学术加油站|FLAT,一个轻量且高效的基数估计模型
编者按
本文系东北大学李俊虎所著,本篇也是「 OceanBase 学术加油站」系列稿件第七篇。
「李俊虎:东北大学计算机科学与工程学院在读硕士生,课题方向为数据库查询优化,致力于应用 AI 技术改进传统基数估计器,令数据库选择最优查询计划。」
今天分享的主题是 《FLAT,一个轻量且高效的基数估计模型》,主要介绍了 FLAT 提出的 FSPN 模型,提出了数据库查询优化的新思路。希望阅读完本文,你可以对这个话题有新的收获,有不同看法也欢迎在底部留言探讨。
*原文《FLAT:Fast, Lightweight and Accurate Method for Cardinality Estimation》,发表于 VLDB 2021。
准确的基数估计对数据库查询优化至关重要。基数估计的核心问题在于如何构建可靠的联合分布以应对复杂的连接查询,而难点在于如何有效处理属性之间,乃至表之间的关联性。近几年的研究中,人们开始尝试借助 ML 模型解决这一问题,但就目前而言,大部分的模型要么过于简单以至于准确率不足,要么过于复杂导致时间成本高昂。
FLAT 提出了 FSPN 模型 —— 一个基于数据驱动,基于 SPN 的无监督模型。理想的基数估计模型应当同时满足高精确,快反应,低存储三大特点,而 FSPN 模型在这三面均有卓越的表现。总体的思路可以归纳为:
-
在单表内,将强关联属性和弱关联属性区分开来,并分别建模。
-
在涉及多表的查询中,则将相关的多个表聚合为一个节点并建模。
-
该模型天然地支持对属性的范围查询 (但本文不讨论 like 模糊查询),同时支持单表查询和多表查询,支持增量更新。
属性关联对基数估计的影响
为了说明问题,这里举一个简单的例子。以此条简单的查询 Q 为例子:
SELECT * FROM stu WHERE name='me' AND Id='10001'
假设表中有 10 条数据,但仅有 1 条数据同时满足这两个谓词。在独立性假设成立的条件下,事件 E1={name=’me’} 和事件 E2={Id=’10001’} 相互独立,则查询 Q 的命中率可简单计算为:P(Q)= P(name=’me’)·P(Id=’10001’}=0.01。
然而,该计算结果明显和实际情况不符,原因是没有考虑到这两个属性列之间潜在的关联性。考虑到现实场景,name 和 id 两属性列可被认为是存在函数依赖的关系。在此合理假设 P(Id = ‘10001’ | name = ‘me’ ) 的概率为 1,则 P(name=‘me’, id = ‘10001’ ) = P(Id = ‘10001’ | name = ‘me’ )·P(name = ‘me’) = 0.1
尤其是对于 data-driven 的基数估计而言,核心任务是借助模型对条件概率 P(A|C) 做准确估计。在这个例子中,P(A) 被分解为多项式乘积的形式,该过程也称因子分解。
本文指出,目前的因子分解可以分为独立因子分解 independent factorization 和条件因子分解 conditional factorization。对于独立因子分解,目前流行的方法有 Histogram,SPN 模型等,虽然性能达标,但属于有损分解;对于条件因子分解而言,目前提出的方法有深度自回归网络[1][2][3],贝叶斯网络[4][5]等,虽然可实现无损分解,但是时间成本更高。本文则提出综合利用两种因子分解:对于弱关联属性使用独立因子分解;对于强关联属性则使用条件因子分解,以此在准确率和时延之间找到一个最佳平衡。
本文提出的 FSPN 模型全称是 Factorize - Split - Sum - Product Network,是一个基于 SPN 树构建的模型。本文的核心创新点在于使用 factorize 节点对强/弱相关的属性集分别建模,同时使用 split 节点对强相关属性集内部进行建模。
整个模型分为三个部分:离线训练,在线分析,增量更新。从抽象的层级来看,功能如下:
-
离线训练接受输入表及其数据,输出模型 f。
-
在线分析模块接受外部的查询 Q,该查询作用在 T 表上。调用模型 f,求得概率之后再乘以原表的基数作为近似的基数估计。
构建FSPN树
本文先以一张单表 T 的 FSPN 模型构建过程为例子。属性集记作 A={A1, A2, A3, A4},将每个属性视作是 r.v.,则表 T 的基数估计问题可转化为求多元概率密度模型 p.d.f. P(A) 的问题。这里令 A3, A4 是两个强相关属性,而 A1, A2 则是弱相关属性,则属性集 A 可被划分为弱相关属性集 W={A1, A2},强相关属性集 H={A3, A4}。

图 1 通过 factorize 区分强弱关联属性集
首先,将表 T 视作是根节点 N1,它将作为 factorize 节点:根据 H 和W 两个属性集将表 T 垂直划分出了两个子表并建立子节点 N2,N3。
进一步划分 N2 节点:A1 和 A2 属性互为弱相关,但非完全独立。对于 SPN 及衍生的模型 [6] 而言,可以通过合适的聚簇 — 分片方式消弭弱相关关系,使得属性之间局部独立,这个过程被称之为 “上下文独立” ( context independent )。
比如,以 A2<50 作为分片条件,将 N2 节点的子表再次划分为 T1,T2。在每个 Ti 内部,A1和 A2 被认为局部独立。对 Ti 继续做垂直分片,可以划分 L1, L2, L3, L4 四个区域,如图 2 所示:
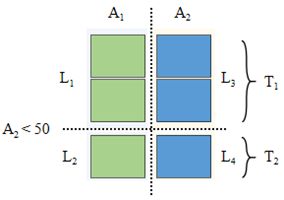
图 2 通过聚簇对子表进行分片
每一个 Li 只包含一个属性列,因此被称之为 uni-leaf 节点。可得:

公式 1 A1,A2 列计算公式
其中,每个权值 w 为子表行数和原表 T 的比值。从公式中可知 N2是 sum 节点。
对于 N3 节点,需要计算 P(A3, A4|A1,A2),即 P(H|W)。本文提出根据 W 对 H 进行划分,假定划分出了子集 H1, H2, …,在同一个 Hi 内部,无需考虑 W 的影响,此时可认为 P(Hi|W) = P(Hi) 。本文称这种方式为上下文条件移除 contextual condition removal。此时将 N3 记作 split 节点。
在当前的例子中,A3, A4 通过谓词 A1 < 0.9 划分出了两个子表 L5 和 L6,并由此产生了两个新的包含多个属性列的叶子节点,被称之 multi-leaf 节点。
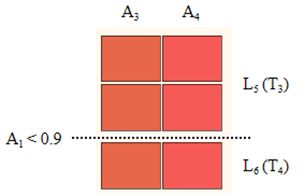
图 3 通过 split 分类强相关属性集数据
以上是完整的 FSPN 树构建过程,如图 4 ( 原文 Figure 1 ) 所示:
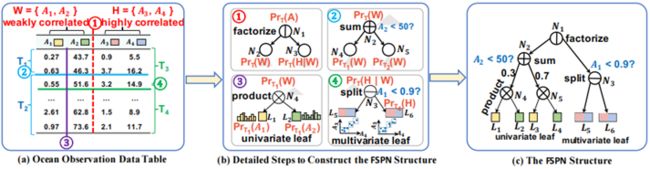
图 4 建立 FSPN 模型的完整过程
处理外部查询
得到的模型 F可以处理来自外界的查询 Q。这里考虑的是范围查询,对于涉及到的属性 Ai,假设它的域为 [Li,Ui],则 Q 可表示为:
![]()
公式 2 hyper-rectangle range
假设每个属性 Ai 的域是 [LBi,UBi],则 LBi ≤ Li ≤ Ui ≤ UBi。特殊地,对于等值查询,认为 Li=Ui。现有一个到达的 Q 如下图 5 ( 见原文 Figure 2 ) 所示:

图 5 使用模型处理查询 Q
按照模型,将 Q 划分出两个等价子查询 Q1 和 Q2。两个子查询可以视作和事件。其中,子查询 Q1 可以通过模型的 N2 节点子树以及 N3 节点的 L5 multi-leaf 节点计算,子查询 Q2 可以通过模型的 N2 节点子树以及 N3 节点的 L6 multi-leaf 节点计算,展开可得:

公式 3 将查询 Q 分解为 Q1 和 Q2
模型更新
当新的数据 ΔT 到达时,FLAT 可以自上而下地实时更新表 T 对应的 FSPN 模型。模型的不同节点将有不同的行为:
-
factorize: 将 ΔT 向下广播到各个节点;
-
sum: 将 ΔT 的每一条数据分发到相应的分片内;
-
split: 类似 sum 节点;
-
uni-leaf: 在该叶子节点中,仅需要简单更新模型参数即可。可选用的方法有 1-D Histogram[7],高斯混合模型等;
-
product: 在更新模型后,检查左右两部分的独立性是否被破坏。若否,则仅简单更新模型;否则,对该节点重新进行建模。
-
multi-leaf: 在更新模型后,需要检查左右两部分的独立性是否被破坏。若否,则仅简单更新模型;否则,将该节点视作 split 节点,重新建模。
离线建模
FSPN 的构造是一个递归的过程。每个节点本质上是四元组 (AN,CN,TN,ON):
-
TN 表示当前节点所包含的数据,它又被称之为节点 N 的上下文;
-
AN ,CN 分别代表该节点的两组属性。如果 CN 为空集,则该节点的建模过程可以用符号标记为 P(AN),反之,则标记为 P(AN|CN)。在 FSPN 模型中,根节点的 AN=A,CN 为空集,TN=T。它代表的联合分布记为 P(A);
-
ON 代表了该节点的性质,即它属于:factorize,sum,split,uni-leaf,product,multi-leaf 节点的其中一个。
本文使用 RDC[8] 方法 ( 全称 Randomized Dependence Coefficient ) 对属性集 A 内的所有属性 Ai, Aj 进行成对检验。这里设定一个阈值 th,若能成功分割出强相关属性集 H ,则该集合并为非空集合。此时,属性集合 A 被划分为 H 和 A - H,并产生左右两个节点。
对于弱相关属性集的节点,特殊地,若 |AN| = 1 ,则该节点被划分为 uni-leaf 节点。uni-leaf 节点的概率模型可以使用简单的方法进行建模,比如 Histogram 方法。
否则,设定阈值 tl 来决定 AN 内部的属性之间是否独立。若是,则该节点可作为 product 节点;否则,将该节点设置为 sum 节点,通过聚簇方式 ( 如 K-means[9] ) 切分多个子表以消除上下文的影响。在每个子表内,认为属性之间是局部独立的,再进而使用 product 节点进行组织。
对于 factorize 节点划分出的右子节点,它的概率模型记作 P(AN|CN),CN 为空集。若 AN 和 CN 集合相互独立,可被直接认为是 multi-leaf 节点,通过建立分段模型 piecewise regression 得到 P(AN)。
否则,使用 d-way 分区方法对 TN 做一步 split ,目前的节点即为 split 节点。假定分出了子簇 T1, T2, …,Td,随后通过 FLAT-Offline 模型对每一簇进行建模得到概率密度。
多表基数估计
首先是离线构建过程。将 D 内所有的表根据它们的连接关系组织成一个树形结构,记作 J。J 内部的每一个节点代表一张表,每一条边表示两个表的连接关系。
本文提出,高度相关的表能够划分到一个组 group 内,而组间的表是弱相关的。以一条边 (A,B) 为例子,系统首先从 A ⟗ B 表中做取样,并检测两表之间是否存在高度相关的属性列。如果部分列之间的相关性高于某个阈值,则直接对 A ⟗ B 表进行建模,或者称将 {A,B} merge 为一个节点。
整个 merge 的过程将递归执行,直到没有再需要 merge 的节点为止。每一个节点 Ti 将表示单表,或者多表的全外连接。
其次是在线构建过程。令 E={T1, T2,…,Td} 表示某一个查询 Q 所命中的 J 树的所有节点。Q 将根据 E 切分出对应的子查询 Q_i。在本文的假设当中,每个 Qi 在 A_1 ⟗ A_2 ⟗ … ⟗A_d 都是独立的,这意味着只需简单计算并累乘子查询的概率即可得到 P(Q)。
多表查询对基数估计的影响
现假定有一个 J 的结构如下,A, B 表被划分为同一个组:
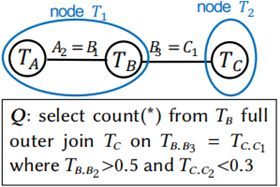
图 6 多表下的连接树构建
当存在一个 Q 的谓词仅与表 A 相关时,直接从T1节点的连接表 ( 即 A ⟗ B ) 进行查找。需要注意的是,在全外连接的过程中,由于 A 表的记录可能会和 B 表发生一对多连接,从而产生更多的数据行,因此基于连接表计算的基数被高估了。为了抵消这种影响,需要对估计到的基数进行下调 ( scale-down ) 修正。

图 7 多表下的基数估计误差
另一个例子则是:查询 Q 和表 B 和 C 相关,但两表并不在一个分组内,因此不能面向 B ⟗ C 表进行基数估计。实际上,这会导致估计到的基数偏小,此时需要进行上调 ( scale-up ) 修正。
为了给基数修正留下足够的线索,本文提出:在原表中新增名为 scattering coefficient 的额外属性列信息。
添加两个额外的列:S_{A,B} 和 S_{B,A}。其中,S_{A,B} 属性列表示:对于 A 表的每一条记录,B 表可提供多少可供连接的行数,反之亦然。这两个属性列用于修正因连接非相关表而需要下调基数估计的情况。此外,本例还需新增一列 S_{T1,{T1,T2}},以应对 C 表与 A ⟗ B进行连接的情况,以便进行基数上调。
表里的每一条数据可能同时需要进行上调 (记作 e ) 和下调 (记作 s ),则它满足查询 Q 查询的概率被系数 e/s 修正。本文默认设定 e 和 s 的最小值为 1 而非 0,原因是每条数据一定会在全外连接的表中出现至少一次,完整计算过程,见[10]。
简而言之,scattering coefficient 列的数量和 D 中的表数目成线性关系。对于连接树 J 的任意一个节点 Ti ,其 scattering coefficient 列的各种信息将在构建 FSPN 模型时一同计算,见[11]。
多表模型的更新
当节点 Ti 中的任意一张子表有新数据到达时,会导致连接表更新数据。下面是一个简单的示例:

图 8 T1 节点的表结构
当 B 表有新数据 ΔB 到达时,它可以与原表 A 产生新的连接关系,将这部分新增数据记作:ΔF+;而表内原有的数据也需要进行检查:有部分数据的 scattering coefficient 列需要进行更新,记作 ΔF*。同时,原本没有连接关系的行可能已经失效,需要被及时删除,记作 ΔF-。如下图所示:
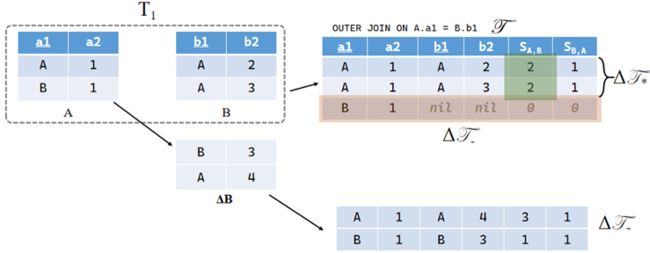
图 9 新增数据导致节点更新
为了加速多表模型的更新过程,将连接表的所有 scattering coefficient 列记作 St,将所有属性列记作 At,则概率模型 P(St|At) 可以被视为 split 节点,左右节点分别为 P(At) 和 P(St|At)。对于左节点,可以直接将增量数据传播到 FSPN 模型,而 St 列的更新则是耗时操作,本文则选择通过异步方式进行更新,以此提高模型效率。
性能对比
本文对已有的其它方法进行对比:Histogram,Naru,NeoroCard,BN,DeepDB,SPN-Multi,MaxDiff,Sample,KDE,MSCN。FSPN 的 RDC 阈值设定为 tl=0.3 ( 低于此值认为独立 ),th=0.7 ( 低于此值认为弱相关 )。性能的评测指标选择广泛使用的 q-error。计算方式为:

公式 4 q-error 计算公式
本文的算法基于 python 实现,实验环境为 CentOS 系统,64 核 Intel Xeon Platinum 8163 2.50 GHz,128 Gb DDR4 内存,以及 1 Tb SSD。
▋ 单表性能比较
本文使用 GAS 和 DMV 两个现实的数据集进行性能评测。GAS 包含了 3,843,159 条数据,而 DMV 包含了 11,591,877 条数据。
GAS 数据源:
https://archive.ics.uci.edu/ml/datasets/Gas+sensor+array+temperature+modulation
DM数据源:
https://catalog.data.gov/dataset/vehicle-snowmobile-and-boat-registrations
对于每一个数据集,本文随机生成了 1 万条查询,每个属性列被选择的概率均为 0.5。表 1 ( 对应原文 Table 1) 展示了不同算法的 q-error 分布。

表 1 各模型在单表下的基数估计性能
总而言之,从准确率的角度分析,排名依次为:FLAT≈Naru[12]≈ SPN-Multi >BN>DeepDB>>Sample/MSCN[13]>>KDE[14]>> MaxDiff/Histogram。细节如下:
Naru 的高准确率源于它基于 AR 的分解方法,以及庞大的 DNN 网络。
SPN-Multi 同样达到了一个高准确率,因为它抛弃了属性之间完全独立的假设。
BN 和 DeepDB 的准确率逊色于 FLAT。BN 的性能受到了其结构的制约,而 DeepDB 似乎并不能很好地处理高度关联的数据集。
MSCN 和 Sample 的表现并不稳定。考虑到 MSCN 是一个 query-driven 的模型,它的表现取决于查询负载和训练的查询样本是否足够相似。
FLAT 的性能远超 Histogram,MaxDiff 和 KDE:Histogram 和 MaxDiff 仅做了粗粒度的独立性假设;KDE 则无法有效地用核方法处理高维度数据 ( high-dimensional data )。
下方的图表展示了不同方法的平均延迟时间,为了公平起见,这里仅比较了基于 CPU 的方法。排名依次为:Histogram ≈ FLAT > MSCN > SPN-Multi/DeepDB > KDE/Sample >> 其它。

图 10 各模型的训练时延
FLAT 在两个数据集的估计延时分别为 0.1ms 和 0.5ms,远超其它的方法。这证明了 FSPN 是高性能的模型。除此之外,MSCN 在这里仅需要对 DNN 做一次前向传播,因此也取得了不错的成绩。
DeepDB,SPN-Multi,KDE 和 Sample 需要 10ms 去处理每一条查询。DeepDB 和 SPN-Multi 同样是基于 SPN 的模型,而它们在本次测试中均构建出了约 800+ 个节点的树结构。而 FSPN 使用了更加轻量,紧凑的模型,相比之下只构建了 200 个节点。额外的,KDE 和 Sample 需要大量的样本进行检测,这有损了它们的性能。
表 1 还反应出 FSPN 模型的训练时间要比其它模型更小。这得益于 FSPN 的模型,同时又不需要像基于 SGD 的 DNN 训练那样需要迭代式的梯度更新。
▋ 多表性能比较
本文使用经典的 IMDB 数据集测试多表查询的场景。同时,创建了包含了 70 个简单查询的轻量级 JOB-light,以及包含 1500 个复杂查询的 JOB-weight。表 2 ( 对应原文 Table 2 ) 展示了各个估计模型在 JOB-light 查询集的表现情况。

表 2 各模型在 Job-light 下的性能
FLAT 在准确率方面仍有显著优势。从存储方面,FLAT 仅仅位列 Histogram 和 BN 之后。但相较于单表情形,FSPN 模型变得十分庞大 —— 因为在多表情况下要构建 scattering coefficient 列并维护。
在 JOB-ours 查询集下,其它方法的性能发生了显著下降,但是 FLAT 仍然能够保持相对最佳的性能。图 10 ( 对应原文 Figure 7 ) 表明了 FSPN 模型在两种工作负载下的查询延迟均在 5ms 左右,仅稍次于 Histogram 方法。
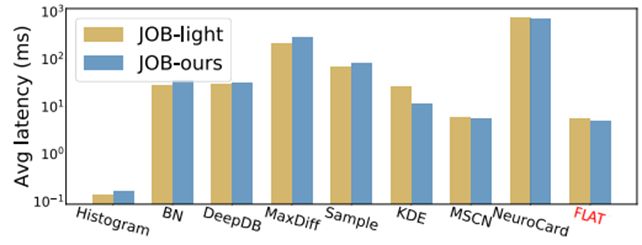
图 11 多模型在不同测试集的平均延迟
▋ 更新性能
本文提取了 IMDB 前 80% 的数据用于训练模型,并用剩下 20% 的数据用于测试数据更新的场景。如表 3 ( 对应原文 Table 4 ) 展示:

表 3 增删数据对各模型的性能影响
再训练模型 ( retrained model ) 的准确率最高,而代价是最长的训练时间。由于增量数据导致概率密度发生变化,那些不支持更新模型的方法的准确率在当前场景下是最低的。相比较而言,本文的 FSPN 模型在准确率和更新时延之间保持了良好的平衡。
写在最后
本文提出了一个基于 SPN 的改进模型 —— FSPN,一个轻量且高效的无监督图模型。它最大的亮点在于可以灵活根据属性列之间不同的依赖程度 ( 独立,弱相关,强相关 ),综合利用独立因子分解和条件因子分解的思路进行建模,同时保证了系统的准确性和时效性。
不同场景下的对比实验均验证了 FSPN 模型的高效性和稳定性,相信该模型在未来能够在数据库相关的工作中充当更加重要的角色。
*参考文献:
[1] Shohedul Hasan, Saravanan Thirumuruganathan, Jees Augustine, Nick Koudas,and Gautam Das. 2019. Multi-attribute selectivity estimation using deep learning.In SIGMOD.
[2] Zongheng Yang, Amog Kamsetty, Sifei Luan, Eric Liang, Yan Duan, Xi Chen, and Ion Stoica. 2021. NeuroCard: One Cardinality Estimator for All Tables. PVLDB 14, 1 (2021), 61–73.
[3] Zongheng Yang, Eric Liang, Amog Kamsetty, Chenggang Wu, Yan Duan, Xi Chen, Pieter Abbeel, Joseph M Hellerstein, Sanjay Krishnan, and Ion Stoica. 2019. Deep unsupervised cardinality estimation. PVLDB (2019).
[4] Lise Getoor, Benjamin Taskar, and Daphne Koller. 2001. Selectivity estimation using probabilistic models. In SIGMOD. 461–472.
[5] Kostas Tzoumas, Amol Deshpande, and Christian S Jensen. 2011. Lightweight graphical models for selectivity estimation without independence assumptions. PVLDB 4, 11 (2011), 852–863.
[6] Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kristian Kersting, and Carsten Binnig. 2019. DeepDB: learn from data, not from queries!. In PVLDB.
[7] P Griffiths Selinger, Morton M Astrahan, Donald D Chamberlin, Raymond A Lorie, and Thomas G Price. 1979. Access path selection in a relational database management system. In SIGMOD. 23–34.
[8] David Lopez-Paz, Philipp Hennig, and Bernhard Schölkopf. 2013. The randomized dependence coefficient. In NIPS. 1–9.
[9] K Krishna and M Narasimha Murty. 1999. Genetic K-means algorithm. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 29, 3 (1999),433–439.
[10] Rong Zhu, Ziniu Wu, Yuxing Han, Kai Zeng, Andreas Pfadler, Zhengping Qian, Jingren Zhou, and Bin Cui. 2020. FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation [Technical Report]. arXiv preprint arXiv:2011.09022 (2020).
[11] Zhuoyue Zhao, Robert Christensen, Feifei Li, Xiao Hu, and Ke Yi. 2018. Random sampling over joins revisited. In SIGMOD. 1525–1539.
[12] Zongheng Yang and Chenggang Wu. 2019. Github repository: naru project.https://github.com/naru-project/naru (2019).
[13] Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2019. Learned cardinalities: Estimating correlated joins with deep learning. In CIDR.
[14] Luch Liu. 2020. Github repository: scikit-learn. https://github.com/scikit learn/scikit-learn (2020).