一些经典的召回算法模型
1. Airbnb论文:Real-time Personalization using Embeddings for SearchRanking at Airbnb
Embedding 向量最终能表达实体在某个空间里面的距离关系(相似性)。在NLP领域中,表示的的是语义空间。在其他场景中,以电商举例,我们会直接对商品 ID 做 Embedding,其训练的语料来自于用户的行为日志,故这个空间是用户的兴趣点组成。行为日志的类型不同,表达的兴趣也不同,比如点击行为、购买行为,表达的用户兴趣不同。故商品 Embedding 向量最终的作用,是不同商品在用户兴趣空间中的位置表达。作者在文章中大胆地假设客户某一次点击的商品和他之前和之后点击的商品存在着一定的联系,因此可以将skip-gram这种模型应用到这种场景中得到需要的embedding。
算法本质:根据点击顺序生成商品序列,然后借用skip-gram模型训练得到embedding
文章的算法核心是训练了两个模型(两套embedding):
- 用户的短期实时个性化(listing embedding): 新用户临时决定去哪一个地方去旅游,它们适用于短期、不间断的个性化,目的是向用户显示与他们在内部搜索会话中点击的商品相似的商品。
- 用户的长期个性化(user-type embedding & listing-type embedding): 根据顾客以往的订房时候的喜欢和消费习惯(离市中心距离,价格,房型等等)。
同时因为这是个双边市场,所以既需要对商户优化,也需要对用户优化,所以上面两套embedding很有必要。
1.1 item embedding

训练流程
对每个登录用户,将所有点击过的房源当做一个点击会话click session,并且按照时间先后做排序。如果两次点击之间超过30分钟,则将会话进行分割,构成了session训练集 s s s。公式如下:
![]()

本质思想可以理解为在搜索会话中具有相似(相邻)的list将具有相似的表示。
负采样技巧
我们使用了nlp的负采样方法,这大大降低了计算复杂度。负采样可以表述如下。我们生成一组被点击列表的正对 ( l , c ) (l,c) (l,c),在一个长度为 m m m的窗口内,同一用户在点击列表之前和之后对其他列表的点击;以及一组被点击列表的负对 ( l , c ) (l,c) (l,c)和来自整个词汇表 v v v的 n n n个随机抽样列表。然后优化目标变成:

使用最终预订的房源作为全局上下文 (Global Context)
我们使用以用户预订了房源(上图中紫色标记)为告终的用户会话来做这个优化,在这个优化的每个步骤中我们不仅预测相邻的点击房源,还会预测最终预订的房源。 当窗口滑动时,一些房源会进入和离开窗口,而预订的房源始终作为全局上下文(图中虚线)保留在其中,并用于更新中央房源向量(在我看来,增加booked listing作为global context参加每个滑窗的学习,就是为了弥补套用word2vec的窗口限制而带来的信息损失。)。

负样本改进:增加地区限制
因此,对于给定的中心房源,正相关的房源主要包括来自相同目的地的房源,而负相关房源主要包括来自不同目的地的房源,因为它们是从整个房源列表中随机抽样的。 我们发现,这种不平衡会导致在一个目的地内相似性不是最优的。 为了解决这个问题,我们添加了一组从中央房源的目的地中抽样选择的随机负例样本集。

新房源冷启动问题
平台上每天都会上传新的房子,这些房子一开始没有embeddings,可以用以下规则来利用已有的embedding生成:
- 取周围10公里内最近的的三套房子embedding取平均值
- 相同类型
1.2 user-type embedding & listing-type embedding

数据稀疏,点聚合成类
老用户的多次预订可能是在不同的地方或者城市。但是上面学习到的房源的embedding,很难去比较不同地方的房源的相似性。跨地区的房源相似性,但是直接采用这个思路训练use_id存在几个问题:
- 把客户订过的房子作为一个session数据量不够(有的客户只订过一个房子),过于稀疏。
- 随着客户经济条件的改变,对房子的兴趣爱好也会改变。
采取的策略是从个人换到从全局出发, 把酒店和人进行分类聚类,分别对应于user-type和listing-type。
训练流程
在同一向量空间中训练房源类型和用户类型的embedding。用户的每次预订,都构成一个元组(user_type, listing_type),包含用户类型和房源类型.将每个用户的所有预订的元组,按照时间顺序排列生成预订会话session,用户类型和房源类型交替排列,然后按照skip-gram的方式进行训练。

将拒绝信息作为负采样
现实中存在客户订了房子但是没有通过房主的同意或者客户订完之后取消的。可以利用房东的拒绝行为,在向量空间中编码房东的偏好,在推荐中增加预订几率的同时,减少拒绝的发生:

1.3 如何将embedding用在搜索排序中
离线评估召回算法
离线评估召回性能的难点:召回缺乏显式负反馈。如果召回的,用户没有点击,可能并不代表用户不喜欢,而可能是压根没有曝光给用户;召回,受后面的粗排、精排的影响较大。配合不好,可能排序会大大减弱你这一路召回的影响;召回之间存在重叠、竞争的关系。没准你单路召回的指标非常好看,但是对大盘没什么影响,原因这一路召回的东西和其他线上的召回返回的结果,重合度太高了。
让我们假设我们得到了最近点击的列表和需要排名的候选列表,其中包含用户最终预订的列表。通过计算点击列表和候选列表嵌入之间的余弦相似度,我们可以对候选列表进行排名,并观察预订列表的排名位置,平均为值越低,模型性能越好。
使用embedding在搜索排名中实时个性化
搜索排序问题当做一个回归问题来解决,去拟合标签。标签包括{0, 0.01, 0.25, 1, -0.4},0表示房源曝光给用户但并没有被点击,0.01表示用户点击了房源,0.25表示用户联系了房东但是并没有预订,1表示房源预订成功,-0.4表示房东拒绝了用户的预订。采用的是Gradient Boosting Decision Trees(GBDT)算法。输入特征包括房源特征,用户特征,搜索特征,和交叉特征几个类别,大约100个特征。房源特征包括价格,房源类型,房间数目,拒绝率等。用户特征包括用户的平均预订价格等。查询特征包括入住人数,租住天数等。交叉特征是多个特征的组合,包括搜索位置和房源位置的距离,入住人数和房源容纳人数的差异,房源价格和用户历史预订的平均价格的差异等。模型训练完成后以在线的方式运行,用户搜索之后,对候选房源打分,并按照分数降序排列展示给用户。
介绍一下上文中生成的 list embedding是如何应用到房源搜索排序算法中的。将用户最近两周有行为的房源做个分类,一共包括6个类别,1)用户最近两周点击过的房源,用Hc表示;2)用户点击并且停留时长超过60秒的房源,表示长点击房源,用Hlc表示;3)曝光却没有点击的房源,用Hs表示;4)用户加入收藏的房源,用Hw表示;5)用户联系过房东但是却未预订的房源,用Hi表示;6)用户在过去两周内预定过的房源,用Hb表示。将候选房源与上述6个类别的房源计算相似度,作为特征加入到搜索排序模型中,如图10的前6个特征,EmbClickSim, EmbSkipSim, EmbLongClickSim等。
对于长期兴趣所建模的embedding,取当前的用户类型embedding,和候选房源的房源类型embedding计算余弦相似度,结果既可作为特征加入GBDT:UserTypeListingTypeSim。
实验效果
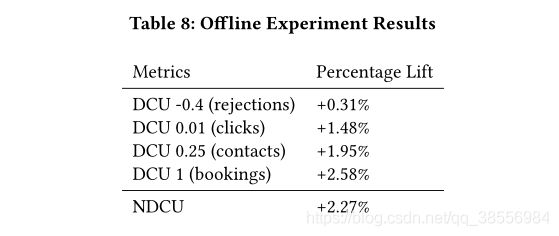
1.4 改进
其实本质上:1. 是构建序列,2. 然后将skip-gram应用在该任务中。
- 第一个是在序列构建方向上。其实来说用户有一个点击序列,每个房源也有一个点击序列,完全可以生成一个很复杂的图,可以用随机游走node2vec来做,也可以考虑GCN来建模。
- 第二个是在skip-gram的缺点,窗口以及顺序问题没有考虑到。当然加入全局信息一定程度上缓解了窗口问题,但窗口外其他的房源就毫不相关了吧,最好有一个自适应的注意力,可以都看到(注意力机制);另外skip-gram是基本不考虑顺序问题的,顺序在这里会有作用吗?
- 第三个是聚类方面,可以参考画像问题,具体参考阿里的GES/EGES算法。
2. Youtube 论文:Deep Neural Networks for YouTube Recommendations
这篇论文是介绍深度学习在推荐系统领域应用的经典之作。将深度学习技术作为一种通用解决方案,来解决所有机器学习问题。因此,看Youtube是如何在运用深度学习的过程中,解决以上这些难题,对于搭建我们自己的推荐系统,具有极大的借鉴意义。
现在YouTube的视频推荐有三个挑战:视频规模大;推新视频的能力;反馈充满噪声。
文章中的一些trick和作者的思路会加粗表示。
Youtube的推荐系统也分为“召回”与“排序”两个子系统。在开发过程中,我们广泛使用离线metrics(精度、召回、排名损失等)以指导对系统的迭代改进。然而,为了最终确定算法或模型的有效性,我们通过现场实验对A/B进行了测试。这很重要,因为实时A/B结果并不总是与离线实验相关(离线和在线的评估以及调参)。

(方便多源混合召回)此外,我们的神经网络架构设计允许混合由其他来源生成的候选源,例如早期工中描述的那些源。
2.1 召回网络

本质:softmax多分类
Youtube将“召回”过程建模成一个拥有海量类别的多分类问题,类别总数就是视频库中的视频总数,数量在百万级别。
重要特征工程:用户向量和视频向量构建
视频向量:就是一个大的embedding,在模型中进行参数共享。整个embedding矩阵属于优化变量,通过训练得到。看似简单的问题,一旦牵扯上海量数据,也变得不那么简单。如果视频库中的视频太多,单机内存装不下怎么办?本文中介绍,Youtube的做法是剔除一些“点击频率太低”的视频,减少候选集合。问题是,新视频的点击频率为0,都被剔除了,这个“召回网络”岂不是失去了“推新”能力?文中没有解释。不过,这个问题也很好解决,Youtube不可能只有“召回网络”这一个召回源,估计Youtube有专门的召回源来发现并召回新视频。
用户向量由三部分组成:用户之前看过的视频。每个视频向量都是通过embedding得到,属于优化变量,训练后获得;用户之前搜索过的关键词。每个词向量也通过embedding获得,属于优化变量,训练后获得;用户的基本信息,比如性别、年龄、登录地点、使用设备等。这些信息,在“新用户”冷启动时,是唯一可以利用的信息。
附加特征:模型附加特征(视频年龄)
使用深度神经网络作为矩阵分解的一个主要优点是,可以很容易地将任意连续和分类的特征添加到模型中。除了以上这些历史向量、人员基本信息的特征以外,Youtube还将视频的年龄作为特征加入训练。视频年龄=(样本提取窗口的最大观测时间)-该视频的上传时间。上传越早的视频(即年龄越大),自然有更多时间“发酵”,也就更有机会成为受欢迎视频。我们在收集训练样本时,就已经加入这个bias了。因此,我们需要在训练时,将这一信息考虑在内。否则,其他特征不得不解释由“上传时间早”而带来的额外的受欢迎性,一个特征承担了本不该其承担的解释任务,容易导致 “过拟合”。但是,在线上召回时,将所有视频的年龄都设置成0,对新老视频“一视同仁”,有利于召回那些“虽然上传时间短,但内容与用户更匹配”的新视频。可以完成“推新”的要求(类似位置偏差的思想)。
反馈指标选择:YouTube watch
在文章中作者并没有使用一些youtube拇指滑动的信息或者产品调查等,我们仅仅使用youtube即时观看反馈来训练模型。因为后者反馈很多,前者反馈稀疏。
任务目标改进:预测下一个观看
我们发现预测用户的下一watch的性能要比预测一块随机放置的watch要好得多。因为后者会泄露未来的信息,并忽略任何非对称的消费模式。相反,我们通过监视来“回滚”用户的历史,并且只输入用户在保留标签监视之前所做的操作。

加速:离线如何加速训练&在线如何及时召回
训练时如何优化这个巨大的softmax loss了。问题的难点在于,这个softmax中的类别个数=候选视频总个数,达到百万级别。这样一来,训练效率将极其低下。解决这一问题的思路,是借鉴NLP,特别是机器翻译、训练词向量中,常见的Sampled Softmax方法。
我们召回时,并不需要计算每个视频的观看概率。在所有视频向量中,寻找与u点积最大的前N个视频向量”的搜索问题。Youtube将训练得到的视频向量存入数据库,并建立索引,从而能够大大加快这一搜索过程。
2.2 排序网络

本质:加权LR预测视频的预期观看时长
为了防止将一些“标题党”推荐给用户,在排序阶段,Youtube预测的是一个视频的平均观看时长,而不是简单的“点击与否”,并按照预测出的“平均观看时长”对视频排序。
特征工程
最重要的特征是描述用户与该视频或相似视频的交互历史的特征,比如:1. 用户与该视频所属频道的交互历史,比如,用户在该频道上看了多少视频?2. 用户与该视频具有相同主题的视频的交互历史,比如,用户多久之前才观看了一个有相同主题的视频。3. 召回时产生的信息,比如召回源和当时召回源所打的分数。
特征优化1: Embedding共享
召回和排序两部分涉及到“视频向量”都来自于同一个embedding矩阵。优化变量的共享,类似于“多任务学习”,既增加了对video embedding的训练机会,也相当于增加了更多的限制,有助于缓解过拟合问题。
特征优化2: 附加特征的小trick
除了原始的标准化特征 x x x、 我们也输入能量̃ X 2 X^2 X2和 s q r t ( x ) sqrt(x) sqrt(x)、 通过允许网络轻松形成特征的超线性和次线性函数,赋予网络更大的表达能力。这样连续特征可以更好的提高离线精度。
预期观察时长的建模
如何让LR预测的是观看时长呢,作者的做法是通过改变样本权重来预测观看时长,这也是预测“观看/阅读时长”常用的一个方法:正样本(点击样本)的权重是该视频被观看的时长;负样本(未点击样本)的权重就是1。
在对正样本重新加权后,排序网络预测出的是视频的平均观看时长。
2.3 改进空间
- 历史信息加入时序,对“历史行为”向量进行加权平均。可以参考attention或者lstm建模的思想。
- 用历史信息来对视频演化建模,丰富item向量(参考阿里论文)。
3. Facebook论文: Embedding-based Retrieval in Facebook Search
这篇文章浓浓的工业风,从工程角度讲解了一个召回的全流程,不管是做语义信息检索召回还是推荐召回都值得认真学习。在数据样本的选择构建上,融合新的召回源,整个搜索链路的优化,以及逐步递进解决问题的思路上有很多我们可以学习的地方。可以将这篇paper提到的某些trick融入到我们自身的业务上。
向量召回的本质在于通过模型学习到query以及doc的embedding,利用embedding的信息去表达,从而利用近邻搜索的方式找到与目标query相关的doc。面临的挑战有以下三个:
- 极大候选集带来的离线训练以及线上服务的压力
- 与现有的term matching共存使用的问题(其他召回源融合)。
- Facebook搜索还有一个独特的点是用户的搜索意图不仅跟query的文本内容有关,还跟提问者及其所处的环境有关,这一点是比常规的信息检索方向要复杂的多的。
3.1 模型
统一embedding模型架构
和双塔结构一样,统一Embedding模型由三部分组成:query编码器生成query的Embedding,文档编码器生成文档的Embedding,相似度计算函数生成文档和query之间的打分。使用Cosine相似度作为相似函数。
评估指标和损失函数
不同于rank使用auc作为离线衡量指标,FB采用了top K recall的方式进行衡量。下面 T T T为基于业务逻辑(如点击/人工标注)圈定出的target doc,而 d i d_i di为基于cosine similarity计算出最相关的docs。
![]()
损失函数方面,FB采用的是triplet loss。即同一个用户与“正文章”的匹配度要比用户与“负文章”的匹配度高于一定的阈值:

训练数据挖掘
负样本的判定上有两种方案,利用展现未点击的数据或者随机选取样本作为负例,通过实验发现,随机选取作为负例的实验效果更好,作者认为原因在于全部以hard case做负样本的训练数据和实际召回任务面对的数据分布不一致,实际索引中大多数是和用户query差别很大的easy case。
正样本的选取上同样有两种方案,利用点击数据或者展现数据。通过实验发现两者的效果基本相近,在点击的数据基础上添加展现数据也没有收益。
3.2 特征工程
统一Embedding模型的优势之一就是可以通过融合文本之外的特征提升模型。FB的统一Embedding模型相比只基于文本特征的模型,在事件搜索上的召回率可以提升18%,分组搜索的召回率提升16%。统一Embedding模型中用到的特征主要有Text文本特征、位置特征、社交Embedding特征。
3.3 线上服务
FB重建了一同融合term match与embedding match的召回系统,搞了大名鼎鼎的Faiss,通过Faiss进行向量压缩(embedding量化)并且将它融合进倒排索引中。
暴力搜索的时间在海量规模下是不现实的,Embedding量化就是为了解决向量空间搜索的效率问题。 文章中采用的是粗糙量化+残差量化:层次量化,粗糙量化使用聚类量化,再对残差结果进行细粒度的乘积量化,具体来说就是,每个向量先进行粗糙量化划分到某个粗糙聚类簇里,对应某个类簇标识id,然后计算残差向量(向量-聚类簇中心向量),对残差向量进行分块,执行细粒度分块残差量化,每个残差向量m块,对应m个类簇标识id。因为原始向量聚类后,不同类簇可能分布的比较分散,样本数极度不平衡,而计算残差可以缩小这种不平衡。层次量化对于每个doc生成两个字段:粗糙量化id,残差量化code,用于实时检索使用。文章中也介绍了ANN调参过程中的一些经验技巧。
Facebook原本的检索引擎支持的是布尔检索,为了避免创建新的系统,扩展了现有引擎的embedding字段以支持nn查询操作)。索引阶段,每个文档的Embedding被量化成一项(粗糙类簇)和一个payload(量化后的残差向量)。查询阶段,nn查询操作会被改写成一个or运算项,or的内容是和查询Embedding最近的n个粗糙类簇,对于匹配到的文档再使用payload验证半径限制。这里作者针对NN操作对比了半径查询模式和top-K查询模式,发现半径模式更能平衡系统性能和结果质量。为了提升查询效率和结果质量,避免过度触发、海量空间占用、无用内容堆积等问题,作者在响应过程中使用了一些规则过滤掉EBR会表现差的查询,比如用户搜索之前搜索过或点击过的东西,或者搜索意图完全不同于Embedding模型的训练含义的,只针对月活用户、最近的事件、比较流行的页面和小组做索引选择加快搜索速度。
3.4 全链路优化
向量召回作为retrieval的一个部分,处于整体搜索链路比较前的位置,有可能有召回到较好的doc但是在排序阶段没有办法排到前边去,排序模型对新的数据不敏感,没有办法很好的处理新的数据分布。这就形成一个恶性循环,新召回被ranker歧视,后验指标不好看,让ranker歧视的理由更加充分,曝光的机会更小,排到的位置更差。因此FB提出了下边两种方案来解决这个问题:
- 将召回生成的embedding作为ranking阶段的特征,可以直接将embedding作为特征或者计算query和doc的embedding各种相似度,通过大量实验证明,consine similarity有较好的结果。
- 为了解决向量召回准确率较低的问题,将向量召回的结果直接进行人工标注,然后再基于标注的结果进行训练。我个人认为这种方法比较暴力并且效率比较低
3.5 高级主题
hard样本挖掘
模型分析时发现Embedding搜索的topK结果,通常具有相同的名字,因此猜测模型并不能很好的利用社交特征,很有可能是因为随机挑选的负样本区分度太明显了,太easy。所以要选取一部分匹配度适中的,能够增加模型在训练时的难度,让模型能够关注细节,这就是所谓的hard negative。
hard负样本:因此需要挖掘一些和正样本相似度比较高的负样本。文中尝试了在线和离线两种生成hard负样本的方法:在线是指在训练过程中,把同一个batch内部的其他正样本作为当前样本的负样本,实验证明这一方法能在所有指标上大幅提升模型质量,且每个正样本生成两个hard负样本是最优的;离线的方式则是个迭代的过程,根据规则从每个query生成topK的结果中选择hard负样本生成新的训练数据,重新训练模型,文章中是拿召回位置在101~500上的物料。不过需要特别强调的是,hard negative并非要替代easy negative,而是easy negative的补充。在数量上,负样本还是以easy negative为主,文章中经验是将比例维持在easy:hard=100:1。
hard正样本:作者的思路在于将挖掘之前没有被召回过的正例,我理解的是在用户没有点击的搜索行为中,去挖掘潜在的相关doc,这个挖掘方法是通过向量召回top k作为正样本加入模型中。
Embedding模型集成
作者考虑以多阶段的方式融合针对不同难度的样本训练模型,即第一阶段关注模型召回率,第二阶段困难样本专注于区分第一阶段中比较相似的结果(提高精确率)。文中试验了两种模型集成方式:权重拼接和模型级联,而且这两种都证明是有效的方式。
权重拼接:不同模型可以并行训练,针对每个query和文档对,每个模型都会得到一个相似度分值,根据每个模型分配到的权重得到这些分值的加权和作为最终的相似度分值。实际系统中通过将query和文档的embedding各自规范化之后,将模型的权重乘到query侧或文档侧再按照正常累加的方式计算相似度。
模型级联:得到第一阶段的结果之后才会进行第二阶段的计算。观察实验诗句发现,unified embedding在一些简单的text匹配上反而表现的没有基础模型好,这是由于context信息起到了过重的作用。为了解决这个问题,作者提出了使用text-matching的方法做第一阶段召回,用unified-embedding的方法做第二阶段召回。
3.6 感悟
知乎上有一篇《负样本为王》很好的总结了这篇论文。
重中之重是"筛选(负)样本"。
- 明确指出,召回不能(只)拿“曝光未点击”做负样本。离线训练数据的分布,应该与线上实际应用的数据,保持一致。召回是“是将用户可能喜欢的,和海量对用户根本不靠谱的,分隔开”,所以召回在线上所面对的数据环境,就是鱼龙混杂、良莠不齐。所以,要求喂入召回模型的样本,既要让模型见过最匹配的,也要让模型见过最不靠谱的,才能让模型达到"开眼界、见世面"的目的,从而在“大是大非”上不犯错误。
- 但是,使用随机采样做负样本,也有其缺点,这样训练出来的模型,只能学到粗粒度上的差异,却无法感知到细微差别。例如一个推荐宠物的算法,能够正确做到向爱狗人士推荐狗,向爱猫人士推荐猫,但是在推荐狗的时候,无法精确感受到用户偏好上的细微差别,将各个犬种一视同仁地推出去。这样的推荐算法,用户也不会买账。
- 挖掘Hard Negative增强样本。要选取一部分匹配度适中的,能够增加模型在训练时的难度,让模型能够关注细节,这就是所谓的hard negative。hard negative并非要替代easy negative,而是easy negative的补充。在数量上,负样本还是以easy negative为主。毕竟线上召回时,绝大多数的物料是与用户八杆子打不着的easy negative,保证easy negative的数量优势,才能hold住模型的及格线。
- 第3条只是从“样本增强”的角度来利用hard negative。还有一种思路,就是用不同难度的negative训练不同难度的模型,再做多模型的融合,包括并行拼接和串行级联。
4. 百度论文:Sample Optimization For Display Advertising
样本的构建往往被忽略掉其重要性。”模型拟合数据,数据决定了模型上界“,因此,训练样本的构建应该得到充分地重视。但是,用户观察到的广告与所有可能的广告之间存在协变量偏移问题。在论文中利用几种样本优化策略来缓解协变量偏移问题,从而训练候选模型。
从数据的角度看,为了训练一个比较好的召回模型,面临以下挑战:
- 协变量偏移,样本分布偏差:广告是经过召回阶段选择出一部分广告,再经过排序选择最高的几个展示给用户。因此只有少数会展示给用户,但模型却需要在整个广告库中进行预测,二者之间样本分布是不同的。
- 真实的广告曝光数据通常是长尾分布,高频广告在广告库中只占小部分,也就是说少数的广告占据了大部分的曝光。这些广告通常更重要,有更高的出价。但由于大部分曝光的广告没有被用户点击,所以负样本中会出现许多这些高频广告。用这些广告作为负样本训练,就会被模型抑制,召回概率降低,收益也会减少。
- 曝光但未点击的广告,不一定是真正的负样本。在展示广告服务系统中,大多数曝光的广告并没有被点击,有很多方面的原因,不能简单认为他们与用户的兴趣不匹配。这种不确定性给模型训练带来了挑战,因为很难区分什么样本是真正的负样本。
- 广告点击率低,导致训练数据非常稀疏,尤其是正样本会不足。
许多工作集中于设计更好的排序模,但是很少研究如何从数据的角度训练更好的候选召回模型。
论文的贡献如下:
- 为了解决协变量偏移问题,首先研究了各种样本优化策略,以训练更好的候选生成模型。尽管在论文中专注于展示广告,但是大多数策略也适用于一般的个性化搜索和推荐系统。
- 进行了广泛的离线和在线实验,以评估这些策略并总结每种策略对整体效果的贡献。
4.1 Weighted Random Negative Sampling
首先,根据广告的曝光频次对广告进行分组,将大于阈值的记为 A h A_h Ah, 小于阈值的为 A l A_l Al;然后,生成一个 ( 0 , 1 ) (0,1) (0,1)之间的随机数 p p p。如果 p p p小于 P l P_l Pl,则从 A l A_l Al使用均匀采样的方法得到一个广告,否则从 A h A_h Ah中基于unigram distribution分布采样得到一个广告。
4.2 Real-Negative Subsampling
百度广告展示系统整体的广告点击率只有0.03%。而且曝光是长尾分布的,所以少数的广告占据了大部分曝光。这些广告可能同时出现在正样本和负样本中。我们不希望这些广告出现在负样本中被压制,因为他们通常具有很高的商业价值。因此会对这部分广告进行降采样。方法:训练集中具有较高曝光频率的广告的负样本三元组,以这个概率丢弃。广告的曝光频次越高,丢弃的概率越大。
4.3 Sample refinement with PU Learning
展示给用户但没有被点击的帖子并不能代表与用户不相关,例如,展现给用户一个武侠帖子用户没有点击,原因是多样的:其一,用户喜欢武侠这一类型, 但不喜欢该帖子;其二,用户喜欢武侠,当前时间却不想看武侠;其三,用户就是不喜欢武侠,等等。因此,需要通过某种方式筛选出用户真正不喜欢的帖子。论文中提出了”spy technique“,做法不难,这里不再介绍了。其实,也可以尝试其他方法去掉潜在正样本,比如去掉一个session里与被点击帖子相似度较高的未被点击的帖子。
4.4 Fuzzy Positive Sample Augmentation
该方法对正样本增强。由于候选帖子经过了召回、粗排、精排、重排等环节,那些没有展示给用户的帖子也可能是用户感兴趣的,因此,可以从未曝光给用户的帖子中选择收益较大的帖子作为正样本,由于这些是”模糊正样本“,因此其label应该设置为小于1的数值。
4.5 Sampling with Noise Contrastive Estimation (NCE)
最后一种方法是在采样时使用Noise Contrastive Estimation (NCE)的方式。该方法根据曝光量对样本进行分组,大于某个阈值的为一组,小于等于某个阈值的为另一组。对于一个正例,选择负例的方法为:基于噪声分布从高频区域采样,或者从低频区域均匀采样。
4.6 评估指标及实验结果
作者的离线指标选择的是 c l i c k − r e c a l l click-recall click−recall以及 c o s t − r e c a l l cost-recall cost−recall,线上指标是 C P M CPM CPM。
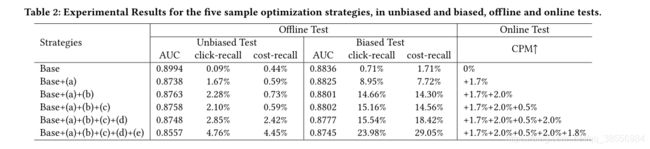
Unbiased Test Set(召回之后直接曝光给用户),Biased Test Set(召回之后经过排序、重排等策略曝光给用户),Base是点击作为正样本,曝光未点击作为负样本。可以看出,这两个测试集上,试验路AUC全部低于Base路,但是试验路在召回能力以及线上cpm上明显优于Base路,可能的原因是试验路更好的捕捉到了用户兴趣而不是一味的拟合历史数据。随后作者还进行了消融实验。
5. 阿里论文:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
在淘宝的推荐中,主要面临着三个技术挑战,分别是可扩展性、稀疏性、冷启动问题。本文提出了一种图嵌入(graph embedding)的方法来解决上面的三个问题。在召回阶段,主要的方法是计算商品之间的相似性,从而根据用户的历史交互行为得到用户可能喜欢的相似商品。计算商品的相似性,可以采用协同过滤的方法,但是协同过滤仅仅考虑了商品在交互矩阵中的共现性;使用图嵌入(Base Graph Embedding (BGE))的方法,比如随机游走的方法,可以学习到比较好的商品之间的相似性,但是对于出现次数很少甚至没有用户交互过的商品,依然难以有效地学习。
因此,本文提出使用基于side information的图嵌入学习方法,称作Graph Embedding with Side information (GES)。这里的side information你可以理解为辅助信息,比如一个商品的品牌、店铺名、类别等等。使用side information来学习商品的embedding的话,同一个品牌或者类别的商品应当更相似。但是在淘宝中,有数以百计的side information,这些side information对于商品向量的贡献程度是不同的,比如一个购买了iphone的用户,倾向于查看mac或者ipad,更多的是因为他们都是苹果的牌子。考虑不同的side information对最终的item embedding的不同影响,这种方法称作Enhanced Graph Embedding with Side information (EGES)
有两个启示:
- 构建图嵌入+解决图嵌入的冷启动问题
- side information对于商品向量的贡献程度是不同的,如一个购买了iphone的用户,倾向于查看mac或ipad,更多的是因为他们都是苹果的牌子。考虑不同的side information对最终的item embedding的不同影响。
想想这些工作都是怎么推新的,如何低延时线上服务,如何平衡explore/exploit。
- 爱彼迎:可以通过一些规则来利用已有的房源embedding生成;维度仅设为32维,负采样技巧。
- 油管:利用其它召回源,加入视频年龄信息,线上召回一视同仁;离线进行负采样,线上进行top-N。
- 脸书:;embdding量化,即向量压缩。
基于PQ量化的近似近邻搜索 (ANN) :https://mp.weixin.qq.com/s/vD6e3-LT9uHVvdZ8uTeQZA
腾讯query搜索:https://mp.weixin.qq.com/s/Kv_qHkLxwWTZUEXaOEOpwQ