机器学习之LSI:文本主题模型之潜在语义分析(LSI)
机器学习之LSI:文本主题模型之潜在语义分析(LSI)
- 一、潜在语义分析(LSI)概述
- 二、LSI简单示例概述
- 三、LSI主题模型总结
- 四、代码实现
一、潜在语义分析(LSI)概述
-
潜在语义索引(Latent Semantic Indexing,以下简称LSI),也可以称为Latent Semantic Analysis(LSA)。LSI是一种简单实用的主题模型。LSI是基于奇异值分解(SVD)的方法得到本文的主题。
-
SVD分解:对于一个矩阵 A m ∗ n A_{m*n} Am∗n,可以分解为三个矩阵:
A m ∗ n = U m ∗ m Σ m ∗ m V n ∗ n T A_{m*n}=U_{m*m}\Sigma_{m*m}V_{n*n}^T Am∗n=Um∗mΣm∗mVn∗nT
有时为了降低矩阵的维度 k k k,SVD分解可以近似写为:
A m ∗ n ≈ U m ∗ k Σ k ∗ k V k ∗ n T A_{m*n}\approx U_{m*k}\Sigma_{k*k}V_{k*n}^T Am∗n≈Um∗kΣk∗kVk∗nT
将上式用到主题模型中,SVD可以解释为:输入m个文本,每个文本有n个词, A i j A_{ij} Aij对应于第 i i i个文本中第 j j j个词的特征值,常用的是基于预处理后的标准化TF-IDF值,k是我们的假设的主题数,一般比文本数少。 -
SVD分解后, U i l U_{il} Uil对应第 i i i个文本和第 l l l个主题的相关度; Σ l m \Sigma_{lm} Σlm对应第 l l l个主题和第 m m m个词义的相关度; V m j T V_{mj}^T VmjT对应第 m m m个词义和第 j j j个词的相关度;
-
也可以反过来解释:输入m个词,对应n个文本,因此 A i j A_{ij} Aij表示第 i i i个词档的第 j j j个文本的特征值,常用的是基于预处理后的标准化TF-IDF值,k是我们的假设的主题数,一般比文本数少。SVD分解后, U i l U_{il} Uil对应第 i i i个词和第 l l l个词义的相关度; Σ l m \Sigma_{lm} Σlm对应第 l l l个词义和第 m m m个主题的相关度; V m j T V_{mj}^T VmjT对应第 m m m个主题和第 j j j个文本的相关度;
-
这样通过一次SVD,就可以得到文档和主题的相关度,词和词义的相关度以及词义和主题的相关度。
二、LSI简单示例概述
假设我们有下面这个有11个词三个文本的词频TF对应矩阵如下:
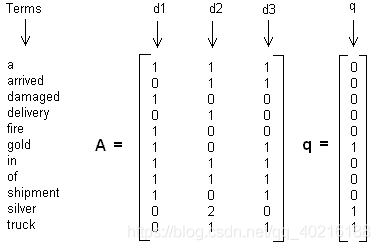
这里我们没有使用预处理,也没有使用TF-IDF,在实际应用中最好使用预处理后的TF-IDF值矩阵作为输入。
我们假定对应的主题数为2,则通过SVD降维后得到三个矩阵分别为:

在上面我们通过LSI得到的文本主题矩阵可以用于文本相似度计算。而计算方法一般是通过余弦相似度。比如对于上面的三文档两主题的例子。我们可以计算第一个文本和第二个文本的余弦相似度如下 :
s i m ( d 1 , d 2 ) = ( − 0.4945 ) ∗ ( − 0.6458 ) + ( 0.6492 ) ∗ ( − 0.7194 ) ( − 0.4945 ) + 0.649 2 2 ( − 0.6458 ) 2 + ( − 0.7194 ) 2 sim(d_1, d_2)=\frac{(-0.4945)*(-0.6458)+(0.6492)*(-0.7194)}{\sqrt{(-0.4945)^+0.6492^2}\sqrt{(-0.6458)^2+(-0.7194)^2}} sim(d1,d2)=(−0.4945)+0.64922(−0.6458)2+(−0.7194)2(−0.4945)∗(−0.6458)+(0.6492)∗(−0.7194)
三、LSI主题模型总结
- 1)优点:
a)原理很简单,一次奇异值分解就可以得到主题模型,同时解决词义的问题。 - 2)缺点:
a)SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解是非常难的;(解决:主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。)
b)主题值的选取对结果的影响非常大,很难选择合适的k值;(解决:较新的层次狄利克雷过程(HDP)可以自动选择主题个数。)
c) LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。(解决:pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。)
四、代码实现
import jieba
from gensim import corpora, models, similarities
from collections import defaultdict
from termcolor import colored
import matplotlib.pyplot as plt
#每行一个文档,共12个文档
documents = ['商业新知:知识图谱为内核,构建商业创新服务完整生态。',
'如何更好利用知识图谱技术做反欺诈? 360金融首席数据科学家沈赟开讲。',
'知识管理 | 基于知识图谱的国际知识管理领域可视化分析。',
'一文详解达观数据知识图谱技术与应用。',
'知识图谱技术落地金融行业的关键四步。',
'一文读懂知识图谱的商业应用进程及技术背景。',
'海云数据CPO王斌:打造大数据可视分析与AI应用的高科技企业。',
'智能产业|《人工智能标准化白皮书2018》带来创新创业新技术标准。',
'国家语委重大科研项目“中华经典诗词知识图谱构建技术研究”开题。',
'最全知识图谱介绍:关键技术、开放数据集、应用案例汇总。',
'中译语通Jove Mind知识图谱平台 引领企业智能化发展。',
'知识图谱:知识图谱赋能企业数字化转型,为企业升级转型注入新能量。']
jieba.add_word('知识图谱')
jieba.add_word('反欺诈')
documents=[' '.join(jieba.lcut(i)) for i in documents]
#去除停用词
stoplist=[i.strip() for i in open('./stop_words.txt',encoding='utf-8').readlines()]
texts=[[word for word in document.lower().split() if word not in stoplist] for document in documents]
print(colored('切词及去除停用词后的文本texts为:', 'red', attrs=[ 'blink'])) #打印彩色的字,blink是加粗
print(texts)
#结果
切词及去除停用词后的文本texts为:
[['商业', '新知', '知识图谱', '内核', '构建', '商业', '创新', '服务', '完整', '生态'], ['更好', '利用', '知识图谱', '技术', '做', '反欺诈', '360', '金融', '首席', '数据', '科学家', '沈赟', '开讲'], ['知识', '管理', '|', '知识图谱', '国际', '知识', '管理', '领域', '可视化', '分析'], ['一文', '详解', '达观', '数据', '知识图谱', '技术'], ['知识图谱', '技术', '落地', '金融', '行业', '关键', '四步'], ['一文', '读懂', '知识图谱', '商业', '进程', '技术', '背景'], ['海云', '数据', 'cpo', '王斌', '打造', '数据', '可视', '分析', 'ai', '高科技', '企业'], ['智能', '产业', '|', '人工智能', '标准化', '白皮书', '2018', '带来', '创新', '创业', '新', '技术标准'], ['国家语委', '科研项目', '中华', '经典', '诗词', '知识图谱', '构建', '技术', '研究', '开题'], ['最全', '知识图谱', '介绍', '关键技术', '开放', '数据', '集', '案例', '汇总'], ['中译', '语通', 'jove', 'mind', '知识图谱', '平台', '引领', '企业', '智能化', '发展'], ['知识图谱', '知识图谱', '赋能', '企业', '数字化', '转型', '企业', '升级', '转型', '注入', '新', '能量']]
#去掉只出现一次的单词
frequence=defaultdict(int) #字典的值为int型
for text in texts:
for word in text:
frequence[word]=frequence.get(word, 0)+1
print(colored('\n词汇字典降序排列:', 'red', attrs=['blink']))
print(sorted(frequence.items(), key=lambda x:x[1], reverse=True))
#结果
词汇字典降序排列:
[('知识图谱', 11), ('技术', 5), ('数据', 5), ('企业', 4), ('商业', 3), ('构建', 2), ('创新', 2), ('金融', 2), ('知识', 2), ('管理', 2), ('|', 2), ('分析', 2), ('一文', 2), ('新', 2), ('转型', 2), ('新知', 1), ('内核', 1), ('服务', 1), ('完整', 1), ('生态', 1), ('更好', 1), ('利用', 1), ('做', 1), ('反欺诈', 1), ('360', 1), ('首席', 1), ('科学家', 1), ('沈赟', 1), ('开讲', 1), ('国际', 1), ('领域', 1), ('可视化', 1), ('详解', 1), ('达观', 1), ('落地', 1), ('行业', 1), ('关键', 1), ('四步', 1), ('读懂', 1), ('进程', 1), ('背景', 1), ('海云', 1), ('cpo', 1), ('王斌', 1), ('打造', 1), ('可视', 1), ('ai', 1), ('高科技', 1), ('智能', 1), ('产业', 1), ('人工智能', 1), ('标准化', 1), ('白皮书', 1), ('2018', 1), ('带来', 1), ('创业', 1), ('技术标准', 1), ('国家语委', 1), ('科研项目', 1), ('中华', 1), ('经典', 1), ('诗词', 1), ('研究', 1), ('开题', 1), ('最全', 1), ('介绍', 1), ('关键技术', 1), ('开放', 1), ('集', 1), ('案例', 1), ('汇总', 1), ('中译', 1), ('语通', 1), ('jove', 1), ('mind', 1), ('平台', 1), ('引领', 1), ('智能化', 1), ('发展', 1), ('赋能', 1), ('数字化', 1), ('升级', 1), ('注入', 1), ('能量', 1)]
texts=[[word for word in text if frequence[word]>1] for text in texts]
print(colored('\n切词及去除停用词后,去掉只出现一次的单词后的文本texts为:', 'red', attrs=[ 'blink'])) #blink是加粗
print(texts)
#结果
切词及去除停用词后,去掉只出现一次的单词后的文本texts为:
[['商业', '知识图谱', '构建', '商业', '创新'], ['知识图谱', '技术', '金融', '数据'], ['知识', '管理', '|', '知识图谱', '知识', '管理', '分析'], ['一文', '数据', '知识图谱', '技术'], ['知识图谱', '技术', '金融'], ['一文', '知识图谱', '商业', '技术'], ['数据', '数据', '分析', '企业'], ['|', '创新', '新'], ['知识图谱', '构建', '技术'], ['知识图谱', '数据'], ['知识图谱', '企业'], ['知识图谱', '知识图谱', '企业', '转型', '企业', '转型', '新']]
#生成词典
dictionary=corpora.Dictionary(texts) #进行词典构造时,texts必须是2维的array,即两个中括号[[]]
print(colored('\n词典dictionary为:', 'red', attrs=[ 'blink'])) #blink是加粗
print(dictionary)
#结果
词典dictionary为:
Dictionary(15 unique tokens: ['创新', '商业', '构建', '知识图谱', '技术']...)
#词典保存
dictionary.save('./dictionary.dict')
#加载词典
dictionary=corpora.Dictionary.load('./dictionary.dict')
#查看每个id对应的词汇
print(colored('\n每个词汇对应的ID为:', 'red', attrs=['blink']))
print(dictionary.token2id)
#结果
每个词汇对应的ID为:
{'创新': 0, '商业': 1, '构建': 2, '知识图谱': 3, '技术': 4, '数据': 5, '金融': 6, '|': 7, '分析': 8, '知识': 9, '管理': 10, '一文': 11, '企业': 12, '新': 13, '转型': 14}
'''
设计一套协议,按照某种规则,把内存中的数据保存到文件中,文件是一个个字节序列。
所以必须把数据额转换为字节序列,输出到文件,这就是序列化
反之,将文件的字节序列恢复到内存中,就是反序列化。
序列化Serialization:将内存中对象存储下来,把他变成一个个字节。二进制。
deSerialization反序列化,将文件的一个个字节到内存中。
序列化保存到文件就是持久化。
'''
# 将文本中的词进行向量表示,表示方法为:[(词汇ID, 词频)],没有出现的ID对应的值为0。词汇ID可以使用dictionary.token2id语句查询
#将整个原始预料库转换为向量列表
bow_corpus=[dictionary.doc2bow(text) for text in texts]
print(colored('\n向量表示的corpus为:', 'red', attrs=['blink']))
print(bow_corpus)
#结果
向量表示的corpus为:
[[(0, 1), (1, 2), (2, 1), (3, 1)], [(3, 1), (4, 1), (5, 1), (6, 1)], [(3, 1), (7, 1), (8, 1), (9, 2), (10, 2)], [(3, 1), (4, 1), (5, 1), (11, 1)], [(3, 1), (4, 1), (6, 1)], [(1, 1), (3, 1), (4, 1), (11, 1)], [(5, 2), (8, 1), (12, 1)], [(0, 1), (7, 1), (13, 1)], [(2, 1), (3, 1), (4, 1)], [(3, 1), (5, 1)], [(3, 1), (12, 1)], [(3, 2), (12, 2), (13, 1), (14, 2)]]
#序列化
corpora.MmCorpus.serialize('./dictionary.mm', corpus)
#反序列化
corpus=corpora.MmCorpus('./dictionary.mm')
print(colored('\n反序列化后的corpus为:', 'red', attrs=['blink']))
print(corpus)
#结果
反序列化后的corpus为:
MmCorpus(12 documents, 0 features, 0 non-zero entries)
#查看每个id对应的词汇
print(dictionary.token2id)
#结果
{'创新': 0, '商业': 1, '构建': 2, '知识图谱': 3, '技术': 4, '数据': 5, '金融': 6, '|': 7, '分析': 8, '知识': 9, '管理': 10, '一文': 11, '企业': 12, '新': 13, '转型': 14}
#将新文本进行向量表示
new_doc='知识图谱 这种 技术 是 企业 转型 的 利器'
new_vec=dictionary.doc2bow(new_doc.lower().split())
new_vec #每个元组中的第一个元素对应字典中的词汇ID,第二个条目对应于该词汇的计数。
[(3, 1), (4, 1), (12, 1), (14, 1)]
#训练模型
tfidf=models.TfidfModel(bow_corpus) #bow_corpus是经过向量表示的
#对"知识图谱这种技术是企业转型的利器"进行转换
print(tfidf[dictionary.doc2bow("知识图谱 这种 技术 是 企业 转型 的 利器".split())])
#结果
[(3, 0.06112717038912965), (4, 0.29351946977430854), (12, 0.46478459877035777), (14, 0.8331176787522306)]
TF-IDF模型再次返回元组列表,每个元组的第一个元素是词汇ID,第二个条目是TF-IDF加权值。
注意,对应于“知识图谱”的ID(在训练语料库中出现11次)的加权值低于对应于“转型”的ID(在训练语料库中出现2次)权重值。
#将整个corpus转为tf-idf格式
corpus_tfidf=tfidf[bow_corpus]
print(list(corpus_tfidf))
#结果
[[(0, 0.4078964886286983), (1, 0.8157929772573966), (2, 0.4078964886286983), (3, 0.04150575124328046)], [(3, 0.07982263066186342), (4, 0.38329103210095783), (5, 0.48098603643475885), (6, 0.7844544378738532)], [(3, 0.02439597257041438), (7, 0.23975066707809753), (8, 0.23975066707809753), (9, 0.6649977713472272), (10, 0.6649977713472272)], [(3, 0.07982263066186342), (4, 0.38329103210095783), (5, 0.48098603643475885), (11, 0.7844544378738532)], [(3, 0.0910460341905888), (4, 0.43718339178067905), (6, 0.8947520894690928)], [(1, 0.6668011702142979), (3, 0.06785075201967737), (4, 0.32580465658435587), (11, 0.6668011702142979)], [(5, 0.6962169034343767), (8, 0.5677404313752555), (12, 0.4392639593161345)], [(0, 0.5773502691896257), (7, 0.5773502691896257), (13, 0.5773502691896257)], [(2, 0.8947520894690927), (3, 0.09104603419058879), (4, 0.437183391780679)], [(3, 0.16371704169295062), (5, 0.9865073391816752)], [(3, 0.13039433685974838), (12, 0.9914622115415728)], [(3, 0.061003335283038695), (12, 0.4638430101162164), (13, 0.29975419684301086), (14, 0.83142989874413)]]
#主题模型-LSI模型
lsi_model=models.LsiModel(corpus=corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi=lsi_model[corpus_tfidf]
print(colored('corpus_lsi:', 'red', attrs=['blink']))
print(list(corpus_lsi))
#结果
corpus_lsi:
[[(0, 0.22347248858697483), (1, 0.5571237715330626)], [(0, 0.8004143713256646), (1, 0.0433766900882087)], [(0, 0.0569390946475263), (1, -0.08723221126645597)], [(0, 0.7371726670892296), (1, 0.1404378698572133)], [(0, 0.5491014883795404), (1, 0.2563547177937334)], [(0, 0.4752352264726161), (1, 0.5743173473040204)], [(0, 0.6252018576348566), (1, -0.603268752206104)], [(0, 0.04818000367718453), (1, 0.056131194933339575)], [(0, 0.30634934437825534), (1, 0.4200654636428412)], [(0, 0.6773488856224471), (1, -0.3735678527259487)], [(0, 0.21733391709000002), (1, -0.5194760888989548)], [(0, 0.14560597632023212), (1, -0.41050982257035395)]]
#打印topic的含义
print(colored('\n打印topic的含义:', 'red', attrs=['blink']))
print(lsi_model.print_topics(2))
#结果
打印topic的含义:
[(0, '0.663*"数据" + 0.403*"金融" + 0.402*"技术" + 0.322*"一文" + 0.201*"企业" + 0.180*"商业" + 0.141*"知识图谱" + 0.133*"分析" + 0.131*"构建" + 0.044*"转型"'), (1, '-0.523*"企业" + 0.451*"商业" + -0.377*"数据" + 0.325*"构建" + 0.298*"技术" + 0.266*"一文" + -0.196*"分析" + -0.184*"转型" + 0.142*"金融" + 0.140*"创新"')]
#保存模型及导入模型
lsi_model.save('./model.lsi')
lsi_model=models.LsiModel.load('./model.lsi')
#主题模型-LDA模型
lda_model=models.LdaModel(corpus=corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lda=lda_model[corpus_tfidf]
print(colored('corpus_lda:', 'red', attrs=['blink']))
print(list(corpus_lda))
#结果
corpus_lda:
[[(0, 0.4729983), (1, 0.52700174)], [(0, 0.613525), (1, 0.3864751)], [(0, 0.78188574), (1, 0.21811427)], [(0, 0.30010045), (1, 0.6998995)], [(0, 0.72370994), (1, 0.27629006)], [(0, 0.2895592), (1, 0.7104408)], [(0, 0.24699494), (1, 0.7530051)], [(0, 0.7167036), (1, 0.28329644)], [(0, 0.7320023), (1, 0.26799768)], [(0, 0.2788313), (1, 0.7211687)], [(0, 0.2691675), (1, 0.73083246)], [(0, 0.2285826), (1, 0.7714173)]]
#打印topic的含义
print(colored('\n打印topic的含义:', 'red', attrs=['blink']))
print(lda_model.print_topics(2))
#结果
打印topic的含义:
[(0, '0.099*"金融" + 0.098*"技术" + 0.087*"构建" + 0.078*"数据" + 0.069*"一文" + 0.067*"创新" + 0.064*"管理" + 0.061*"|" + 0.061*"知识" + 0.059*"商业"'), (1, '0.135*"数据" + 0.111*"企业" + 0.086*"商业" + 0.078*"技术" + 0.075*"一文" + 0.066*"转型" + 0.061*"知识图谱" + 0.061*"金融" + 0.054*"新" + 0.051*"创新"')]
#保存模型及导入模型
lda_model.save('./model.lda')
lda_model=models.LdaModel.load('./model.lda')
#文本相似性
corpus_simi_matrix = similarities.MatrixSimilarity(corpus_lsi)
# 计算一个新的文本与既有文本的相关度
test_text = "知识图谱 这种 技术 是 企业 转型 的 利器".split()
test_bow = dictionary.doc2bow(test_text)
test_tfidf = tfidf[test_bow]
test_lsi = lsi_model[test_tfidf]
test_simi = corpus_simi_matrix[test_lsi]
sims = sorted(enumerate(test_simi), key = lambda x : x[1], reverse=True)
print(sims)
#结果
[(6, 0.99382675), (2, 0.9935334), (10, 0.95655894), (11, 0.9389514), (9, 0.9306128), (1, 0.5955406), (3, 0.4827791), (4, 0.25252655), (7, -0.16858944), (5, -0.18634933), (8, -0.24605107), (0, -0.4770087)]
参考网址:
- https://www.cnblogs.com/nlpvv/articles/10953896.html
- https://mp.weixin.qq.com/s/XX-GFKbwFa18lyjVmIAUIg
- https://mp.weixin.qq.com/s/ESjK5XNI1QIXGA5VgjUT2Q