Pytorch里面的DataLoader的collate_fn参数
DataLoader的collate_fn参数,实现自定义的batch输出。
DataLoader完整的参数表如下:
class torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=<function default_collate>,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None)
collate_fn:如何取样本的,我们可以定义自己的函数来准确地实现想要的功能。
这里我们需要找到DataLoader的源码进行查看这个参数到底是什么。
可以看到collate_fn默认是等于default_collate,那么这个函数的定义如下。
def default_collate(batch):
r"""
Function that takes in a batch of data and puts the elements within the batch
into a tensor with an additional outer dimension - batch size. The exact output type can be
a :class:`torch.Tensor`, a `Sequence` of :class:`torch.Tensor`, a
Collection of :class:`torch.Tensor`, or left unchanged, depending on the input type.
This is used as the default function for collation when
`batch_size` or `batch_sampler` is defined in :class:`~torch.utils.data.DataLoader`.
Here is the general input type (based on the type of the element within the batch) to output type mapping:
* :class:`torch.Tensor` -> :class:`torch.Tensor` (with an added outer dimension batch size)
* NumPy Arrays -> :class:`torch.Tensor`
* `float` -> :class:`torch.Tensor`
* `int` -> :class:`torch.Tensor`
* `str` -> `str` (unchanged)
* `bytes` -> `bytes` (unchanged)
* `Mapping[K, V_i]` -> `Mapping[K, default_collate([V_1, V_2, ...])]`
* `NamedTuple[V1_i, V2_i, ...]` -> `NamedTuple[default_collate([V1_1, V1_2, ...]), default_collate([V2_1, V2_2, ...]), ...]`
* `Sequence[V1_i, V2_i, ...]` -> `Sequence[default_collate([V1_1, V1_2, ...]), default_collate([V2_1, V2_2, ...]), ...]`
Args:
batch: a single batch to be collated
Examples:
>>> # Example with a batch of `int`s:
>>> default_collate([0, 1, 2, 3])
tensor([0, 1, 2, 3])
>>> # Example with a batch of `str`s:
>>> default_collate(['a', 'b', 'c'])
['a', 'b', 'c']
>>> # Example with `Map` inside the batch:
>>> default_collate([{'A': 0, 'B': 1}, {'A': 100, 'B': 100}])
{'A': tensor([ 0, 100]), 'B': tensor([ 1, 100])}
>>> # Example with `NamedTuple` inside the batch:
>>> Point = namedtuple('Point', ['x', 'y'])
>>> default_collate([Point(0, 0), Point(1, 1)])
Point(x=tensor([0, 1]), y=tensor([0, 1]))
>>> # Example with `Tuple` inside the batch:
>>> default_collate([(0, 1), (2, 3)])
[tensor([0, 2]), tensor([1, 3])]
>>> # Example with `List` inside the batch:
>>> default_collate([[0, 1], [2, 3]])
[tensor([0, 2]), tensor([1, 3])]
"""
elem = batch[0]
elem_type = type(elem)
if isinstance(elem, torch.Tensor):
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum(x.numel() for x in batch)
storage = elem.storage()._new_shared(numel)
out = elem.new(storage).resize_(len(batch), *list(elem.size()))
return torch.stack(batch, 0, out=out)
elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
and elem_type.__name__ != 'string_':
if elem_type.__name__ == 'ndarray' or elem_type.__name__ == 'memmap':
# array of string classes and object
if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
raise TypeError(default_collate_err_msg_format.format(elem.dtype))
return default_collate([torch.as_tensor(b) for b in batch])
elif elem.shape == (): # scalars
return torch.as_tensor(batch)
elif isinstance(elem, float):
return torch.tensor(batch, dtype=torch.float64)
elif isinstance(elem, int):
return torch.tensor(batch)
elif isinstance(elem, string_classes):
return batch
elif isinstance(elem, collections.abc.Mapping):
try:
return elem_type({key: default_collate([d[key] for d in batch]) for key in elem})
except TypeError:
# The mapping type may not support `__init__(iterable)`.
return {key: default_collate([d[key] for d in batch]) for key in elem}
elif isinstance(elem, tuple) and hasattr(elem, '_fields'): # namedtuple
return elem_type(*(default_collate(samples) for samples in zip(*batch)))
elif isinstance(elem, collections.abc.Sequence):
# check to make sure that the elements in batch have consistent size
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError('each element in list of batch should be of equal size')
transposed = list(zip(*batch)) # It may be accessed twice, so we use a list.
if isinstance(elem, tuple):
return [default_collate(samples) for samples in transposed] # Backwards compatibility.
else:
try:
return elem_type([default_collate(samples) for samples in transposed])
except TypeError:
# The sequence type may not support `__init__(iterable)` (e.g., `range`).
return [default_collate(samples) for samples in transposed]
raise TypeError(default_collate_err_msg_format.format(elem_type))
是不是看着有点头大,没有关系,我们先搞清楚他的输入是什么。这里可以看到他的输入被命名为batch,但是我们还是不知道到底是什么,可以猜测应该是一个batch size的数据。我们继续往后找,可以找到这个地方。
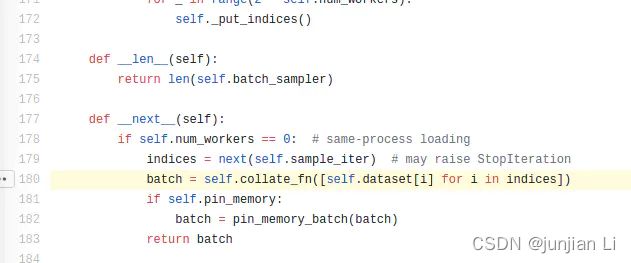
我们可以从这里看到collate_fn在这里进行了调用,那么他的输入我们就找到了,从这里看这就是一个list,list中的每个元素就是self.data[i],如果你在往上看,可以看到这个self.data就是我们需要预先定义的Dataset,那么这里self.data[i]就等价于我们在Dataset里面定义的__getitem__这个函数。
所以我们知道了collate_fn这个函数的输入就是一个list,list的长度是一个batch size,list中的每个元素都是__getitem__得到的结果。
这时我们再去看看collate_fn这个函数,其实可以看到非常简单,就是通过对一些情况的排除,然后最后输出结果,比如第一个if,如果我们的输入是一个tensor,那么最后会将一个batch size的tensor重新stack在一起,比如输入的tensor是一张图片,3x30x30,如果batch size是32,那么按第一维stack之后的结果就是32x3x30x30,这里stack和concat有一点区别就是会增加一维。
所以通过上面的源码解读我们知道了数据读入具体是如何操作的,那么我们就能够实现自定义的数据读入了,我们需要自己按需要重新定义collate_fn这个函数
参考:
PyTorch实现自由的数据读取