根据一元二次线性回归模型绘制的曲线更契合散点图呈现的数据变化趋势。
具体代码如下:
# 用于增加一个多次项内容的模块PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
# 设置最高次项为二次项,为生成二次项数据(x^2)做准备
poly_reg = PolynomialFeatures(degree=2)
# 将原有的X转换为一个新的二维数组X_,该二维数组包含新生成的二次项数据(x^2)和原有的一次项数据(x)。
X_ = poly_reg.fit_transform(X)
model = LinearRegression()
model.fit(X_,Y)
plt.scatter(X,Y)
plt.plot(X,model.predict(X_),color='r')
plt.show()
model.coef_,model.intercept_
说明:
X_此时的结构:
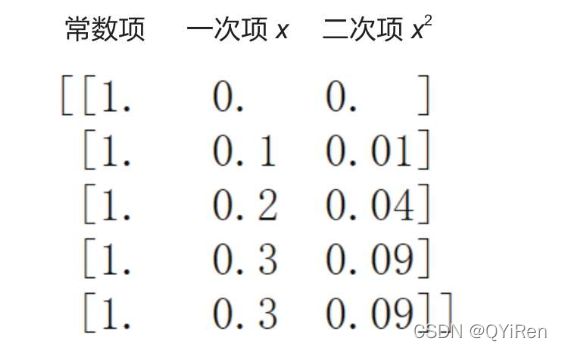
查看系数和截距:

系数,有3个数:第1个数0对应X_中常数项的系数;第2个数对应X_中一次项(x)的系数,即系数b;第3个数对应X_中二次项(x^2)的系数,即系数a。
截距,常数项c。因此,拟合得到的一元二次线性回归方程为y=400.8x2-743.68x+13988。
4 总体展示

5 线性回归模型评估
模型搭建完成后,还需要对模型进行评估,这里主要以3个值作为评判标准:
R-squared(即统计学中的R2)、Adj.R-squared(即Adjusted R2)、P值。
其中R-squared和Adj.R-squared用来衡量线性拟合的优劣,P值用来衡量特征变量的显著性。
R-squared和Adj.R-squared的取值范围为0~1,它们的值越接近1,则模型的拟合程度越高;P值在本质上是个概率值,其取值范围也为0~1,P值越接近0,则特征变量的显著性越高,即该特征变量真的和目标变量具有相关性。
import statsmodels.api as sm
# add_constant()函数给原来的特征变量X添加常数项,并赋给X2,这样才有y=ax+b中的常数项,即截距b
X2 = sm.add_constant(X)
# 用OLS()和fit()函数对Y和X2进行线性回归方程搭建
est = sm.OLS(Y,X).fit()
est.summary()
左下角的coef就是常数项(const)和特征变量(工龄)前的系数,即截距b和斜率系数a。
对于模型评估而言,通常需要关心上图中的R-squared、Adj.R-squared和P值信息。这里的R-squared为0.855,Adj.R-squared为0.854,说明模型的线性拟合程度较高;这里的P值有两个,常数项(const)和特征变量(工龄)的P值都约等于0,所以这两个变量都和目标变量(薪水)显著相关,即真的具有相关性,而不是由偶然因素导致的。
获取R-squared值的另一种方法:
from sklearn.metrics import r2_score
r2 = r2_score(Y,model.predict(X))Y为实际值,regr.predict(X)为预测值,打印输出r2的结果为0.855,与利用statsmodels库获得的评估结果是一致的。
6 模型评估的数学原理
6.1 R-squared
要想理解R-squared,得先了解3组新的概念:整体平方和TSS、残差平方和RSS、解释平方和ESS,它们的关系如下图所示。
其中Yi为实际值,Yfitted为预测值,Ymean为所有散点的平均值,R2为R-squared值。
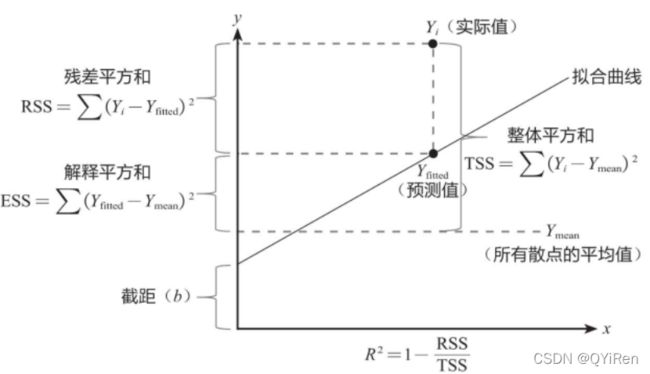
对于一个拟合程度较高的线性回归模型,我们希望其实际值要尽可能落在拟合曲线上,即残差平方和RSS尽可能小,根据R-squared的计算公式R2=1-(RSS/TSS),也就是希望R-squared尽可能大。当RSS趋向于0时,说明实际值基本都落在了拟合曲线上,模型的拟合程度非常高,那么此时R-squared趋向于1,所以在实战当中,R-squared越接近1,模型的拟合程度越高。不过拟合程度也不是越高越好,拟合程度过高可能会导致过拟合现象。
插曲:过拟合与欠拟合
如下图所示,过拟合即过度拟合,是指模型在训练样本中拟合程度过高,虽然它很好地贴合了训练集数据,但是丧失了泛化能力,不具有推广性,也就是说,如果换了训练集以外的数据就达不到较好的预测效果。与过拟合相对应的概念是欠拟合,欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能很好地拟合数据。

6.2 Adj.R-squared
Adj.R-squared是R-squared的改进版,其目的是为了防止选取的特征变量过多而导致虚高的R-squared。每新增一个特征变量,线性回归背后的数学原理都会导致R-squared增加,但是这个新增的特征变量可能对模型并没有什么帮助。为了限制过多的特征变量,引入了Adj.R-squared的概念,它在R-squared的基础上额外考虑了特征变量的数量这一因素,其公式如下。
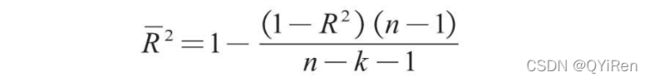
其中n为样本数量,k为特征变量数量。从上述公式可以看出,特征变量数量k越大,其实会对Adj.R-squared产生负影响,从而告诫数据建模者不要为了追求高R-squared值而添加过多的特征变量。当考虑了特征变量数量后,Adj.R-squared就能够更准确地反映线性模型的拟合程度。
6.3 P值
P值涉及统计学里假设检验中的概念,其原假设为特征变量与目标变量无显著相关性,P值是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果该概率越大,即P值越大,原假设为真的可能性就越大,即无显著相关性的可能性越大;如果该概率越小,即P值越小,原假设为真的可能性就越小,即有显著相关性的可能性越大。所以P值越小,显著相关性越大。通常以0.05为阈值,当P值小于0.05时,就认为特征变量与目标变量有显著相关性。
参考书籍
《Python大数据分析与机器学习商业案例实战》