ERNIE: Enhanced Language Representation with Informative Entities中文
文章目录
- ERNIE
-
- 摘要
- 1 引言
- 2 相关工作
- 3 方法论
-
- 3.1 符号
- 3.2 模型架构
- 3.3 K-Encoder
- 3.4 知识注入预训练
- 3.5 针对特定任务的微调
- 4 实验
-
- 4.1 预训练数据集
- 4.2 参数设置和训练细节
- 4.5 GLUE
- 4.6 消融研究
- 5 结论
ERNIE
注:本文为清华和华为的ERNIE模型,百度也有个同名的ERNIE
清华ERNIE原论文
百度ERNIE原论文
摘要
在大规模语料库上预训练的 BERT 等神经语言表示模型可以很好地从纯文本中捕获丰富的语义信息,通过微调以持续提高各种 NLP 任务的性能。然而,现有的预训练语言模型很少考虑融合知识图谱,知识图谱可以提供丰富的结构化知识事实以更好地理解语言。KG 中的信息实体可以增强语言表示。 在本文中,我们利用大规模文本语料库和 KG 来训练增强的语言表示模型(ERNIE),该模型可以同时充分利用词汇、句法和知识信息。 实验结果表明,ERNIE 在各种知识驱动任务上取得了显着的进步,同时在其他常见的 NLP 任务上与最先进的模型 BERT 相当。
1 引言
预训练的语言表示模型,包括基于特征的和微调方法,可以从文本中捕获丰富的语义信息,然后使许多 NLP 任务受益。 BERT通过简单的微调在各种 NLP 任务上获得了SOTA ,包括命名实体识别、问答、自然语言推理和文本分类等。尽管预训练的语言表示模型已经取得了可喜的结果,并且在许多 NLP 任务中作为常规组件发挥了作用,但它们忽略了将知识信息纳入语言理解。 如图 1 所示,在不知道 Blowin’ in the Wind 和 Chronicles: Volume 1 分别是歌曲和书籍的情况下,很难识别 Bob Dylan 在实体输入任务中的两个职业,即词曲作者和作家。 此外,几乎不可能在关系分类任务中提取细粒度的关系,例如作曲家和作者。 对于现有的预训练语言表示模型,这两个句子在句法上是模棱两可的,例如“UNK 在 UNK 中写了 UNK”。 因此,考虑丰富的知识信息可以促成更好的语言理解,有利于各种知识驱动的任务,例如实体识别和关系分类。
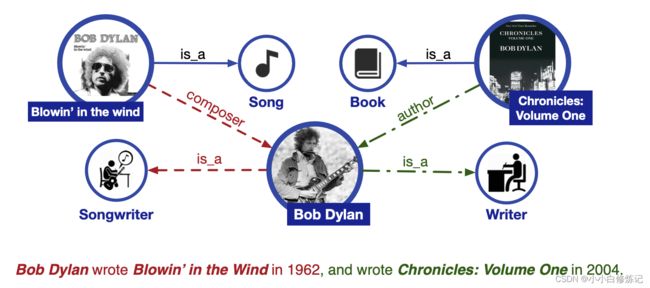
图 1:为语言理解加入额外知识信息的示例。 实线表示现有的知识事实。 红色虚线表示从红色句子中提取的事实。 绿色点划线表示从绿色句子中提取的事实。
为了将外部知识整合到语言表示模型中,有两个主要挑战。
(1) 结构化知识编码:对于给定的文本,对于语言表示模型来说如何有效地提取和编码KG 中相关的信息事实是一个重要问题;
(2)异构信息融合:语言表示的预训练过程与知识表示过程有很大不同,导致两个独立的向量空间。 如何设计一个特殊的预训练目标来融合词法、句法和知识信息是另一个挑战。
为了克服上述挑战,我们提出了具有信息实体的增强语言表示(ERNIE),它在大规模文本语料库和 KG 上预训练了语言表示模型:
(1)为了提取和编码知识信息,我们首先识别文本中提及的命名实体,然后将这些提及到的实体与它们在 KG 中的相应实体对齐。 我们没有直接在 KG 中使用基于图的事实,而是使用诸如 TransE(Bordes 等人,2013)之类的知识嵌入算法对 KG 的图结构进行编码,然后将信息实体嵌入作为 ERNIE 的输入。 基于文本和 KG 之间的对齐,ERNIE 将知识模块中的实体表示集成到语义模块的底层。
(2) 与BERT类似,采用掩码语言模型和下一句预测作为预训练目标。 此外,为了更好地融合文本和知识特征,我们设计了一个新的预训练目标,通过随机mask输入文本中的一些命名实体对齐并要求模型从 KG 中选择合适的实体来完成对齐。 与现有的仅利用局部上下文来预测标记的预训练语言表示模型不同,我们的目标是要求模型聚合上下文和知识事实以预测token和实体,并形成知识增强的语言表示模型。
作者在两个知识驱动的 NLP 任务进行了实验,即实体类型和关系分类。 实验结果表明,通过充分利用词汇、句法和知识信息,ERNIE 在这些知识驱动的任务上显著优于 BERT。
2 相关工作
预训练语言表示模型致力于从文本中捕获语言信息,然后将这些信息用于特定的 NLP 任务。这些预训练方法可以分为两类,即基于特征的方法和微调方法。
早期的工作(Collobert 和 Weston,2008 年;Mikolov 等人,2013 年;Pennington 等人,2014 年)侧重于采用基于特征的方法将词转换为分布式表示。这些预训练的词表示捕获了文本语料库中的句法和语义信息,因此它们通常用作各种 NLP 模型的输入嵌入和初始化参数,相比于随机初始化参数有着显着改进(Turian et al. , 2010)。由于这些词级模型经常受到词多义的影响,(Peters 等人,2018) 进一步采用序列级模型 (ELMo) 来捕获跨不同语言上下文的复杂词特征,并使用 ELMo 生成上下文感知词嵌入。
与仅使用预训练语言表示作为输入特征的基于特征语言模型不同,Dai 和 Le (2015年) 在未标记的文本上训练自编码器,然后使用预训练的模型架构和参数作为其他特定 NLP 模型的起点。 受 Dai 和 Le (2015) 的启发,人们提出了更多用于微调的预训练语言表示模型。 Howard 和 Ruder (2018) 提出了 AWD-LSTM (Merity et al., 2018) 来构建通用语言模型 (ULMFiT)。 拉德福德等人, (2018) 提出了一种生成式预训练 Transformer (Vaswani et al., 2017) (GPT) 来学习语言表示。 德夫林等人。 (2019) 提出了一个具有多层变换器 (BERT) 的深度双向模型,该模型在各种 NLP 任务中取得了SOTA。
尽管基于特征和微调的语言表示模型都取得了巨大的成功,但它们忽略了知识信息的结合。正如最近的工作所证明的那样,注入额外的知识信息可以显着增强原始模型,例如阅读理解(Mihaylov 和 Frank,2018 年;Zhong 等人,2018 年)、机器翻译(Zaremoodi 等人,2018 年)、自然语言推理(Chen 等,2018)、知识获取(Han 等,2018a)和对话系统(Madotto 等,2018)。因此,我们认为额外的知识信息可以有效地使现有的预训练模型受益。事实上,一些工作试图联合词和实体的表征学习以有效利用外部 KG 并取得了可喜的结果(Wang 等人,2014 年;Toutanova 等人,2015 年;Han 等人, 2016;山田等,2016;曹等,2017、2018)。孙等人 (2019) 提出了masked语言模型的知识屏蔽策略,以通过知识来增强语言表示。在本文中,我们进一步利用语料库和 KG 来训练基于 BERT 的增强语言表示模型。
3 方法论
在本节中,我们将介绍 ERNIE 的整体框架及其详细实现,包括第 3.2 节中的模型架构、第 3.4 节中设计用于编码信息实体和融合异构信息的新型预训练任务,以及详细信息 3.5 节中的微调程序。
3.1 符号
我们将标记序列表示为 { w 1 , . . . , w n } \{w_1,...,w_n\} {w1,...,wn},其中 n n n 是token序列的长度。同时,我们将与给定token对齐的实体序列表示为 { e 1 , . . . , e m } \{e_1,...,e_m\} {e1,...,em},其中 m m m 是实体序列的长度。 注意,在大多数情况下 m m m不等于 n n n,因为并非每个token都可以与 KG 中的实体对齐。 此外,我们将包含所有标记的整个词汇表表示为 V V V,将包含 KG 中所有实体的实体列表表示为 E E E。如果标记 w ∈ V w ∈ V w∈V 有相应的实体 e ∈ E e ∈ E e∈E,则它们的对齐定义为 f ( w ) = e f( w) = e f(w)=e。在本文中,我们将实体与其命名实体短语中的第一个标记对齐,如图 2 所示。
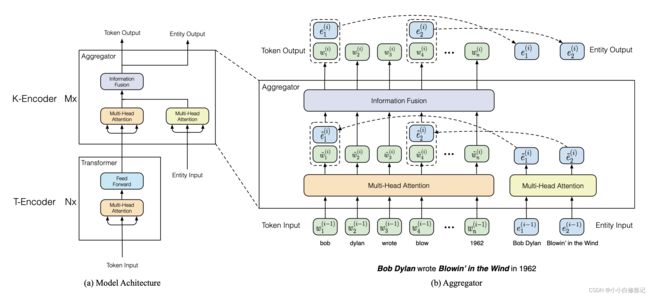
图2 左边是ERNIE的架构。 右边是 token 和 entity 的输入相互集成的聚合器。 信息融合层有两种输入:一种是 t o k e n e m b e d d i n g token\ embedding token embedding,另一种是 t o k e n e m b e d d i n g token\ embedding token embedding和 e n t i t y e m b e d d i n g entity\ embedding entity embedding的串联。 信息融合后,它为下一层输出新的 t o k e n e m b e d d i n g token\ embedding token embedding和 e n t i t y e m b e d d i n g entity\ embedding entity embedding。
3.2 模型架构
如图 2 所示,ERNIE 的整个模型架构由两个堆叠模块组成:
(1)底层文本编码器(T-Encoder)负责从输入标记中捕获基本的词汇和句法信息;
(2)上层知识编码器 (K-Encoder) 负责将额外的面向 token 的知识信息整合到来自底层的文本信息中,以便我们可以将 token 和实体的异构信息表示到一个统一的特征空间中。 此外,我们将 T-Encoder 层数表示为 N N N,将 K-Encoder 层数表示为 M M M。(后面会介绍,在实验中作者其实是让 M = N M=N M=N)
具体来说,给定一个token序列 { w 1 , . . . , w n } \{w_1,...,w_n\} {w1,...,wn},及其对应的实体序列 { e 1 , . . . , e m } \{e_1 , . . . , e_m \} {e1,...,em},文本编码器首先对每个token的 t o k e n e m b e d d i n g , s e g m e n t e m b e d d i n g , p o s i t i o n a l e m b e d d i n g token\ embedding,segment\ embedding, positional\ embedding token embedding,segment embedding,positional embedding求和以计算其 i n p u t e m b e d d i n g input\ embedding input embedding,然后计算 { w 1 , . . . , w n } \{\pmb{w}_1,...,\pmb{w}_n\} {www1,...,wwwn} (加粗表示向量或者矩阵)如下,
{ w 1 , . . . , w n } = T − E n c o d e r ( { w 1 , . . . , w n } ) ( 1 ) \{\pmb{w}_1,...,\pmb{w}_n\}=T-Encoder(\{w_1,...,w_n\})(1) {www1,...,wwwn}=T−Encoder({w1,...,wn})(1)其中, T − E n c o d e r ( ⋅ ) T-Encoder(·) T−Encoder(⋅) 是一个多层双向Transformer,这里的 T − E n c o d e r ( ⋅ ) T-Encoder(·) T−Encoder(⋅)与 BERT 中的实现相同。
在计算 { w 1 , . . . , w n } \{\pmb{w}_1,...,\pmb{w}_n\} {www1,...,wwwn}, ERNIE 采用知识编码器 K − E n c o d e r K-Encoder K−Encoder将知识信息注入语言表示。 具体而言,我们用实体嵌入 { e 1 , . . . , e m } \{\pmb{e}_1 , . . . , \pmb{e}_m\} {eee1,...,eeem}表示实体 { e 1 , . . . , e m } \{e_1 , . . . , e_m \} {e1,...,em}, 本文通过高效的知识嵌入模型 TransE (Bordes 等人,2013 年)进行预训练得到实体embedding。然后, 将和 { w 1 , . . . , w n } \{\pmb{w}_1,...,\pmb{w}_n\} {www1,...,wwwn} { e 1 , . . . , e m } \{\pmb{e}_1 , . . . , \pmb{e}_m\} {eee1,...,eeem}喂给K-Encoder,目的是融合异构信息和计算最终的 o u t p u t e m b e d d i n g output \ embedding output embedding,
{ w 1 o , . . . , w n o } , { e 1 o , . . . , e n o } = K − E n c o d e r ( { w 1 , . . . , w n } , { e 1 , . . . , e m } ) ( 2 ) \{\pmb{w}_1^o,...,\pmb{w}_n^o\},\{\pmb{e}_1^o,...,\pmb{e}_n^o\}= K-Encoder(\{\pmb{w}_1,...,\pmb{w}_n\} ,\{\pmb{e}_1 , . . . , \pmb{e}_m\})(2) {www1o,...,wwwno},{eee1o,...,eeeno}=K−Encoder({www1,...,wwwn},{eee1,...,eeem})(2) { w 1 o , . . . , w n o } 和 { e 1 o , . . . , e n o } \{\pmb{w}_1^o,...,\pmb{w}_n^o\}和\{\pmb{e}_1^o,...,\pmb{e}_n^o\} {www1o,...,wwwno}和{eee1o,...,eeeno}将作为特征用于特定的任务,详细部分在3.3。
3.3 K-Encoder
如图2所示,K-Encoder 由多个堆叠的聚合器组成,旨在编码tokens 和实体以及融合他们的异构信息。 在第 i i i个聚合器中,将来自前面的聚合器的 i n p u t t o k e n e m b e d d i n g { w 1 ( i − 1 ) , . . . , w n ( i − 1 ) } input\ token\ embedding\ \{\pmb{w}_1^{(i-1)},...,\pmb{w}_n^{(i-1)}\} input token embedding {www1(i−1),...,wwwn(i−1)}和 e n t i t y e m b e d d i n g entity\ embedding entity embedding { e 1 ( i − 1 ) , . . . , e m ( i − 1 ) } \{\pmb{e}_1^{(i-1)},...,\pmb{e}_m^{(i-1)}\} {eee1(i−1),...,eeem(i−1)} 分别输入两个多头自注意力(MH-ATTs)(Vaswani 等人,2017),
w ~ 1 ( ) , ⋯ , w ~ ( ) = − ( w 1 ( − 1 ) , ⋯ , w ( − 1 ) ) e ~ 1 ( ) , ⋯ , e ~ ( ) = − ( e 1 ( ) , ⋯ , e ( ) ) ( 3 ) {\tilde{\pmb{w}} _1^{()},⋯,\tilde{\pmb{w}} _^{()} }=−({\pmb{w}_1^{(−1)},⋯,\pmb{w}_^{(−1)} })\\ {\tilde{\pmb{e}} _1^{()},⋯,\tilde{\pmb{e}} _^{()} }=−({\pmb{e}_1^{()},⋯,\pmb{e}_^{()} })(3) www~1(i),⋯,www~n(i)=MH−ATT(www1(i−1),⋯,wwwn(i−1))eee~1(i),⋯,eee~m(i)=MH−ATT(eee1(i),⋯,eeem(i))(3)第 i i i个聚合器采用信息融合层对token和实体序列进行相互集成,并计算每个token和实体的 o u t p u t e m b e d d i n g output \ embedding output embedding。 对于一个token w j w_j wj及其对齐的实体 e k = f ( w j ) e_k = f (w_j ) ek=f(wj),信息融合过程如下,
h = σ ( W ~ ( ) w ~ ( ) + W ~ ( ) e ~ ( ) + b ~ ( ) ) ( ) = σ ( W ( ) h + b ( ) ) ( ) = σ ( W ( ) h + b ( ) ) ( 4 ) ℎ_=\sigma(\tilde{\pmb{W}}_^{()} \tilde{\pmb{w}}_^{()}+\tilde{\pmb{W}}_^{()} \tilde{\pmb{e}}_^{()}+\tilde{\pmb{b}}^{()} )\\ _^{()}={\sigma}(\pmb{W}_^{()} \pmb{h}_+\pmb{b}_^{()})\\ _^{()}={\sigma}(\pmb{W}_^{()} \pmb{h}_+\pmb{b}_^{()})(4) hj=σ(WWW~t(i)www~j(i)+WWW~e(i)eee~k(i)+bbb~(i))wj(i)=σ(WWWt(i)hhhj+bbbt(i))ek(i)=σ(WWWe(i)hhhj+bbbe(i))(4)其中, 中间隐藏状态 h j \pmb{h}_j hhhj 集成了token和实体信息。 σ ( ⋅ ) \sigma(·) σ(⋅)是非线性激活函数,通常是 GELU 函数 (Hendrycks and Gimpel, 2016)。
对于句子中的某些token,它在KG中没有对应实体,信息融合层计算 o u t p u t e m b e d d i n g output \ embedding output embedding如下,
h = σ ( W ~ ( ) w ~ ( ) + b ~ ( ) ) ( ) = σ ( W ( ) h + b ( ) ) ( 5 ) ℎ_=\sigma(\tilde{\pmb{W}}_^{()} \tilde{\pmb{w}}_^{()}+\tilde{\pmb{b}}^{()} )\\ _^{()}={\sigma}(\pmb{W}_^{()} \pmb{h}_+\pmb{b}_^{()})(5) hj=σ(WWW~t(i)www~j(i)+bbb~(i))wj(i)=σ(WWWt(i)hhhj+bbbt(i))(5)
综上,第 i i i个聚合器可简单表示为,
{ w 1 ( ) , ⋯ , w n ( ) } , { e 1 ( ) , ⋯ , e m ( ) } = A g g r e g a t o r ( { w 1 ( − 1 ) , ⋯ , w n ( − 1 ) } , { e 1 ( − 1 ) , ⋯ , e m ( − 1 ) } ) ( 6 ) \{\pmb{w}_1^{()},⋯,\pmb{w}_n^{()} \},\{\pmb{e}_1^{()},⋯,\pmb{e}_m^{()} \}=Aggregator(\{\pmb{w}_1^{(-1)},⋯,\pmb{w}_n^{(-1)} \},\{\pmb{e}_1^{(-1)},⋯,\pmb{e}_m^{(-1)} \})(6) {www1(i),⋯,wwwn(i)},{eee1(i),⋯,eeem(i)}=Aggregator({www1(i−1),⋯,wwwn(i−1)},{eee1(i−1),⋯,eeem(i−1)})(6)
由顶层聚合器计算的token和实体的 o u t p u t e m b e d d i n g output \ embedding output embedding将用作 K − E n c o d e r K-Encoder K−Encoder 的最终 o u t p u t e m b e d d i n g output \ embedding output embedding。
3.4 知识注入预训练
为了将实体知识注入到语言表示模型中,我们提出了一个新的预训练任务,随机mask一些 t o k e n − e n t i t y token-entity token−entity对齐,然后要求模型基于对齐的token来预测所有相应的实体。由于我们的任务类似于训练去噪自编码器,我们将此过程称为去噪实体自编码器 (dEA)。 考虑到 s o f t m a x softmax softmax 层的 ϵ \epsilon ϵ 非常大,因此只需要根据给定的实体序列而不是 KG 中的所有实体来预测实体。给定token序列 { w 1 , . . . , w n } \{w_1, . . . , w_n\} {w1,...,wn}及其对应的实体序列 { e 1 , . . . , e m } \{e_1, . . . , e_m\} {e1,...,em},我们定义token w i w_i wi 的对齐实体分布如下,
( e j │ w i ) = e x p ( ( w ) ⋅ e j ) / ( ∑ = 1 e x p ( ( w ) ⋅ e k ) ( 7 ) (e_j│w_i )={exp((\pmb{w}_^ )·\pmb{e}_j)}/(∑_{=1}^{exp((\pmb{w}_^ )·\pmb{e}_k})(7) p(ej│wi)=exp(linear(wwwio)⋅eeej)/(k=1∑mexp(linear(wwwio)⋅eeek)(7)其中 l i n e a r ( ⋅ ) linear(·) linear(⋅)是一个线性层。 计算 dEA 的交叉熵损失函数会用到公式7。
考虑到 token-entity 对齐存在一些错误,对 dEA 执行以下操作:
(1) 对于给定的 token-entity 对齐,以 5 % 5\% 5%的概率用另一个随机实体替换该实体,旨在训练模型能够纠正token与错误实体对齐这个错误;
(2)以 15 % 15\% 15%的概率mask掉token-entity 对齐,旨在训练模型以纠正实体对齐系统未提取所有现有对齐的错误;
(3)以 80 % 80\% 80%的概率保持 token-entity 对齐不变,旨在鼓励模型将实体信息整合到 token 表示中,以获得更好的语言理解。
与 BERT 类似,ERNIE 也采用掩码语言模型 (MLM) 和下一句预测 (NSP) 作为预训练任务,使 ERNIE 能够从文本中的标记中捕获词汇和句法信息,整体预训练损失是 dEA、MLM 和 NSP 损失的总和。
3.5 针对特定任务的微调
如图 3 所示,对于各种常见的 NLP 任务,ERNIE 可以采用类似于 BERT 的微调过程。我们可以将第一个token的最终输出嵌入,它对应于特殊的 [CLS] 标记,作为特定任务的输入序列的表示。对于一些知识驱动的任务(例如,关系分类和实体类型),我们设计了特殊的微调程序:
对于关系分类,该任务需要系统根据上下文对给定实体对的关系标签进行分类。针对关系分类最直接的方法微调ERNIE 是将池化层应用于给定实体提及的最终输出嵌入,并用它们的提及嵌入的串联来表示给定实体对以进行分类。在本文中,我们设计了另一种方法,通过添加两个标记标记来突出实体提及来修改输入标记序列。这些额外的标记标记在传统的关系分类模型(Zeng et al., 2015)中扮演着类似于位置嵌入的角色。然后,我们还采用 [CLS] 标记嵌入进行分类。请注意,我们分别为头部实体和尾部实体设计了不同的令牌 [HD] 和 [TL]。
实体类型的特定微调过程是关系分类的简化版本。由于以前的识别模型充分利用了上下文嵌入和实体提及嵌入(Shimaoka 等人,2016 年;Yaghoobzadeh 和 Schu ̈tze,2017 年;Xin 等人,2018 年),我们认为修改后的输入序列与提及mark token [ENT] 可以引导 ERNIE 将上下文信息和实体提及信息仔细结合起来。

图 3:修改特定任务的输入序列。 为了在不同类型的输入之间对齐token,我们使用虚线矩形作为占位符。 彩色矩形表示特定的标记token。
4 实验
在本节中,我们将介绍预训练 ERNIE 的细节以及在五个 NLP 数据集上的微调结果,其中包含知识驱动的任务和常见的 NLP 任务。
4.1 预训练数据集
鉴于从头训练 ERNIE 的巨大成本,采用 Google发布的 BERT 参数来初始化用于编码token的Transformer 块。由于预训练是一个由 NSP、MLM 和 dEA 组成的多任务过程,我们使用英文维基百科作为我们的预训练语料库并将文本与 Wiki 数据对齐。将语料库转换为格式化数据进行预训练后,标注输入有近 4 , 500 M 4,500M 4,500M子词和 140 M 140M 140M实体,丢弃少于3个实体的句子。
在预训练 ERNIE 之前,我们采用 TransE 在 Wikidata 上训练的知识嵌入作为实体的输入嵌入。具体来说,我们对包含 5 , 040 , 986 5,040,986 5,040,986 个实体和 24 , 267 , 796 24,267,796 24,267,796 个事实三元组的 Wikidata 部分进行采样。训练时实体嵌入是固定的,实体编码模块的参数都是随机初始化的.
4.2 参数设置和训练细节
定 t o k e n e m b e d d i n g token\ embedding token embedding 和 e n t i t y e m b e d d i n g entity\ embedding entity embedding的隐藏维度分别表示为 H w H_w Hw、 H e H_e He,自注意力头的数量分别表示为 A w A_w Aw、 A e A_e Ae。 模型大小: N = 6 , M = 6 N = 6,M = 6 N=6,M=6, H w = 768 H_w = 768 Hw=768, H e = 100 , A w = 12 , A e = 4 H_e = 100,A_w = 12,A_e = 4 He=100,Aw=12,Ae=4。总参数约 114 M 114M 114M。
B E R T B A S E BERT_{BASE} BERTBASE 的参数总量约为 110 M 110M 110M,这意味着 ERNIE 的知识模块比语言模块小得多,对运行时性能影响很小。 并且,我们在带注释的语料库上仅预训练 ERNIE一个epoch。 由于自注意力的计算是长度的二次函数,为了加速训练过程,我们将最大序列长度从 512 减少到 256。 为了使batch中的token数量与 BERT 相同,我们将batch大小加倍到 512。除了将学习率设置为 5 e − 5 5e^{−5} 5e−5 之外,我们主要遵循 BERT 中使用的预训练超参数。 对于微调,大多数超参数与预训练相同,除了batch size,学习率和训练周期数。 我们发现以下可能值范围在带有黄金注释的训练数据集上效果很好,即batch size:32,学习率(Adam): 5 e − 5 5e^{−5} 5e−5、 3 e − 5 3e^{−5} 3e−5、 2 e − 5 2e^{−5} 2e−5,epoch数量:3 到 10.
我们还在远程监督的数据集上评估 ERNIE,即FIGER(Ling et al., 2015)。 由于深度堆叠的 Transformer 块的强大表达能力,我们发现小批量会导致模型过拟合。 因此,我们使用更大的批次大小和更少的训练时期来避免过度拟合,并保持学习率的范围不变,即batch size:2048,epoch:2、3。
由于大多数数据集没有实体注释,我们使用 TAGME(Ferragina 和 Scaiella,2010)来提取句子中的实体提及并将它们链接到 KG 中的相应实体。
4.5 GLUE
通用语言理解评估 (GLUE) 基准(Wang 等人,2018 年)是各种自然语言理解任务的集合(Warstadt 等人,2018 年;Socher 等人,2013 年;Dolan 和 Brockett,2005 年;Agirre等人,2007;Williams 等人,2018 年;Rajpurkar 等人,2016 年;Dagan 等人,2006 年;Levesque 等人,2011 年),这是 Devlin 等人使用的主要基准 (2019)。为了探索我们知识编码器模块是否会降低常见 NLP 任务的性能,我们在 8 个 GLUE 数据集上评估 ERNIE,并将其与 BERT 进行比较。
在表 6 中,我们报告了我们的评估提交结果和排行榜中 BERT 的结果。我们注意到 ERNIE 在 MNLI、QQP、QNLI 和 SST-2 等大数据集上与 BERTBASE 一致。结果在小数据集上变得更加不稳定,即 ERNIE 在 CoLA 和 RTE 上更好,但在 STS-B 和 MRPC 上更差。

简而言之,ERNIE 在 GLUE 上取得了与 BERTBASE 相当的结果。一方面,这意味着 GLUE 不需要外部知识来进行语言表示。另一方面,它说明了 ERNIE 在异构信息融合后不会丢失文本信息。
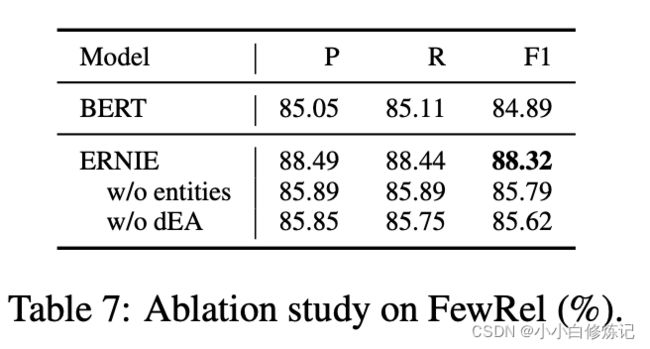
4.6 消融研究
在本小节中,我们使用FewRel 数据集探索信息实体和知识性预训练任务(dEA)对ERNIE 的影响。 w/o entity 和 w/o dEA 分别指微调 ERNIE没有实体序列输入和没有预训练任务 dEA。 如表 7 所示,我们有以下观察结果:(1)在没有实体序列输入的情况下,dEA 在预训练期间仍然将知识信息注入语言表示中,这使 BERT 的 F1 分数提高了 0.9%。 (2)虽然信息实体带来了很多知识信息,直观地有利于关系分类,但没有 dEA 的 ERNIE 几乎没有利用这一点,导致 F1 增加了 0.7%。
5 结论
在本文中,我们提出了将知识信息整合到语言表示模型中的ERNIE模型。 我们提出了知识丰富的聚合器和预训练任务 dEA,以更好地融合来自文本和 KG 的异构信息。 实验结果表明,ERNIE 在去噪远程监督数据和对有限数据进行微调方面都比 BERT 更好。 未来的研究还有三个重要方向:(1)将知识注入基于特征的预训练模型,如 ELMo(Peters 等,2018);(2) 将多样化的结构化知识引入到不同于世界知识数据库 Wikidata 的 ConceptNet (Speer and Havasi, 2012) 等语言表示模型中; (3) 启发式地注释更多真实世界的语料库以构建更大的预训练数据。 这些方向可能会导致更一般和更有效的语言理解。
本文图片和表格均来自Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced Language Representation with Informative Entities[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1441-1451.