理解对比表示学习(Contrastive Learning)
目录
- 一、前言
- 二、对比学习
- 三、主要论文(附代码分析)
-
- 1. AMDIM ([Bachman](https://arxiv.org/pdf/1906.00910.pdf) *et al.* 2019)
- 2. SIMCLR ([Geoffrey Hinton](https://arxiv.org/pdf/2002.05709.pdf) *et al* 2020)
- 3.MOCO ([Kaiming He](https://ieeexplore.ieee.org/document/9157636) *et al.* 2020)
- 四、总结
一、前言
监督学习近些年获得了巨大的成功,但是有如下的缺点:
- 人工标签相对数据来说本身是稀疏的,蕴含的信息不如数据内容丰富;
- 监督学习只能学到特定任务的知识,不是通用知识,一般难以直接迁移到其他任务中。
由于这些原因,自监督学习的发展被给予厚望。监督学习,无监督学习和自监督学习的区别
如果说自监督学习是蛋糕,那么监督学习就是蛋糕上的小冰块,强化学习就是蛋糕上点缀的樱桃。(“self-supervised learning is the cake, supervised learning is the icing on the cake, reinforcement learning is the cherry on the cake”) —Yann LeCun
自监督学习不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,学习样本数据的特征表达,应用于下游的任务。自监督学习又可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。对比学习的核心思想是讲正样本和负样本在特征空间对比,学习样本的特征表示,难点在于如何构造正负样本。
最近,诸如BERT和T5之类的自然语言处理模型已经表明,可以通过首先在一个大型的未标记数据集上进行预训练,然后在一个较小的标记数据集上进行微调,从而用很少的类标签来获得良好的结果。 同样,对未标记的大型图像数据集进行预训练,有可能提高计算机视觉任务的性能。这点已经在对比表示学习的相关论文,例如Exemplar-CNN, Instance Discrimination, CPC, AMDIM, CMC, MoCo,获得了证实。对比学习训练得到的神经网络模型,可以被用作下游的任务,例如分类、分割、检测等。经过对比学习预训练得到的神经网络,已经具有很强的表达能力,一般只需要再用很少的有标签数据微调,就可以获得非常优秀的性能。
以下图片引用

二、对比学习
对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。简单地说,对比表示学习可以被认为是通过比较学习。相对来说,生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。在对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。可以在“相似”输入的正对和“不同”输入的负对之间进行比较。以下图片引用。
对比学习通过同时最大化同一图像的不同变换视图(例如剪裁,翻转,颜色变换等)之间的一致性,以及最小化不同图像的变换视图之间的一致性来学习的。 简单来说,就是对比学习要做到相同的图像经过各类变换之后,依然能识别出是同一张图像,所以要最大化各类变换后图像的相似度(因为都是同一个图像得到的)。相反,如果是不同的图像(即使经过各种变换可能看起来会很类似),就要最小化它们之间的相似度。通过这样的对比训练,编码器(encoder)能学习到图像的更高层次的通用特征 (image-level representations),而不是图像级别的生成模型(pixel-level generation)。
Pixel-level generation is computationally expensive and may not be necessary for representation learning. —SimCLR论文
三、主要论文(附代码分析)
1. AMDIM (Bachman et al. 2019)
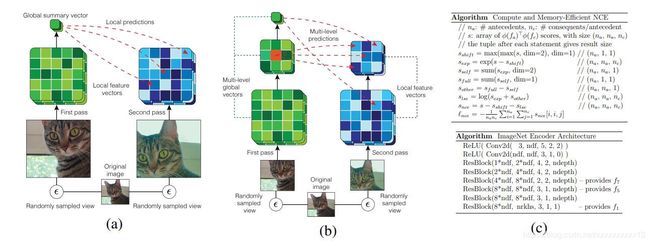
本文的基本想法是最大化同一个图像不同视角之间的互信息 (mutual information),也就是题目所说的“通过最大化不同视角之间的互信息进行表示学习” (Learning Representations by Maximizing Mutual Information Across Views)。这个想法和人类观察世界的的方式有类似之处,例如,我们观察同一个物体的时候,通常可以通过从不同的位置(例如,场景中的摄像机位置)以及通过不同的方式(例如,触觉,听觉或视觉)进行观察,可以产生局部时空视图。这样不同视角的观察图像,可以用数据增强 (data augmentation) 的方式生成。最大化从这些视图提取的特征之间的互信息,要求捕捉到更高层次的图像因素,例如某些物体或者事件是否出现或者发生。
下图(b)就是本文的Augmented Multiscale Deep InfoMax (AMDIM)结构。
Encoder部分的核心代码如下:
class Encoder(nn.Module):
def __init__(self, dummy_batch, num_channels=3, ndf=64, n_rkhs=512,
n_depth=3, encoder_size=32, use_bn=False):
super(Encoder, self).__init__()
self.ndf = ndf
self.n_rkhs = n_rkhs
self.use_bn = use_bn
self.dim2layer = None
# encoding block for local features
print('Using a {}x{} encoder'.format(encoder_size, encoder_size))
if encoder_size == 32:
self.layer_list = nn.ModuleList([
Conv3x3(num_channels, ndf, 3, 1, 0, False),
ConvResNxN(ndf, ndf, 1, 1, 0, use_bn),
ConvResBlock(ndf * 1, ndf * 2, 4, 2, 0, n_depth, use_bn),
ConvResBlock(ndf * 2, ndf * 4, 2, 2, 0, n_depth, use_bn),
MaybeBatchNorm2d(ndf * 4, True, use_bn),
ConvResBlock(ndf * 4, ndf * 4, 3, 1, 0, n_depth, use_bn),
ConvResBlock(ndf * 4, ndf * 4, 3, 1, 0, n_depth, use_bn),
ConvResNxN(ndf * 4, n_rkhs, 3, 1, 0, use_bn),
MaybeBatchNorm2d(n_rkhs, True, True)
])
elif encoder_size == 64:
self.layer_list = nn.ModuleList([
Conv3x3(num_channels, ndf, 3, 1, 0, False),
ConvResBlock(ndf * 1, ndf * 2, 4, 2, 0, n_depth, use_bn),
ConvResBlock(ndf * 2, ndf * 4, 4, 2, 0, n_depth, use_bn),
ConvResBlock(ndf * 4, ndf * 8, 2, 2, 0, n_depth, use_bn),
MaybeBatchNorm2d(ndf * 8, True, use_bn),
ConvResBlock(ndf * 8, ndf * 8, 3, 1, 0, n_depth, use_bn),
ConvResBlock(ndf * 8, ndf * 8, 3, 1, 0, n_depth, use_bn),
ConvResNxN(ndf * 8, n_rkhs, 3, 1, 0, use_bn),
MaybeBatchNorm2d(n_rkhs, True, True)
])
elif encoder_size == 128:
self.layer_list = nn.ModuleList([
Conv3x3(num_channels, ndf, 5, 2, 2, False, pad_mode='reflect'),
Conv3x3(ndf, ndf, 3, 1, 0, False),
ConvResBlock(ndf * 1, ndf * 2, 4, 2, 0, n_depth, use_bn),
ConvResBlock(ndf * 2, ndf * 4, 4, 2, 0, n_depth, use_bn),
ConvResBlock(ndf * 4, ndf * 8, 2, 2, 0, n_depth, use_bn),
MaybeBatchNorm2d(ndf * 8, True, use_bn),
ConvResBlock(ndf * 8, ndf * 8, 3, 1, 0, n_depth, use_bn),
ConvResBlock(ndf * 8, ndf * 8, 3, 1, 0, n_depth, use_bn),
ConvResNxN(ndf * 8, n_rkhs, 3, 1, 0, use_bn),
MaybeBatchNorm2d(n_rkhs, True, True)
])
else:
raise RuntimeError("Could not build encoder."
"Encoder size {} is not supported".format(encoder_size))
self._config_modules(dummy_batch, [1, 5, 7], n_rkhs, use_bn)
def init_weights(self, init_scale=1.):
'''
Run custom weight init for modules...
'''
for layer in self.layer_list:
if isinstance(layer, (ConvResNxN, ConvResBlock)):
layer.init_weights(init_scale)
for layer in self.modules():
if isinstance(layer, (ConvResNxN, ConvResBlock)):
layer.init_weights(init_scale)
if isinstance(layer, FakeRKHSConvNet):
layer.init_weights(init_scale)
def _config_modules(self, x, rkhs_layers, n_rkhs, use_bn):
'''
Configure the modules for extracting fake rkhs embeddings for infomax.
'''
enc_acts = self._forward_acts(x)
self.dim2layer = {}
for i, h_i in enumerate(enc_acts):
for d in rkhs_layers:
if h_i.size(2) == d:
self.dim2layer[d] = i
# get activations and feature sizes at different layers
self.ndf_1 = enc_acts[self.dim2layer[1]].size(1)
self.ndf_5 = enc_acts[self.dim2layer[5]].size(1)
self.ndf_7 = enc_acts[self.dim2layer[7]].size(1)
# configure modules for fake rkhs embeddings
self.rkhs_block_1 = NopNet()
self.rkhs_block_5 = FakeRKHSConvNet(self.ndf_5, n_rkhs, use_bn)
self.rkhs_block_7 = FakeRKHSConvNet(self.ndf_7, n_rkhs, use_bn)
def _forward_acts(self, x):
'''
Return activations from all layers.
'''
# run forward pass through all layers
layer_acts = [x]
for _, layer in enumerate(self.layer_list):
layer_in = layer_acts[-1]
layer_out = layer(layer_in)
layer_acts.append(layer_out)
# remove input from the returned list of activations
return_acts = layer_acts[1:]
return return_acts
def forward(self, x):
'''
Compute activations and Fake RKHS embeddings for the batch.
'''
if has_many_gpus():
if x.abs().mean() < 1e-4:
r1 = torch.zeros((1, self.n_rkhs, 1, 1),
device=x.device, dtype=x.dtype).detach()
r5 = torch.zeros((1, self.n_rkhs, 5, 5),
device=x.device, dtype=x.dtype).detach()
r7 = torch.zeros((1, self.n_rkhs, 7, 7),
device=x.device, dtype=x.dtype).detach()
return r1, r5, r7
# compute activations in all layers for x
acts = self._forward_acts(x)
# gather rkhs embeddings from certain layers
r1 = self.rkhs_block_1(acts[self.dim2layer[1]])
r5 = self.rkhs_block_5(acts[self.dim2layer[5]])
r7 = self.rkhs_block_7(acts[self.dim2layer[7]])
return r1, r5, r7
2. SIMCLR (Geoffrey Hinton et al 2020)
SIMCLR提出了一种构建负样本的方式,基本思想是:输入一幅图像,对其进行随机变换(Data Augmentation)得到两幅图像 x i x_i xi 和 x j x_j xj,分别通过编码器得到相应的 h i h_i hi 和 h j h_j hj,然后,采用非线性全连接层以获得表示 z i z_i zi和 z j z_j zj。学习的任务就是对于同一张图片,最大化这两种表示 z i z_i zi 和 z j z_j zj之间的相似性。网络学习完成之后, h i h_i hi, h j h_j hj就可以作为图像的一种特征表示,用作下游的学习任务(Downstream tasks)。
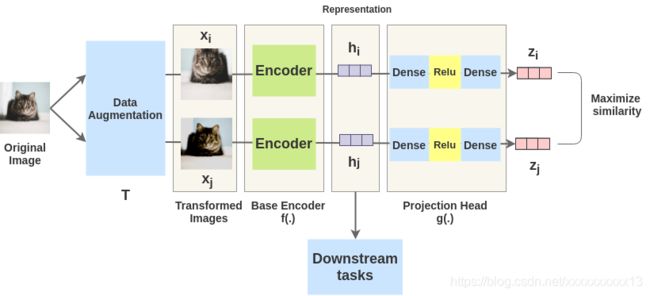
第一步,数据增强,包括 random cropping(剪裁), random color distortions (颜色变换), and random Gaussian blur (高斯模糊)等。虽然可以采用更为复杂的数据增强方式,例如AutoAugment,但是作者认为,这些简单的变换已经足以让神经网络学习到足够丰富的表达。

核心代码如下:
from PIL import Image
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
第二步,由基编码器 f ( ⋅ ) f(\cdot) f(⋅)得到表示 h i h_i hi, h j h_j hj。文章中作者使用ResNet-50作为卷积神经网络编码器。输出向量 h i h_i hi的维度是2048.
第三步,投影端(projection head) g ( ⋅ ) g(\cdot) g(⋅),主要由全连接层和激活层ReLU组成,将表示 h i h_i hi和 h j h_j hj进一步非线性映射为 z i z_i zi, z j z_j zj。作者说,非线性投影端很重要,一方面可以将映射后的表达 z i z_i zi用来计算相似度,另一方面,可以让投影端之前的表达 h i h_i hi保留更多图像信息。
核心代码如下,包含基编码器 f ( ⋅ ) f(\cdot) f(⋅)和投影端 g ( ⋅ ) g(\cdot) g(⋅):
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50
class Model(nn.Module):
def __init__(self, feature_dim=128):
super(Model, self).__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)
# projection head
self.g = nn.Sequential(nn.Linear(2048, 512, bias=False), nn.BatchNorm1d(512),
nn.ReLU(inplace=True), nn.Linear(512, feature_dim, bias=True))
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
out = self.g(feature)
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
第四步,训练网络,计算图像之间的相似度,再以此计算网络的交叉熵损失。
相似度:为了比较投影端产生的表示,使用余弦相似度,其定义为:
sim ( u , v ) = u T v ∥ u ∥ ∥ v ∥ (1) \operatorname{sim}(u, v)=\frac{u^{T} v}{\|u\|\|v\|} \tag{1} sim(u,v)=∥u∥∥v∥uTv(1)
损失函数:基于相似度,正对示例的损失函数定义为(与MOCO损失函数类似):
ℓ i , j = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( sim ( z i , z k ) / τ ) (2) \ell_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)} \tag{2} ℓi,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)(2)
其中, τ \tau τ被称为temperature parameter。该损失函数又称作normalized temperature-scaled cross-entropy loss。
import torch
from model import Model
# train for one epoch to learn unique features
def train(net, data_loader, train_optimizer):
net.train()
total_loss, total_num, train_bar = 0.0, 0, tqdm(data_loader)
for pos_1, pos_2, target in train_bar:
pos_1, pos_2 = pos_1.cuda(non_blocking=True), pos_2.cuda(non_blocking=True)
feature_1, out_1 = net(pos_1)
feature_2, out_2 = net(pos_2)
# [2*B, D]
out = torch.cat([out_1, out_2], dim=0)
# [2*B, 2*B]
sim_matrix = torch.exp(torch.mm(out, out.t().contiguous()) / temperature)
mask = (torch.ones_like(sim_matrix) - torch.eye(2 * batch_size, device=sim_matrix.device)).bool()
# [2*B, 2*B-1]
sim_matrix = sim_matrix.masked_select(mask).view(2 * batch_size, -1)
# compute loss
pos_sim = torch.exp(torch.sum(out_1 * out_2, dim=-1) / temperature)
# [2*B]
pos_sim = torch.cat([pos_sim, pos_sim], dim=0)
loss = (- torch.log(pos_sim / sim_matrix.sum(dim=-1))).mean()
train_optimizer.zero_grad()
loss.backward()
train_optimizer.step()
total_num += batch_size
total_loss += loss.item() * batch_size
train_bar.set_description('Train Epoch: [{}/{}] Loss: {:.4f}'.format(epoch, epochs, total_loss / total_num))
return total_loss / total_num
在对比学习任务中对SimCLR模型进行了训练之后,舍弃投影端 g ( ⋅ ) g(\cdot) g(⋅),使用基编码器(base encoder) f ( ⋅ ) f(\cdot) f(⋅) 获得的图像的表示,将表示向量用于下游任务,例如ImageNet分类。
3.MOCO (Kaiming He et al. 2020)
MOCO的一个核心观点是,样本数量对于对比学习很重要。本文提出一种动量对比 (Mometum contrast) 的方法提高每个mini-batch的负样本数量。具体地说,MOCO通过查询值 q q q 和含有编码键值 { k 0 , k 1 , k 2 , … } \{k_0, k_1, k_2, \dots \} {k0,k1,k2,…}的字典之间的匹配损失,来优化一个编码器。假设字典中存在唯一一个键值 k + k_+ k+ 与 q q q 匹配,那么对比损失函数 L q \mathcal{L}_q Lq 函数值可以取得最小。 L q \mathcal{L}_q Lq表示为:
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 K exp ( q ⋅ k i / τ ) (3) \mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)} \tag{3} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)(3)
本文认为,如果字典足够大,包含的负样本足够丰富 (large) 的话,可以学到更好的特征表达。与此同时,用于字典键值的编码器要在学习进化的过程中尽量保持一致 (consistent)。MOCO有两个核心模块:(1) 用队列实现字典,主要的作用是可以实现字典大小和mini-batch大小的耦合,如此便可不受限制地提高bath size;(2) 动量更新,主要是为了解决引入队列维护字典之后,字典的编码器无法通过梯度反传获得参数更新的问题,具体为:
θ k ← m θ k + ( 1 − m ) θ q (4) \theta_{\mathrm{k}} \leftarrow m \theta_{\mathrm{k}}+(1-m) \theta_{\mathrm{q}} \tag{4} θk←mθk+(1−m)θq(4)
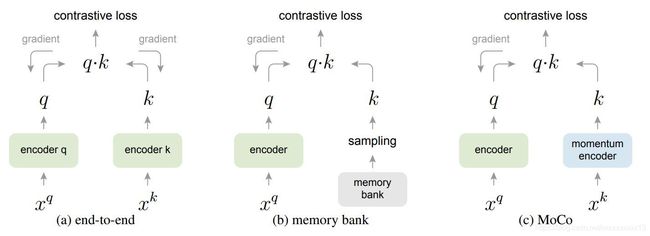
如图©所示,通过这种动量更新的方法,可以从 q q q 的梯度反向传播间接获得 k k k 的梯度。相对于直接用 q q q 的梯度更新替代 k k k 的梯度更新,这种动量更新的方式更加平稳。 m m m 一般取0.99 ,如果取 0.9 0.9 0.9 会太小,实验效果不好 ,这说明 θ q \theta_q θq 和 θ k \theta_k θk 的耦合不宜过强。
下图总结对比了常用的三种负样本管理机制。图(a)是原始的end-to-end结构,最主要的问题是batch size和ditionary size相互耦合,ditionary size因此受限于GPU的内存大小。图(b)通过增加memory bank 结构,改进了图(a)的结构。memory bank可以存储数据集中所有样本的特征表达,每个字典随机地从memory bank中采样。但是从memory bank随机采样的问题是在不同的更新阶段,样本缺乏一致性,这就是MOCO反复强调的consistent问题。
核心代码如下 (pytorch伪代码):
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
# bmm: batch matrix multiplication; mm: matrix multiplication; cat: concatenation.
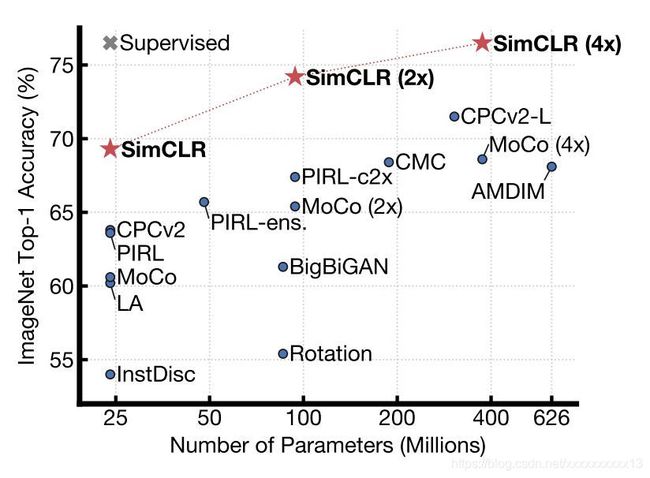
最后,附上一张现有主流对比学习模型的性能图,来自SIMCLR论文。
四、总结
本文介绍了自监督学习中的一种重要方法–对比学习(contrastive learning)的基本概念和三篇代表性的最新论文,并且从模型创新点和代码实现角度进行了分析。对比学习是当前自监督学习一个重要的分支,目的在于从小样本无标签的数据中,学习到更有效的特征表达。目前的研究进展表明,自监督学习正在逐步逼近监督学习的水平。在很多场景中,例如医学影像分析,有标签的数据极其稀有。用自监督学习进行表示学习和预训练,将会是重要的一环。
本博客撰写过程参考了以下博客内容:
- Google AI blog
- SimCLR Post
- 对比学习(Contrastive Learning)相关进展梳理
- 对比学习(Contrastive Learning)
- A Framework For Contrastive Self-Supervised Learning And Designing A New Approach