推荐系统——召回模型
YoutubeDNN
内容
YoutubeDNN是Youtube用于做视频推荐的落地模型,可谓推荐系统中的经典,其大体思路为召回阶段使用多个简单模型筛除大量相关度较低的样本,排序阶段使用较为复杂的模型获取精准的推荐结果。
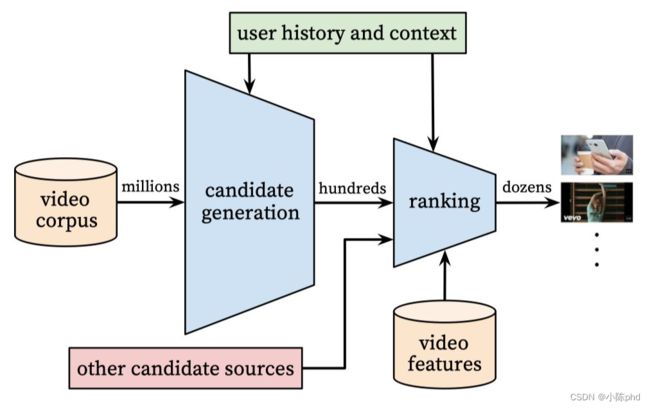 召回部分: 主要的输入是用户的点击历史数据,输出是与该用户相关的一个候选视频集合;
召回部分: 主要的输入是用户的点击历史数据,输出是与该用户相关的一个候选视频集合;
精排部分: 主要方法是特征工程, 模型设计和训练方法;
线下评估:采用一些常用的评估指标,通过A/B实验观察用户真实行为;
其中,召回模型将百万级的数据筛除到百,排序模型从数百个数据中获取数十个推荐结果。排序模型的输入特征中,引入了更多描述用户、video以及二者关系的特征。
-
如何实现预测next watch的多分类任务,使用负采样把一个多分类变为多个二分类。
-
在serving时为什么不用训练的召回模型去预测,而是用最近邻搜索,因为serving时使用召回模型对百万级的数据逐一预测太过耗时,因此通过训练得到user和video的embedding后,只需通过相似度取TopK即可。
-
对训练集预处理时,不采用原始用户日志而是对每个用户取等量样本减少高活跃用户对模型的过度影响。
-
优化目标为什么不用经典的CTR、播放率,而是用曝光预期播放时长。从模型角度看,观看时长更能反映用户的真实兴趣;从商业角度看,观看时长越长,获得的广告收益越多;且增加用户的观看时长更符合一个视频网站的长期利益和用户粘性。
-
在做video embedding时,直接把大量长尾video用零向量代替,节省serving时的内存资源。
数据类型
输入层是用户观看视频序列的embedding mean pooling、搜索词的embedding mean pooling、地理位置embedding、用户特征;
输入层给到三层激活函数位ReLU的全连接层,然后得到用户向量;
最后,经过softmax层,得到每个视频的观看概率。
import torch
import torch.nn.functional as F
from torch_rechub.basic.layers import MLP, EmbeddingLayer
from tqdm import tqdm
class YoutubeDNN(torch.nn.Module):
def __init__(self, user_features, item_features, neg_item_feature, user_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.neg_item_feature = neg_item_feature
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
# 计算相似度
y = torch.mul(user_embedding, item_embedding).sum(dim=2)
y = y / self.temperature
return y
def user_tower(self, x):
# 用于inference_embedding阶段
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True)
user_embedding = self.user_mlp(input_user).unsqueeze(1)
user_embedding = F.normalize(user_embedding, p=2, dim=2)
if self.mode == "user":
return user_embedding.squeeze(1)
return user_embedding
def item_tower(self, x):
if self.mode == "user":
return None
pos_embedding = self.embedding(x, self.item_features, squeeze_dim=False)
pos_embedding = F.normalize(pos_embedding, p=2, dim=2)
if self.mode == "item":
return pos_embedding.squeeze(1)
neg_embeddings = self.embedding(x, self.neg_item_feature, squeeze_dim=False).squeeze(1)
neg_embeddings = F.normalize(neg_embeddings, p=2, dim=2)
return torch.cat((pos_embedding, neg_embeddings), dim=1)
DSSM
原理
利用深度神经网络将文本表示为低维度的向量,应用于文本相似度匹配场景下的一个算法。
可以用于相似度计算
特点L相似性计算的场景
先后实现原理
使用深度学习网络将query和doc映射到相同维度的语义空间中,即query侧特征的embedding和doc侧特征的embedding,从而得到语句的低维语义向量表达sentence embedding,用于预测两句话的语义相似度。
模型结构:=分别经过各自的DNN得到embedding,再计算两者之间的相似度,类似孪生网络
特点:
- user和item两侧最终得到的embedding维度需要保持一致,特征向量大小统一
-
对物料库中所有item计算相似度时,负采样进行近似计算, 在海量的候选数据进行召回的场景下,速度很快 - 缺点:双塔结构无法考虑两侧特征之间的交互信息,在一定程度上牺牲掉模型的部分精准性。
模型采样方式
正负样本采样
正样本:选“用户点击”的item为正样本。最多考虑一下用户停留时长,将“用户误点击”排除在外
负样本:user与item不匹配的样本,为负样本。
其它方式
全局随机采样: 从全局候选item里面随机抽取一定数量作为召回模型的负样本,但可能会导致长尾现象。
全局随机采样+热门打压:对一些热门item进行适当的采样,减少热门对搜索的影响,提高模型对相似item的区分能力。
硬标签增强
Hard Negative增强样本:选取一部分匹配度适中的item,增加模型在训练时的难度
随机采样
Batch内随机选择:利用其他样本的正样本在batch内随机采样作为自己的负样本
import torch
from torch import nn
class DSSM(nn.Module):
def __init__(self, user_features, item_features, user_params, item_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.item_dims = sum([fea.embed_dim for fea in item_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.item_mlp = MLP(self.item_dims, output_layer=False, **item_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
# 计算余弦相似度
y = torch.mul(user_embedding, item_embedding).sum(dim=1)
return torch.sigmoid(y)
def user_tower(self, x):
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True)
# user DNN
user_embedding = self.user_mlp(input_user)
user_embedding = F.normalize(user2embedding, p=2, dim=1)
return user_embedding
def item2tower(self, x):
if self.mode == "user":
return None
input_item = self.embedding(x, self.item_features, squeeze_dim=True)
# item DNN
item_embedding = self.item_mlp(input_item)
item_embedding = F.normalize(item_embedding, p=2, dim=1)
return item_embedding
- DSSM为双塔模型,user与item分别经过的DNN得到embedding,再计算两者之间的相似度。
- 训练样本,正样本为正确的搜索目标,负样本为全局采样+热门打击所得到的负样本。
- YoutubeDNN在双塔模型基础上进行了改进,
- 召回阶段使用多个简单模型筛除大量相关度较低的样本,有点MTCNN筛选的思想,最后用个决策网络
- 排序阶段使用较为复杂的模型获取精准的推荐结果。
- DSSM核心思想是把查询文本(query)和内容文本(doc)映射到同维度的语义空间中, 以最优化查询文本和内容文本的语义向量之间的余弦相似度为目的