图算法在转转推荐算法召回及粗排的实践
文章目录
-
- 一、转转推荐算法介绍
-
- 1.1 什么是推荐系统?
- 1.2 转转推荐主要场景及流程
- 二、图算法原理介绍及转转实践
-
- 2.1 经典Graph Embedding方法:DeepWalk
- 2.2 结构性与同质性:node2vec
- 2.3 融合辅助信息:EGES
- 2.4 辅助信息融入建图:转转召回实践
- 2.5 异构图表示:转转粗排实践
- 三、总结
- 参考资料
一、转转推荐算法介绍
1.1 什么是推荐系统?
随着信息技术与互联网的飞速发展,借由互联网所传递的信息也在飞速地膨胀,人类从信息匮乏时代走向了信息过载时代,推荐系统开始在互联网技术中扮演不可或缺的角色。推荐系统帮助人们更高效地建立与信息的连接,节约信息筛选的时间,为用户匹配、探索兴趣,也让平台的高效分发成为可能。对于转转来说,推荐系统承担了为用户推荐商品与内容的重要角色,一方面链接了用户与商品的关系,为用户节约筛选心仪产品的时间,帮助用户在平台琳琅满目的商品中发现感兴趣的商品;另一方面帮助商家让自己的商品从海量商品中脱颖而出,推荐给合适的用户。在推荐系统中,推荐算法扮演了发动机的作用。
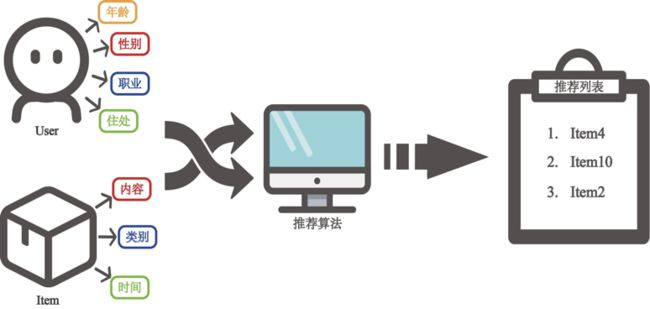
1.2 转转推荐主要场景及流程
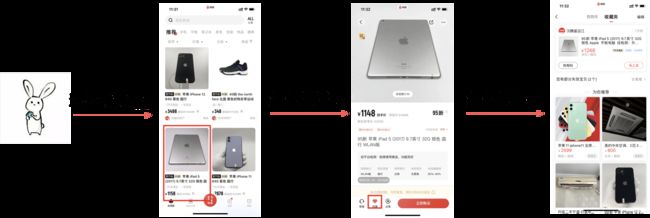
在转转APP中,推荐算法涉及的主要场景包括首页推荐、商详页推荐以及收藏夹推荐等等。用户进入APP后,在主页面下滑即进入首页推荐场景,该场景由算法推荐用户可能感兴趣的商品流,帮助用户进行商品的筛选和探索;当用户点击一个商品后,即进入商详页推荐,为用户推荐与主商品相似的更多商品以挑选;当用户收藏商品后,也会根据用户的收藏行为和历史兴趣,为用户推荐更多的商品。
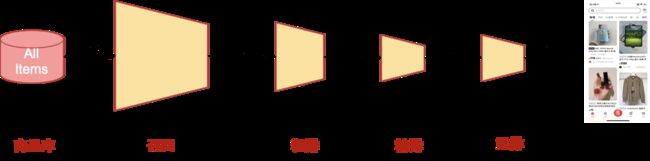
推荐算法的主要流程如图所示,整个流程呈漏斗形,对商品库进行层层筛选,最后将推荐结果呈现给用户。
召回是推荐算法的第一阶段,根据用户和商品信息从海量的商品库中,快速筛选出用户可能感兴趣的商品集,传递给接下来的粗排及精排部分。由于面对的商品集合非常大,因此召回阶段对于性能要求高,需要用相对简单的模型及特征;
粗排则承接召回筛选过的商品,为用户推荐的候选集打分,并筛选出精排候选,作为一个承上启下的阶段,模型及特征的复杂度相对折中;
精排则通常只对少量商品进行排序,可以使用较多特征及复杂模型,对于推荐的准确度要求更高;
最后会根据业务特点及其他目标进行重排,在此不再赘述。
本次分享主要介绍图算法的原理以及在转转召回及粗排阶段的实践。
二、图算法原理介绍及转转实践
图是一种基础且常用的数据结构,也广泛存在于真实世界的多种场景中,例如社交网络中人与人的联系、生物中蛋白质的作用以及电商中用户与商品之间的关系等等。
在转转的场景中,通过对用户与商品关系的建图以及在此基础上的图表示学习,我们能够得到低维、稠密、实值的向量,能够表达节点之间内在的关系。
利用得到的向量,既可以作为排序层的预训练特征,也可以直接计算向量相似度,寻找相似的商品,并直接推荐给用户。
2.1 经典Graph Embedding方法:DeepWalk
首先介绍经典的Graph Embedding方法——DeepWalk。
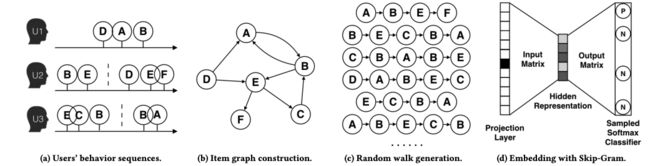
DeepWalk在电商场景应用的大体流程可以分为以下四个步骤:
- 获取用户原始行为序列,并根据一定规则进行切分(如点击间隔超过1小时)。
- 基于这些切分的用户序列,构建商品图结构。例如用户A依次产生了D、A、B的行为,则构建D->A的有向边、A->B的有向边。将所有用户序列产生的商品共现对如(D,A)都建立有向边后,即建立起全局的商品图。
- 选取多个起始点(实际上可以以每个节点为起始点)进行随机游走,得到多条序列。
- 将重新生成的物品序列利用word2vec模型里的skip-gram算法进行图向量的训练和获取。
其中关键是第三步的随机游走过程,即如何选择下一个游走的节点。DeepWalk定义节点 v i v_i vi到 v j v_j vj的转移概率如下:
P ( v j ∣ v i ) = { M i j ∑ j ∈ N + ( v i ) M i j , v j ∈ N + ( v i ) 0 , e i d ∈ ε P(v_j\mid v_i)=\begin{cases} \frac{M_{ij}}{\sum_{j\in N_+(v_i)}M_{ij}}, &v_j\in N_{+}(v_i)\\ 0, &e_{id}\in \varepsilon \end{cases} P(vj∣vi)={∑j∈N+(vi)MijMij,0,vj∈N+(vi)eid∈ε
其中 N + ( v i ) N_+(v_i) N+(vi)是 v i v_i vi的所有出边集合, M i j M_{ij} Mij是节点 v i v_i vi到 v j v_j vj的边权重。
2.2 结构性与同质性:node2vec
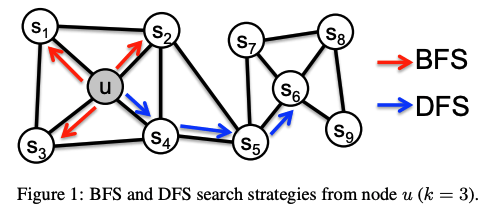
在DeepWalk的基础上,node2vec改进了随机游走过程的游走概率,引入了两个超参数来平衡图的两类游走方式——广度优先BFS和深度优先DFS。
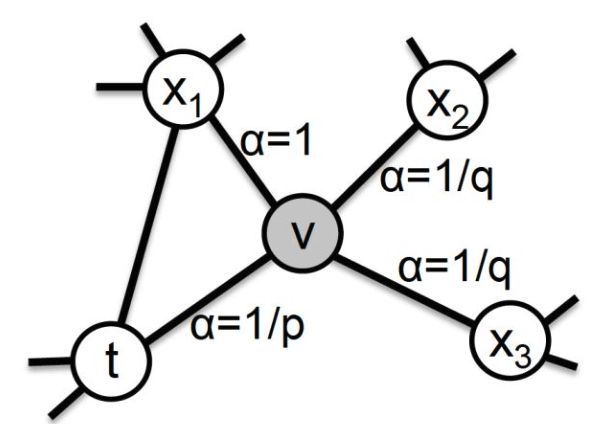
通过引入超参数p和q,算法能够控制节点的游走倾向性。将节点的游走概率定义为 π v x = α p q ( t , x ) ⋅ w v x \pi_{vx}=\alpha_{pq}(t,x)·w_{vx} πvx=αpq(t,x)⋅wvx,其中 w v x w_{vx} wvx是边vx的权重, α p q ( t , x ) \alpha_{pq}(t,x) αpq(t,x)定义如下:
α p q ( t , x ) = { 1 p , d t x = 0 1 , d t x = 1 1 q , d t x = 2 \alpha_{pq}(t,x)=\begin{cases} \frac{1}{p}, &d_{tx}=0 \\ 1, &d_{tx}=1 \\ \frac{1}{q}, &d_{tx}=2 \end{cases} αpq(t,x)=⎩ ⎨ ⎧p1,1,q1,dtx=0dtx=1dtx=2
其中, d t x d_{tx} dtx指节点 t t t到节点 x x x的距离,超参数p被称为返回参数,p越小,返回原节点的概率越大,游走偏向BFS,更关注结构性相似;q被称为进出参数,q越小,则随机游走向更远节点的概率越大,游走偏向DFS,更关注同质性相似。
在推荐系统中,同质性相似的物品体现在同品类、同属性或者经常被一同点击、购买的商品;而结构性相似的物品则体现在各品类的爆款、各品类的最佳凑单商品等趋势类似的商品。node2vec相比DeepWalk拥有更强的灵活性,能够帮助我们根据应用场景的不同选择不同的游走策略,得到合理的向量表示。
2.3 融合辅助信息:EGES
回顾下DeepWalk一节中介绍的算法流程,能够发现一个问题:对于新商品或者用户交互较少的商品,很可能是孤立的节点或者节点权重很小,导致不能游走到该节点或游走到该节点的概率很低。如何解决这类冷启动问题?
阿里2018年提出的EGES(Enhanced Graph Embedding with Side Information)在skip-gram的向量嵌入过程中,除了采用序列的ID类embedding之外,还引入了带权的辅助信息(side information)来缓解该问题。
EGES到生成商品序列前的流程与DeepWalk介绍的一致,但是在最后的嵌入过程中,引入了如类别、品牌、所在城市等辅助信息的多个embedding共同训练。对于多个embedding,最简单的融合方法即average pooling,形式化定义如下:
H v = 1 n + 1 ∑ s = 0 n W v s H_v=\frac{1}{n+1}\sum_{s=0}^{n}W_v^s Hv=n+11s=0∑nWvs
利用以上公式即平均操作,将不同的辅助信息向量与原物品向量融合,其中 W 0 W^0 W0代表原始物品的embedding, W 1 . . . W n W^1...W^n W1...Wn代表每种side information对应的embedding。
但是在实际问题中,不同的辅助信息对于物品的贡献应有所不同,如一个购买了iPhone的用户,倾向于查看MacBook和iPad,是因为品牌。引入加权形式的辅助信息利用,能够得到更准确的embedding。
H v = ∑ j = 0 n e a v j W v j ∑ j = 0 n e a v j H_v=\frac{\sum_{j=0}^ne^{a_v^j}W_v^j}{\sum_{j=0}^ne^{a_v^j}} Hv=∑j=0neavj∑j=0neavjWvj
在GES模型的基础上,引入权重 a 1 . . . a n a^1...a^n a1...an,通过Hidden Representation层执行加权平均操作,并输入softmax层,通过反向传播求得权重。
通过 e a j e^{a^j} eaj代替 a j a^j aj,保持权重大于0,分母则起到normalize weights的作用。
最后进行skip-gram的方式训练得到每个商品的embedding和side infomation及对应的权重。
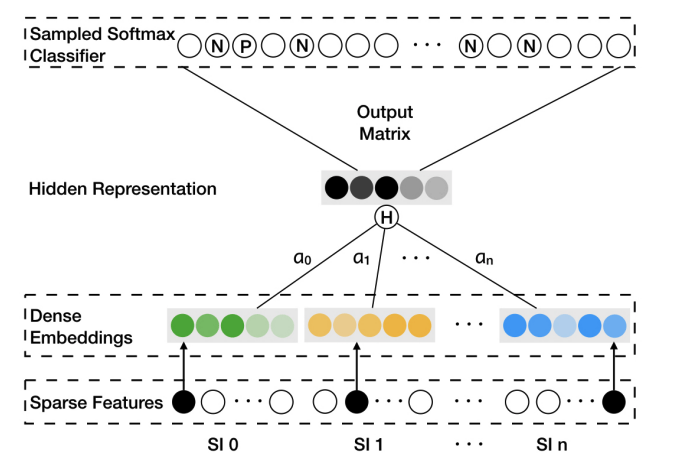
2.4 辅助信息融入建图:转转召回实践
在转转的实际实践中,采用EGES的加强辅助信息融合方式遇到了一些困难,特别是辅助信息融合训练的性能问题。
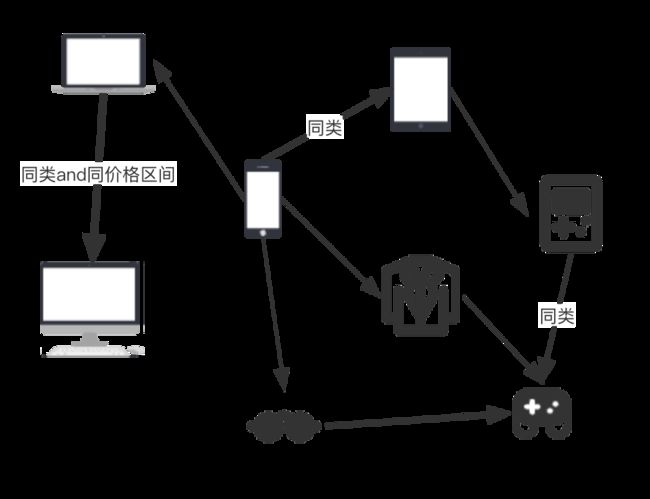
因此,我们采取了影响图权重的方式来引入辅助信息。主要有以下步骤:
- 获取用户序列切分生成共现对,并同步获取相应商品的辅助信息
- 将全局共现对聚合,根据用户交互行为数目确定初始权重
- 根据节点间边的预先定义的几类辅助信息调整权重,例如同类或同价格区间即上调权重
- 进行node2vec随机游走过程并进行向量嵌入训练
通过辅助信息融入建图过程的方法,大大提高了训练速度,并减少了embedding参数量,在实际应用中向量的质量也能够满足需要。在node2vec参数上,可以通过调整同质性相似与结构性相似,来应用于详情页推荐场景与首页推荐场景。
得到商品向量即可进行向量相似度计算,从而进行商品的item2item推荐,或者利用用户交互过的商品进行user2item2item的推荐。
2.5 异构图表示:转转粗排实践
对于粗排来说,需要得到同空间内的用户向量及商品向量,利用内积操作,能够对于用户的召回候选集进行快速的打分和筛选。通常的粗排模型往往采用双塔模型,通过拆分用户塔和商品塔,可以使得向量产出由离线计算完成,线上则采用内积。可见,粗排的关键问题即是用户和商品的向量生成。那么能不能通过图算法来得到用户和商品的向量呢?答案是肯定的。
前几节介绍了Graph Embedding的原理以及一些改进的思路,和转转的召回实践,这些介绍中的图都为同构图,图中的节点都为商品。要同时得到用户和商品的向量,则需要将用户节点也加入到图中,构成异构图。
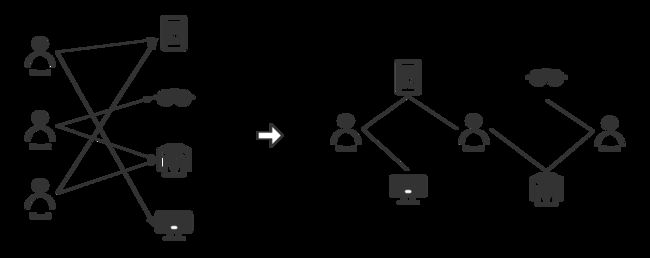
具体的实现步骤如下:
- 获取用户行为序列,并切分为用户-商品二部图
- 根据二部图中的(用户,商品)共现对,建立无向带权图
- 在图中进行随机游走过程,得到形如u1-i1-u2-i2…的序列
- 进行向量嵌入训练,得到用户及商品的向量
离线训练得到向量后,线上分别取得用户及商品向量,进行简单内积后即得商品打分。
三、总结
本次分享介绍了转转的主要场景及算法流程,并介绍了三种常见的图算法:
- 经典的Graph Embedding方法DeepWalk,是各类随机游走算法的基础
- node2vec在DeepWalk的基础上引入超参数控制游走倾向,学习结构性及同质性相似
- EGES则提出融合加权辅助信息,缓解节点冷启动的问题
介绍了上述图算法在转转推荐算法召回及粗排的实践。
图算法目前仍是工程和学术领域研究和实践的热点,除了本次分享介绍的方法,还有如随机游走类的LINE、SDNE以及图卷积类的GAT、GraphSAGE的方法,感兴趣的读者可以深入了解。图卷积算法也在转转有相应的落地和实践,有机会再向大家分享。谢谢!
参考资料
[1]Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 2014: 701-710.
[2]Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 855-864.
[3]Wang J, Huang P, Zhao H, et al. Billion-scale commodity embedding for e-commerce recommendation in alibaba[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 839-848.
[4]王喆:深度学习中不得不学习的Graph Embedding方法 https://zhuanlan.zhihu.com/p/64200072