遗传算法_粒子群算法优化支持向量机分类预测-附代码
遗传算法/粒子群算法优化支持向量机分类预测-附代码
文章目录
- 遗传算法/粒子群算法优化支持向量机分类预测-附代码
- 1. 支持向量机简介与参数优化的原理
-
- 1.1 支持向量机SVM简介
- 1.2 优化参数的选取
- 1.3 交叉验证(CV)
- 2. 数据集介绍和采用的优化算法
-
- 2.1 遗传算法GA优化SVM
- 2.2 粒子群算法PSO优化SVM
- 3. 程序结果和算法的对比
-
- 3.1 SVM
- 3.2 遗传算法GA优化SVM
- 3.3 粒子群算法PSO优化SVM
- 3.4 算法结果的对比
- 4. 小结
- 5. MATLAB代码
1. 支持向量机简介与参数优化的原理
1.1 支持向量机SVM简介
SVM 通过建立输入特征向量和输出的标签向量间的映射模型,来实现分类。即在给定一个样本输入后,能够得到该映射关系下对应输出标签的估计类型。SVM建立模型,通过核函数将低维的输入x输出y转化为高维空间的内积。常见的核函数有线性核函数、RBF 核函数、多项式核函数。由于,相较于线性核函数和多项式核函数,RBF 核函数具有映射维度广、需确定参数少、运算相对简单等优点。所以RBF 核函数是应用最广的核函数。
1.2 优化参数的选取
优化SVM的参数通常是惩罚参数C与核函数参数gamma。惩罚参数 C 的选取可使模型复杂度和训练误差之间达到一种折中。核函数的参数 gamma主要反映训练样本数据的范围特性,直接影响支持向量机模型的学习能力。C的值一般取为1,对于gamma参数的取值,一般默认取1/k,k为总类别数。这两个参数的取值与支持向量机模型学习能力的关系如下图所示:
| C取值 | gamma取值 | SVM模型的学习能力 |
|---|---|---|
| 小 | 小 | 欠学习 |
| 大 | 大 | 过学习 |
为了提高支持向量机的学习能力,提升识别的准确率,通常会采用智能优化算法进行范围内的参数寻优。常用的优化SVM的智能算法比如遗传算法,粒子群算法,布谷鸟搜索算法,鲸鱼算法等。
1.3 交叉验证(CV)
交叉验证(cross validation)是机器学习中选择模型、评估模型好坏常用的一种方法,主要思想是 :在给定的训练样本中,利用其中大部分样本来建立模型,取剩下小部分的样本对建立的模型进行预测,得到这小部分预测结果的预测误差,最后选择预测误差小的模型作为最优的模型。
2. 数据集介绍和采用的优化算法
数据集源自意大利葡萄酒种类的数据,支持向量机为libsvm。采用SVM、遗传算法优化SVM、粒子群算法优化SVM优化c、g参数,进行分类识别的结果对比。
读取EXCEL数据的代码:
%% 读取数据
data=xlsread('数据.xlsx','Sheet1','A1:N178'); %使用xlsread函数读取EXCEL中对应范围的数据即可
%输入输出数据
input=data(:,1:end-1); %data的第一列-倒数第二列为特征指标
output_labels=data(:,end); %data的最后面一列为标签类型
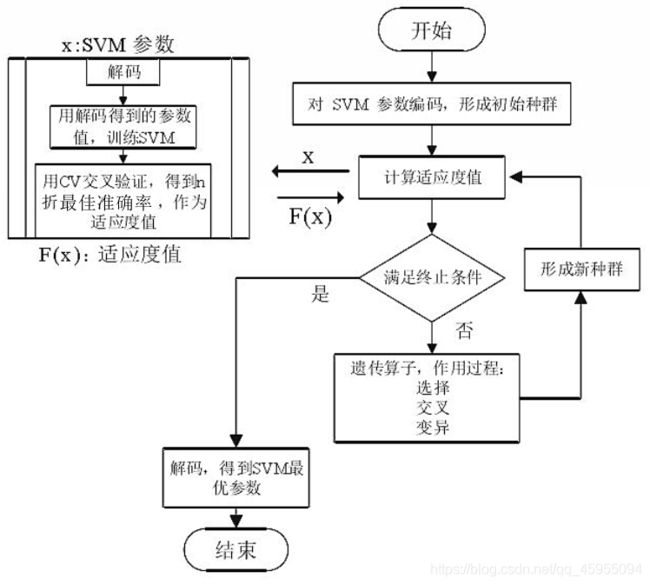
2.1 遗传算法GA优化SVM
选取惩罚参数C与核参数g作为优化变量,用5折交叉验证,得到不同模型的最佳准确率作为适应度函数。
GA参数设置:
ga_option = struct('maxgen',50,'sizepop',20,'ggap',0.9,...
'cbound',[0,100],'gbound',[0,1000],'v',5);
% maxgen:最大的进化代数,默认为50,一般取值范围为[100,500]
% sizepop:种群最大数量,默认为20,一般取值范围为[20,100]
% cbound = [cmin,cmax],参数c的变化范围,默认为(0,100]
% gbound = [gmin,gmax],参数g的变化范围,默认为[0,1000]
% v:SVM Cross Validation交叉验证参数,默认为5
GA优化后的c、g参数给到SVM:
%% 利用最佳的参数进行SVM网络训练
cmd = ['-c ',num2str(bestc),' -g ',num2str(bestg)];
model = libsvmtrain(train_output_labels,train_input,cmd);
建立遗传算法GA优化的SVM模型,流程图如下:
2.2 粒子群算法PSO优化SVM
选取惩罚参数C与核参数g作为优化变量,用5折交叉验证,得到不同模型的最佳准确率作为适应度函数。
PSO参数设置:
pso_option = struct('c1',1.5,'c2',1.7,'maxgen',100,'sizepop',20, ...
'k',0.6,'wV',1,'wP',1,'v',5, ...
'popcmax',10^2,'popcmin',10^(-1),'popgmax',10^3,'popgmin',10^(-2));
% c1:初始为1.5,pso参数局部搜索能力
% c2:初始为1.7,pso参数全局搜索能力
% maxgen:初始为200,最大进化数量
% sizepop:初始为20,种群最大数量
% k:初始为0.6(k belongs to [0.1,1.0]),速率和x的关系(V = kX)
% wV:初始为1(wV best belongs to [0.8,1.2]),速率更新公式中速度前面的弹性系数
% wP:初始为1,种群更新公式中速度前面的弹性系数
% v:初始为5,SVM Cross Validation参数
% popcmax:初始为100,SVM 参数c的变化的最大值.
% popcmin:初始为0.1,SVM 参数c的变化的最小值.
% popgmax:初始为1000,SVM 参数g的变化的最大值.
% popgmin:初始为0.01,SVM 参数g的变化的最小值.
PSO优化后的c、g参数给到SVM:
%% 利用最佳的参数进行SVM网络训练
cmd = ['-c ',num2str(bestc),' -g ',num2str(bestg)];
model = libsvmtrain(train_output_labels,train_input,cmd);
建立粒子群算法PSO优化的SVM模型,流程图如下:

3. 程序结果和算法的对比
3.1 SVM

3.2 遗传算法GA优化SVM
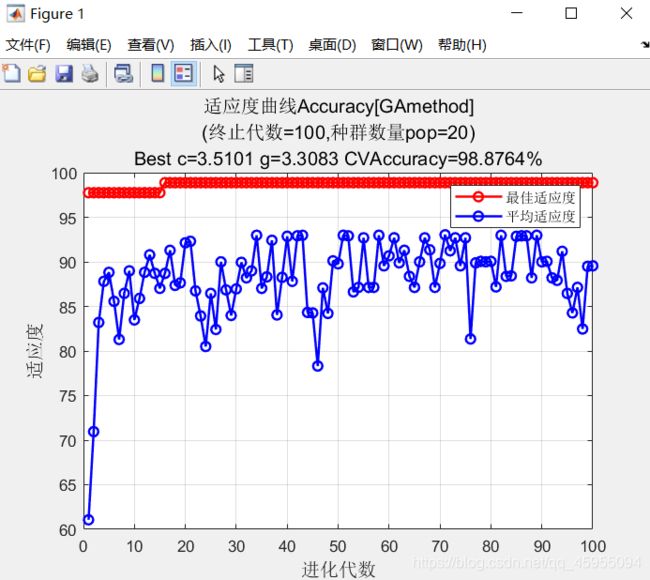
- 遗传算法的收敛曲线和优化后的c、g参数值,交叉验证CV准确率
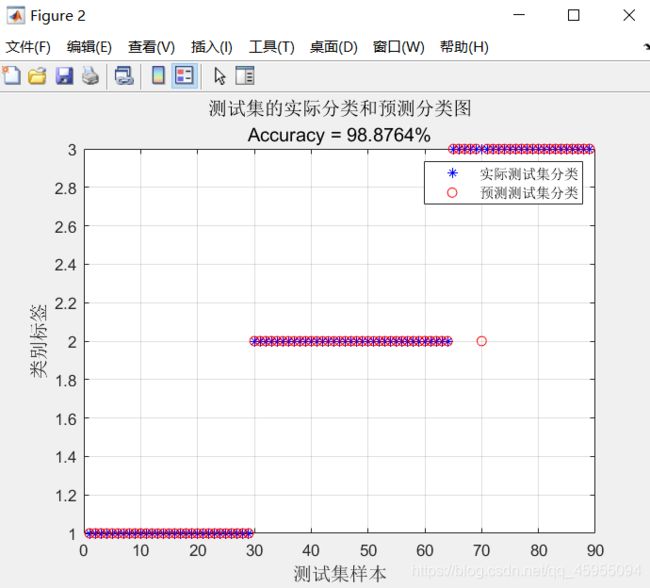
- 遗传算法优化后的实际类型与识别类型对比图像和准确率
3.3 粒子群算法PSO优化SVM
-
粒子群算法的收敛曲线和优化后的c、g参数值,交叉验证CV准确率

-
粒子群算法优化后的实际类型与识别类型对比图像和准确率

3.4 算法结果的对比
| SVM | GA-SVM | PSO-SVM | |
|---|---|---|---|
| 准确率 | 97.7528% | 98.8764% | 98.8764% |
| 收敛代数 | - | 16 | 10 |
对比算法的结果,SVM准确率为97.7528%,遗传算法GA与粒子群算法PSO都起到了一定的优化效果,优化后准确率都是98.8764%。优化时采用的交叉验证方法,降低了结果的偶然性。相较于遗传算法GA,粒子群算法PSO在第10代达到了收敛,收敛后的CV准确率为98.8764%,说明PSO收敛速度更快,在SVM的优化过程中寻优能力(体现为优化速度)也更强。
4. 小结
- 优化的本质是选取准确率最高的时候对应的c、g参数,抓住这点,可以用任意智能优化算法来寻优做对比。
- SVM也可以用来做回归预测,其优化原理与分类一致,都归于使用算法求解两个决策变量+一个目标函数的问题。
利用遗传算法等智能优化算法,优化支持向量机回归预测的设计原理与算法步骤,请参考我的另一篇博客:基于麻雀搜索算法优化的支持向量机回归预测
5. MATLAB代码
以下介绍了常用的支持向量机分类和预测模型及编写相应的代码,相关模型原理和代码见博客主页。
| 支持向量机回归预测模型 |
|---|
| 支持向量机回归预测MATLAB程序 |
| 粒子群算法优化支持向量机回归预测的MATLAB代码 |
| 遗传算法优化支持向量机回归预测的MATLAB代码 |
| 麻雀搜素算法SSA优化支持向量机回归预测的MATLAB代码 |
| 支持向量机分类模型 |
|---|
| 最小二乘支持向量机分类模型 |
| 最小二乘支持向量机分类MATLAB代码 |
| 遗传算法GA优化最小二乘支持向量机分类MATLAB代码 |
| 灰狼优化算法GWO优化最小二乘支持向量机分类MATLAB代码 |
| 支持向量机分类及优化算法模型 |
| 支持向量机分类算法MATLAB代码 |
| 粒子群优化算法PSO优化支持向量机分类MATLAB代码 |
| 遗传算法GA优化支持向量机分类MATLAB代码 |
| 鲸鱼优化算法WOA优化支持向量机分类MATLAB代码 |
| 麻雀搜索算法SSA优化支持向量机分类MATLAB代码 |
| 蝗虫优化算法GOA优化支持向量机分类MATLAB代码 |
| 灰狼优化算法GWO优化支持向量机分类MATLAB代码 |
代码见博客主页