TSM: Temporal Shift Module for Efficient Video Understanding
接着之前的《浅谈动作识别TSN,TRN,ECO》,来谈谈最近 MIT和IBM Watson 的新文 Temporal Shift Module(TSM)[1]。

Something-SomethingV1 数据集上的个算法性能对比
看看上图,文章的主要贡献一目了然:
- 对比主流的轻量级在线视频理解ECO系列, TSM系列在参数量少三倍的情况下,性能仍然超越ECO系列
- 另外文章的TSM模块的实现非常简洁而且硬件友好:通过在2D CNN中位移 temporal 维度上的 channels,来实现时间上的信息交互。故不需要添加任何额外参数,且能捕捉Long-term 时空上下文关系。
--------------------------------------------------------
Related Work:
大概过一下之前的几个重要工作(也是本文性能对比的主要几个state-of-the-art):
- TSN[2]:视频动作/行为识别的基本框架,将视频帧下采样(分成K个Segment,各取一帧)后接2D CNN对各帧进行处理+fusion
- TRN[3]:对视频下采样出来的 frames 的deep feature,使用 MLP 来融合,建立帧间temporal context 联系。最后将多级(不同采样率)出来的结果进行再一步融合,更好表征short-term 和 long-term 关系。
- ECO[4]系列:
ECO-Lite:轻量级网络,使用 TSN的中间层 feature maps,来组成 feature clips,然后使用3D CNN来融合时空特征。
ECOen-Lite:在ECO-Lite基础上,concat上帧间fusion后的 TSN 特征,再做决策。
4. NL I3D+GCN[5]:还没来得及看~~
@Xiaolong Wang
大佬ECCV2018的工作,大佬可以讲解下?使用 non-local I3D来捕获long-range时空特征,使用 space-time region graphs 来获取物体区域间的关联及时空变化。
故上述性能特别高的 ECO系列 和 NL I3D+GCN,都是或多或少都是使用了3D卷积或者伪3D卷积运算,故在大规模在线视频理解上用,运算量和效率还是有一定瓶颈。
-----------------------------------------------------------
算法框架:
启发:
为了解决上述的3D卷积运算量问题,作者提出了可嵌入到2D CNN中的 TSM 模块。作者发现:一般的卷积操作,可以分解成 位移shift + 权值叠加 multiply-accumulate 两个过程。
比如说对一个1D vector X 进行 kernel size=3 的卷积操作 Y = Conv(W; X) 可以写成:
![]()
故分解后的两个操作分别为:
- 位移(基本不消耗计算资源,常规地址偏移指针操作)
![]()
2. 权值叠加
![]()
故作者认为,设计TSM模块时候,尽可能多使用位移操作(几乎0计算量),把权值叠加操作放到2D CNN本身的卷积里去做,这样就可在不加任何参数计算量基础上,实现更多功能。
TSM模块:
那么问题来了,怎么在时空建模的视频理解任务里,用好这个位移操作呢?

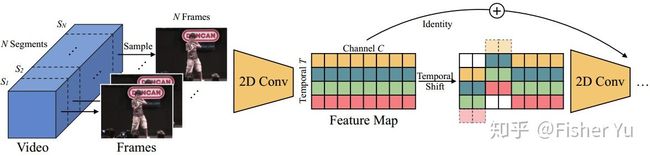
Temporal shift module
上图中最左边的二维矩阵是 Ti 时刻 tensor中 temporal和 channel维度(不需要考虑 batch 和 spatial 维度先); 中间是通过STM模块位移后的的矩阵,可见前两个channel向前位移一步来表征 Ti-1 的 feature maps,而第三、四个channel 则向后位移一步来表征 Ti+1 ,最后位移后的空缺 padding补零;右边的与中间的类似,不过是 circulant 方式来 padding,后面实验会对比两种不同padding方式的性能差异。
这里就涉及一个超参:究竟多少比例的channel进行 temporal shift 才比较合适呢?
作者也考虑到了这个问题,因为如果太多channel进行时间位移,那么原始固定时刻帧的 2D CNN空间特征就会受到损害,但如果太少channel进行时间位移,那么网络又会因temporal上下文交互太少而学不到准确的temporal representation。
为了解决这个问题,作者提出了残差TSM,这样就可以整合位移前后的特征。

原地TSM与残差TSM
最后我们来看看用作动作/行为识别的整个框架:
TSM整体框架
文中使用的backbone是ResNet-50,且在每个 residual unit 后都会加入 残差TSM 模块,当用2D 3x3的卷积时,每次插入TSM模块后的时间感受野都会扩大2,故整个框架最后的时间感受野会很大,足以进行复杂的时空建模。
----------------------------------------------------------------
实验结果:
- 首先在经典的动作/行为识别数据集上,与纯2D CNN框架的 TSN baseline 进行对比。由于两者都使用相同的backbone网络和下采样方式,故唯一的不同就是有无加 TSM 模块。从表中可见,加入TSM后,特别在 复杂行为 Something-Something 集上性能有极大的提升。

TSM与TSN性能对比
2. 下图是与 TSN, ECO, NL I3D+GCN 系列的性能综合对比,可见TSM即使在输入只有 8 frames的情况下,用最少的参数和浮点运算次数,来取得最高的识别性能,确实BT~~

Something-Something集上 识别性能与速度性能对比
3. 从下面两图可见,使用了Residual shift后,网络变得更加稳定,对 shifted channel数比例的依赖更小。而 zero padding 的性能明显比 环形 padding 要好,因为后者的话会把 temporal 的顺序打乱,导致学出来的时间特征变混乱。

残差/原地TSM及channel shift比例的超参实验

不同Padding方式的性能对比
-------------------------------------------------------------
总结及展望:
文章 first 提出了 temporal shift 这个视角(感觉像是搞硬件底层或芯片的人来跨界融合搞算法一样~~),通过人为地调度 temporal channel 的顺序让网络学到其交互的时空特征,非常地高效实用。
未来的可能性能否探索3D卷积与channel shift之间的新可能性?Temporal 维度multi-scale shifted 是否更有效?channel shift 的思想能否进一步放在其他复杂任务里,比如4D的任务?
Reference:
[1]Ji Lin, Temporal Shift Module for Efficient Video Understanding
[2] Limin Wang, Temporal Segment Networks: Towards Good Practices for Deep Action Recognition, ECCV2016
[3]Bolei Zhou, Temporal Relational Reasoning in Videos,ECCV2018
[4]Mohammadreza Zolfaghari, ECO: Efficient Convolutional Network for Online Video Understanding,ECCV2018
[5] Xiaolong Wang, Videos as Space-Time Region Graphs, ECCV2018