Interspeech 2021 | 腾讯AI Lab解读9篇入选论文
感谢阅读腾讯 AI Lab 微信号第 130 篇文章。本文将介绍腾讯 AI Lab 入选 Interspeech 2021 的 9 篇论文。
Interspeech 是由国际语音通讯协会(International Speech Communication Association, ISCA)创办的顶级旗舰国际会议,作为全球最大的综合性语音信号处理领域的科技盛会,历届 Interspeech 会议都备受全球各地语音语言领域人士的广泛关注
Interspeech 2021 于今年 8 月 30 日 - 9 月 3 日在捷克布尔诺举行。为方便全球各地研究者交流,今年的会议与去年一样,并不区分 oral 和 poster 论文,每篇接收论文都能进行视频展示。
今年,腾讯 AI Lab 共有9篇论文入选 Interspeech 2020,主要包括语音识别、单通道及多通道语音分离增强、声纹识别、语音合成等研究方向。本文将对这些论文进行解读。
语音识别
1. 用于端到端语音识别的多尺度GALR波形编码器
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
论文下载:https://arxiv.org/pdf/2106.04275.pdf
本文由腾讯AI Lab独立完成。现有的端到端语音识别(ASR)系统一般使用人工设计的声学特征作为输入,并将特征提取模块排除在其联合优化之外。为了提取可学习和自适应的特征并减少信息丢失,本文提出了一种新颖的采用全局注意局部递归(GALR)网络、直接以原始波形为输入的编码器。
本文作者观察到,通过在不同的窗口长度上应用GALR来将细颗粒时间信息聚集到多尺度声学特征中,能大大改进ASR性能和鲁棒性。实验在基准数据集AISHELL-2和两个5,000小时和21,000小时的大规模普通话语音语料库上进行。我们提出的多尺度GALR波形编码器具有更快的速度和可比的模型大小,相对于基线系统(包括同形器和TDNN同形器),实现了一致的从7.9% 到28.1%的字符错误率百分比下降(CERR)。
此外,该方法比传统的特征还表现出了显著的鲁棒性,在真实采集的混合音乐的语音测试集上,对照基于MFCC的TDNN-Conformer模型也能达到15.2%的CERR。

2. SpeechMoE: 基于动态路由混合专家网络的大规模声学模型
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
论文下载:https://arxiv.org/pdf/2105.03036.pdf
本文由腾讯AI Lab独立完成。最近,基于混合专家 (MoE) 的 Transformer 模型在许多领域都取得有效进展。这主要是由于该架构的以下优点:首先,基于 MoE 的 Transformer 可以有效增加模型容量,而不会增加训练和推理时的计算成本。此外,基于 MoE 的 Transformer 是一个动态网络,可以适应现实世界应用中不同复杂性的输入实例。
在这项工作中,我们探索了基于 MoE 的语音识别模型,称为SpeechMoE。为了进一步控制路由激活的稀疏性并提高激活的多样性,我们分别提出了L1范式的稀疏损失和平均重要性损失。此外,SpeechMoE 使用了一种新的路由架构,它可以同时利用来自共享embedding网络的信息和不同 MoE 层的分层表示。实验结果表明,与传统静态网络相比,SpeechMoE 可以在计算成本相当的情况下实现更低的字符错误率 (CER),在四个评估数据集上提供 7.0%∼23.0% 的相对 CER 改进。

单通道及多通道语音分离增强
1. 基于时序注意力和环境感知的语音去混响方法
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
论文下载:https://arxiv.org/pdf/2103.16849.pdf
本文由腾讯AI Lab独立完成,探索了利用上下文信息来提高现实世界混响环境中的语音去混响性能的有效方法。
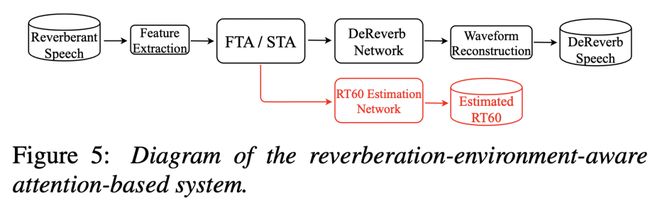
本文在深度神经网络 (DNN) 上提出了一种用于环境感知语音去混响的时间上下文注意方法,可以自适应地处理上下文信息。具体而言,本文提出了一种基于全频带的时间注意方法(FTA),它对上下文帧的全频带信息之间的相关性进行建模。
此外,考虑到房间脉冲响应中高频段和低频段衰减(高频段比低频段衰减快)的差异,本文还提出了一种基于子带的时序注意力方法(STA)。为了引导网络更加了解混响环境,我们以多任务的方式联合优化去混响网络和混响时间(RT60)估计器。我们的实验结果表明,所提出的方法优于我们之前提出的混响时间感知 DNN,并且学习到的注意力权重是与物理现象一致的。我们还报告了真实测试数据上的去混响和识别实验。研究有效的面向真实场景的去混响系统有助于多种语音技术,如自动语音识别等。

2. MetricNet: 无需参考信号的语音质量评估网络
MetricNet: Towards Improved Modeling For Non-Intrusive Speech Quality Assessment
论文下载:https://arxiv.org/pdf/2104.01227.pdf
本文由腾讯AI Lab独立完成。客观的语音质量评估通常是通过将接收到的语音信号与其干净的参考信号进行比较来进行的,而人类可以在没有任何参考的情况下评估语音质量,例如在平均意见分数 (MOS) 测试中。由于在真实场景中无法获得干净的参考信号以进行客观评估,非侵入式语音质量评估最近引起了很多关注。
本文提出了一种新颖的非侵入式语音质量测量模型 MetricNet,它利用标签分布学习和联合语音重建学习来实现,与现有非侵入式语音质量测量模型相比显著提高了性能。本文证明了所提出的方法对干净、嘈杂和处理过的语音数据的语音质量预测与侵入性客观评测达到高度相关性。

3.基于自注意力递归神经网络模型的多人输入多人输出语音分离
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
论文下载:https://arxiv.org/pdf/2104.08450.pdf
本文由腾讯AI Lab主导,与中科院自动化所合作完成。不久之前,作者提出一种基于全深度学习最小方差无失真响应 (ADL-MVDR) 波束形成器方法的循环神经网络 (RNN),通过用两个 RNN 替换矩阵求逆和特征值分解,产生了优于传统 MVDR 的性能。在本文中,作者提出了一种自注意力 RNN 波束形成器,通过利用自注意力的强大建模能力来进一步改进作者之前提出的基于 RNN 的波束形成器。
为了更好地从语音和噪声空间协方差矩阵中学习波束形成权重,本文提出了时空自注意模块,可以帮助 RNN 学习协方差矩阵的全局统计量。空间自注意力模块旨在处理协方差矩阵中的跨通道相关性。此外,本文还开发了多人输入多人输出(MIMO)模型以提高推理效率。评估表明,我们提出的 MIMO 自注意力 RNN 波束成形器相对于现有技术提高了自动语音识别 (ASR) 的准确性和语音质量的感知估计 (PESQ)。

4. 基于递归神经网络的通用时空波束形成器
Generalized Spatio-Temporal RNN Beamformer for Target Speech Separation
论文下载:https://arxiv.org/pdf/2101.01280.pdf
本文由腾讯AI Lab主导,与印第安纳大学合作完成。虽然传统的基于掩码的最小方差无失真响应(MVDR)可以减少非线性失真,但MVDR分离语音的残余噪声水平仍然很高。本文提出了一种基于时空循环神经网络的波束成形器(RNN-BF)用于目标语音分离。这种新的波束成形框架直接从估计的语音和噪声空间协方差矩阵中学习波束成形权重。
利用 RNN 的时间建模能力,RNN-BF 可以自动累积语音和噪声协方差矩阵的统计数据,以递归方式学习帧级波束形成权重。提出了基于 RNN 的广义特征值 (RNN-GEV) 波束成形器和更广义的 RNN 波束成形器 (GRNN-BF)。我们通过使用层归一化代替协方差矩阵上常用的掩码归一化来进一步改进 RNN-GEV 和 GRNN-BF。所提出的 GRNN-BF 在语音质量 (PESQ)、语音信噪比 (SNR) 和词错误率 (WER) 方面获得了优于现有技术的性能。

声纹识别
支持混合语音的多通道说话人识别
Multichannel Speaker Verification for Single and Multi-talker Speech
论文下载:https://arxiv.org/pdf/2010.12692.pdf
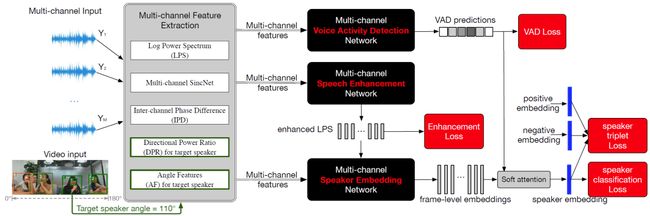
本文由腾讯AI Lab主导,与约翰霍普金斯大学合作完成。说话人识别系统在实际场景中很容易受到其它说话人、噪音和混响的干扰。为了解决这一痛点,本文提出了几种多通道语音特征, 提高说话人识别系统的鲁棒性。
具体来说, 本文利用麦克风阵列, 提出了多种空间和方向特征, 包括通道间相位差、多通道 sinc 卷积、方向功率比特征和角度特征。为了最大化系统性能,该框架还包括了多通道语音增强和VAD语音端点检测,以及所有模块的联合训练。实验证明,在所有模拟、重放和真实录音中,在各种信噪比情况下, 本文的方法都有巨大且一致的改进。在多人语音的真实录音中,相比传统的单通道说话人识别, 本文方法实现了 36% 的EER改进;且在多说话者条件下,本文提出的多通道特征的改进, 比单一说话人条件下的更大。
最后,本文研究了是否可以通过端到端的区分式训练, 使得基于多通道的说话人特征变得更具有区分性。通过简单地选择 Triplet loss,我们观察到 EER 进一步降低了 8.3%。
语音合成
1.基于隐特征学习的高质量语音合成模型
Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder For High Fidelity Flow-based Speech Synthesis
论文下载:https://arxiv.org/pdf/2106.10831.pdf
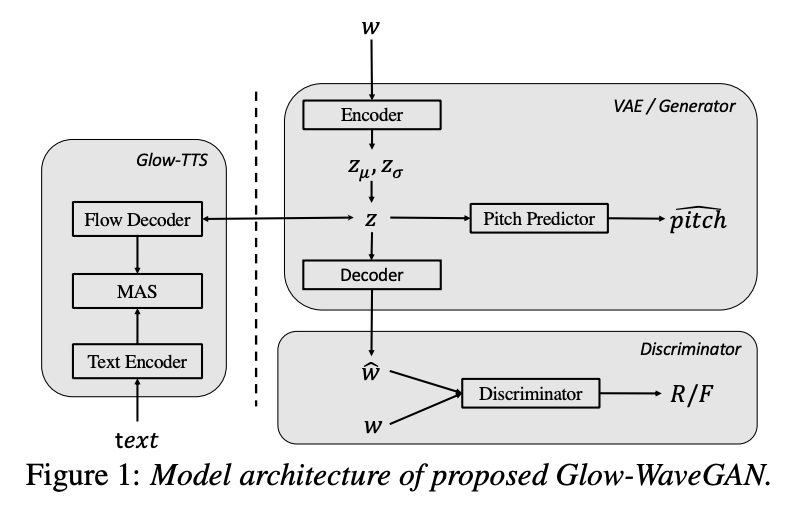
本文由腾讯AI Lab主导,与西北工业大学合作完成。现有的语音合成框架一般分为声学模型和声码器两个部分,其中声学模型主要建模文本到语音特征(如梅尔谱)的映射关系,声码器负责将声学特征还原成语音信号。但是在现有的语音合成框架中声学模型和声码器是分开训练的,这样会导致在实际应用中声学模型预测的声学特征和训练声码器所使用的声学特征存在明显的分布差异,从而导致合成的语音音质较差。
为了解决这个问题,本文不再使用传统的信号处理方法来提取语音特征,而是提出了一种基于VAE和GAN的隐层语音特征学习模型。该模型中的提取器能够从语音中直接提取隐层分布表示,而其中的还原模块能够从符合该分布的样本中还原出高质量的语音信号。基于此,我们提出使用基于flow的声学模型来从文本中直接建模上述隐层特征的分布形式,从而解决现有语音合成系统中声学模型和声码器的不匹配问题。实验结果表明,本文提出的Glow-WaveGAN框架不需要任何模型微调过程,就能从文本中生成高质量的语音信号。

2. 基于上下文感知的可控对话语音合成
Controllable Context-aware Conversational Speech Synthesis
论文下载:https://arxiv.org/pdf/2106.10828.pdf
本文由腾讯AI Lab主导,与西北工业大学合作完成,构建了一个可控的口语化语音合成系统,使合成语音更自然。
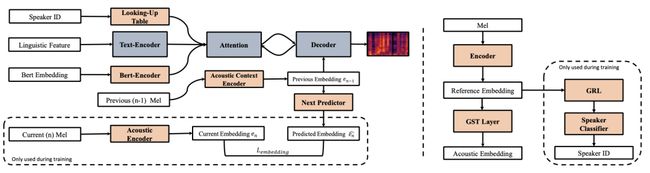
自然口语对话中总是存在诸如停顿和延音之类的自发行为,同时说话的双方倾向于将他们的风格和方式与彼此对齐,也即随着对话的进展两个人说话方式或风格会越来越像。为了合成更加拟人的对话,本文提出了一种可控的自发对话语音合成框架来建模口语中的自发性发音行为,从而获得更加逼真的合成语音。
具体而言,本文使用不同的自发行为标签来描述上述自发行为,并提出了一种自发行为预测算法来控制文本中自发行为的发生频率,从而控制合成语音的口语化程度。此外,该方法还加入了一个上下文声学编码器来建模上述提到的对话中存在的语音彼此影响的现象,并通过对抗训练的方式来消除其中包含的说话人相关的信息。

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)