EnlightenGAN: Deep Light Enhancement without Paired Supervision
参考EnlightenGAN: Deep Light Enhancement without Paired Supervision - 云+社区 - 腾讯云
摘要
基于深度学习的方法在图像恢复和增强方面取得了显著的成功,但在缺乏成对训练数据的情况下,它们是否仍然具有竞争力? 作为一个例子,本文探讨了弱光图像增强问题,在实践中,它是非常具有挑战性,必须同时采取配对的弱光照片和正常的光场景照片。我们提出了一种高效的、无监督的生成对抗网络,称为EnlightenGAN,它可以在不需要低/正态光图像对的情况下进行训练,并被证明在各种真实世界的测试图像上具有很好的通用性。替代使用ground truth数据监督学习,我们建议调整未配对的训练使用从输入中提取的信息本身,和基准的一系列创新的低光照条件下的图像增强问题,包括全局局部鉴别器结构,self-regularized感知损失融合和注意力机制。通过大量的实验,我们提出的方法在视觉质量和主观用户研究方面的各种指标下优于最近的方法。

1、简介
在弱光条件下拍摄的图像对比度低,能见度差,ISO噪声大。这些问题不仅挑战了偏好高能见度图像的人类视觉感知,也挑战了大量依赖于计算机视觉算法的智能系统,如全天候自动驾驶和生物识别。为了减轻这种退化,人们提出了大量的算法,从直方图或基于认知的算法到基于学习的方法。使用深度学习的最先进的图像恢复和增强方法很大程度上依赖于合成或捕获的损坏和干净的图像对进行训练,如超分辨率,去噪和去模糊。
然而,成对训练图像的可用性的假设带来了更多的困难,在增强图像更不受控制的场景,如无雾、去雨或光线暗的改进:1)、同时捕获损坏和ground-truth图像相同的视觉场景非常困难甚至是不切实际的(例如,光线和普通光照图像对在同一时间);2)、从干净的图像中合成损坏的图像有时会有所帮助,但这样的合成结果通常不够逼真,当训练好的模型应用于真实世界的弱光图像时,会导致各种伪影;3)、针对弱光增强问题,对于一个弱光图像,可能没有唯一的或明确定义的正常光标签。例如,任何从黎明到黄昏拍摄的照片都可以被视为在午夜同一场景拍摄的照片的高亮版本。考虑到上述问题,我们的首要目标是增强光线条件随空间变化和曝光过度/不足的弱光照片,而成对的训练数据是不可获得的。
受无监督图像到图像转换的启发,我们采用生成对抗网络(GANs)在低光和正常光图像空间之间建立非配对映射,而不依赖于精确配对的图像。这将我们从仅使用合成数据或在受控设置中获取的有限的真实配对数据的训练中解放出来。我们引入了一种轻量级但有效的单路径GAN,名为EnlightenGAN,它没有像之前的作品那样使用循环一致性,因此训练时间更短。
由于缺乏配对的训练数据,我们结合了一些创新的技术。我们首先提出一种双鉴别器来平衡全局和局部弱光增强。此外,由于缺乏ground-truth监督,提出了一种self-regularized perceptual loss来约束弱光输入图像与其增强图像之间的特征距离,并与对抗性损失一起局部和全局采用该self-regularized perceptual loss来训练EnlightenGAN。我们还提出利用低光输入的照度信息作为深度特征每一层的自规则化注意图来规范无监督学习。由于无监督设置,我们证明了EnlightenGAN可以很容易的被用来增强来自不同域的图像。
- EnlightenGAN是第一个成功地将非配对训练引入弱光图像增强的工作。这样的训练策略消除了对成对训练数据的依赖,使我们能够训练来自不同领域的更大种类的图像。它还避免了过度拟合任何特定的数据生成协议或成像设备,以前的工作隐含地依赖,因此显著改善了现实世界的泛化。
- 通过引入:(1)处理输入图像中空间变化的光条件的全局和局部鉴别器结构,EnlightenGAN获得了显著的性能;(2)self-regularization的方法,由self preserving loss和自我正则化的注意机制共同实现。自我规范化对我们的模型的成功至关重要,因为在非配对的环境中,没有强大的外部监督形式可用。
- 通过实验,将EnlightenGAN与几种先进的方法进行了比较。结果是衡量的视觉质量,无参考图像质量评估和人的主观调查。所有的结果都一致表明了EnlightenGAN的优越性。更重要的是,与现有的成对训练增强方法相比,EnlightenGAN被证明特别容易和灵活,以适应增强来自不同领域的现实世界的低光图像。
2、相关工作
A、配对数据集
有几种方法可以收集成对的低/正常光图像数据集,但不幸的是,没有一种方法是有效的,也不容易扩展。可以固定相机,然后在正常光条件下减少曝光时间,在弱光条件下增加曝光时间。LOL数据集是目前为止唯一通过改变曝光时间和ISO从真实场景中获取的低/正常光图像对数据集。由于实验设置繁琐,例如相机需要固定,物体不能移动等,它只有500对。此外,它可能仍然偏离自然低/正常光图像之间的真实映射。特别是在空间变化的光线下,简单地增加/减少曝光时间可能会导致局部曝光过/过少的伪影。
在高动态范围(HDR)领域,一些工作首先在不同的不完美光线条件下捕获几张图像,然后将它们对齐并融合成一张高质量的图像。然而,他们的设计目的不是为了后处理只有一个单一的微光图像。
B、传统方法
长期以来,弱光图像的图像增强作为一个图像处理问题得到了积极的研究,一些经典的方法如自适应直方图均衡,Retinex和多尺度Retinex模型。最近,Shuhang Wang等人提出了一种针对非均匀光照图像的增强算法,利用双对数变换来平衡细节和自然度。Fu等人在前人对对数变换研究的基础上。提出了一种加权变分模型,用于从带有正则化项的观测图像中估算反射率和照度。Xiaojie Guo等人提出了一种简单有效的弱光图像增强算法(LIME),该算法首先通过在每个像素的RGB通道中寻找最大的光照值来估计每个像素的光照,然后通过施加一个先验结构来构造光照图。Xutong Rend等人通过对连续图像序列的分解,引入了联合微光图像增强去噪模型。Mading Li等人进一步提出了一种鲁棒的Retinex模型,与传统的Retinex模型相比,该模型额外考虑了噪声映射,以提高增强带有强烈噪声的微光图像的性能。
C、基于深度学习的方法
现有的深度学习解决方案大多依赖于配对训练,即大多数弱光图像是由正常图像合成的。K. Lore等人提出了一种堆叠自动编码器(LL-Net)来学习patch级别的联合去噪和微光增强。C. Wei等人提供了一个端到端的框架Retinex- net,将Retinex理论与深度网络相结合。HDR-Net融合了深度网络与双边网格处理和局部仿射颜色变换的思想,并带有成对监督。在HDR领域发展了一些多帧微光增强方法。
最近,C. Chen提出了一种“学会在黑暗中看东西”的模型,该模型获得了令人印象深刻的视觉效果。但是,该方法除了需要对低/正态光训练图像进行配对外,还直接对原始传感器数据进行操作。另外,通过学习色彩变换、去噪和去噪的通道,更注重避免微光增强过程中被放大的伪影,这在设置和目标上与EnlightenGAN有所不同。
D、对抗学习的方法
GANs已被证明在图像合成和翻译方面是成功的。在将GAN应用于图像的恢复和增强时,现有的工作大多也是使用成对的训练数据,如超分辨率、单幅图像去模糊、去噪、去雾等。提出了几种非监督GANs来学习域间映射的对抗式学习,并将其应用于许多其他任务。参考文献通过采用非配对数据的循环一致性损失,CycleGAN采用两路GAN在两个域之间进行翻译。最近少量的工作跟随了CyclyGAN的思想,采用非配对数据的循环一致性,解决了若干底层视觉任务,例如去雾,去雨,超分和运动图像增强。与之不同的是EnlightenGAN指的是非配对训练,但是采用一个轻量的单路径GAN结构(没有训练一致性),这使得训练更加稳定和简单。 
3、方法
如上图2所示,本文提出的方法采用注意力引导的U网作为生成器,使用双鉴别器来引导全局和局部信息。也使用自特征保留损失来指导训练过程,并保持纹理和结构。在本节中,我们首先介绍两个重要的构建模块,全局-局部鉴别器和self-regularized perceptual loss,然后对整个网络进行详细分析。详细的网络架构在补充资料中。
3.1、全局局部鉴别器
采用对抗性损失来最小化实际光和输出正态光分布之间的距离。然而,我们观察到一个图像级的初始鉴别器经常失败的空间变化的光图像;如果输入图像有一些局部区域需要进行不同于其他部分的增强,例如整个黑暗背景中的一小块明亮区域,单靠全局图像鉴别器往往无法提供所需的自适应能力。
为了自适应地增强局部区域,同时改善全局的光照,我们提出了一种新的全局-局部鉴别器结构,两者都使用PatchGAN进行真假鉴别。除了图像级的全局鉴别器,我们还添加了一个局部鉴别器,通过从输出和真实正态光图像中随机提取局部patch,并学习区分它们是真实的还是假的。这种全局-局部结构确保了增强图像的所有局部斑块看起来都像真实的正常光,这被证明是避免局部曝光过度或曝光不足的关键,我们的实验将在后面揭示。
此外,对于全局鉴别器,我们利用最近提出的相对论鉴别器结构[35]来估计真实数据比假数据更真实的概率,并指导生成器合成比真实数据更真实的假图像。相对鉴别器的函数为:
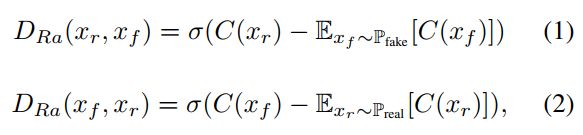
式中,C为鉴别器网络,和分别从真分布和假分布中采样, 表示sigmoid函数。我们对相对鉴别器作了轻微的修改,用最小二乘GAN (LSGAN损失代替了s型函数。最后,全局鉴别器D和生成器G的损失函数为:
表示sigmoid函数。我们对相对鉴别器作了轻微的修改,用最小二乘GAN (LSGAN损失代替了s型函数。最后,全局鉴别器D和生成器G的损失函数为:
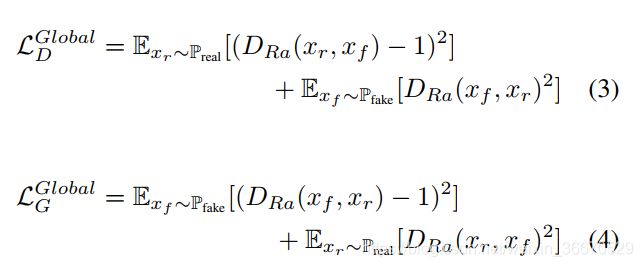
对于局部鉴别器,每次从输出图像和真实图像中随机裁剪5个patch。这里我们采用原LSGAN作为对抗性损失,如下:

3.2、自特征保持损失
为了约束感知相似性,Johnson等人提出了感知损失,采用预先训练好的VGG来建模图像之间的特征空间距离,该方法被广泛应用于许多低级视觉任务。通常的做法是限制提取的特征与输出图像的ground truth之间的距离。
在我们的非配对设置中,我们建议限制输入弱光和增强的正常光输出之间的VGG特征距离。这是基于我们的实际观察,当我们操纵输入像素强度范围时,VGG模型的分类结果不是很敏感,这与最近另一项研究的观点一致。我们称其为self-regularized perceptual loss,以强调其自正则化的效用,在增强前后保留图像内容特征。这不同于感知损失在(成对的)图像恢复中的典型用法,也来自我们的非成对设置。具体而言,self-regularized perceptual loss 定义为:
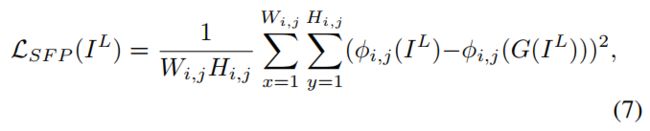
式中,为输入弱光图像,![]() 为发生器增强输出。表示从ImageNet上预训练的VGG16模型中提取的特征图。i表示第i个最大池化层,j表示第i个最大池化层之后的第j个卷积层。
为发生器增强输出。表示从ImageNet上预训练的VGG16模型中提取的特征图。i表示第i个最大池化层,j表示第i个最大池化层之后的第j个卷积层。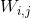 和
和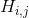 为提取的特征图的维数。默认情况下,我们选择
为提取的特征图的维数。默认情况下,我们选择![]() 。
。
对于我们的局部鉴别器,从输入和输出图像中裁剪出的局部小块也通过相似定义的自特征保持损失进行正则化。此外,我们在VGG特征图之后添加实例归一化层,然后再输入和,以稳定训练。EnlightenGAN的整体损失函数为:
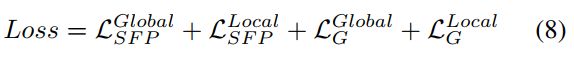
3.3、U-Net Generator Guided with Self-Regularized Attention
U-Net在语义分割、图像恢复和增强方面取得了巨大的成功。通过从不同深度层中提取多层次的特征,U-Net保留了丰富的纹理信息,利用多尺度的上下文信息合成高质量的图像。
我们采用U-Net作为我们的生成器骨干网络。我们进一步为U-Net提出了一个易于使用的注意机制网络。直观地说,在光线空间变化的弱光图像中,我们总是希望增强暗区而不是亮区,这样输出的图像既不会曝光过度也不会曝光不足。我们取输入RGB图像的光照通道I,将其归一化为[0,1],然后使用1到I(元素间的差异)作为我们的自正则化注意力图。然后我们调整注意力地图的大小以适应每个特征地图,并将其与所有中间特征地图以及输出图像相乘。我们强调,我们的注意力地图也是一种自我正规化的形式,而不是通过监督来学习的。尽管它很简单,但注意力指南始终如一地提高了视觉质量。
我们的注意力引导U-Net生成器是由8卷积块实现的。每个块由两个3×3的卷积层组成,其次是LeakyReLu和批处理归一层[42]。在上采样阶段,我们将标准反卷积层替换为一个双线性上采样层加上一个卷积层,以减少棋盘效应。最终的EnlightenGAN架构如图2所示。详细的配置可以在补充资料中找到。
4、实验
4.1、数据集和实现细节
由于EnlightenGAN具有独特的低/正常光未配对训练能力,我们可以收集更大范围的未配对训练集,涵盖不同的图像质量和内容。我们从和[发布的几个数据集中收集了914张弱光图像和1016张普通光图像,不需要保留任何一对。手动检查和选择以去除中等亮度的图像。所有这些照片都转换为PNG格式,并调整为600×400像素。对于测试图像,我们选择之前工作中使用的标准图像(NPE , LIME, MEF, DICM, VV2等)。
EnlightenGAN首先从零开始训练100 epoch,学习速率为1e-4,其次是单路GAN的轻量级设计,没有使用循环一致性,训练时间比基于循环的方法短得多。整个训练过程在3个Nvidia 1080Ti GPU上花费3个小时。100个epoch与学习速率线性衰减到0。我们使用Adam优化器,批处理大小设置为32。

4.2、消融研究
为了证明第3节中提出的每个部件的有效性,我们进行了几个消融实验。具体来说,我们设计了两个实验,分别去掉了局部鉴别器和注意机制的组成部分。如图3所示,第一行显示输入图像。第二行是只有全局鉴别器来区分弱光和正常光图像的EnlightenGAN制作的图像。第三行是未采用自我规范注意机制,使用U-Net作为生成器的EnlightenGAN的结果。最后一行是我们提议的EnlightenGAN版本。
增强的结果在第二行和第三行往往包含局部地区严重的颜色失真或曝光不足,也就是说,天空在建筑图3(一个),屋顶地区图3 (b),左边在图3开花(c),树和灌木的边界图3 (d)和图3的T恤(e)。相比之下,充分EnlightenGAN的结果色彩逼真,视觉上更令人愉悦,验证了全局-局部鉴别器设计和自我规范的注意机制的有效性。更多的图像在补充材料。
4.3、和最先进方法的比较
在这一节中,我们比较了EnlightenGAN的性能与目前的最先进的方法。我们进行了一系列的实验,包括视觉质量比较,人的主观评价和无参考图像质量评估(IQA),下面将详细阐述。
4.3.1、视觉质量对比
我们首先比较了EnlightenGAN的视觉质量与几个最近竞争的方法。结果如图4所示,第一列是原始的弱光图像,第二列到第五列是用我们的非配对训练集训练的RetinexNet、RetinexNet、SRIE、LIME和NPE增强的图像。最后一栏显示的结果产生的EnlightenGAN。
接下来我们放大一些边界框的细节。LIME容易产生过度曝光伪影,使结果失真、刺眼,并丢失部分信息。SRIE和NPE的结果通常比其他的要暗一些。CycleGAN和RetinexNet在亮度和自然度方面都不能令人满意的视觉结果。相比之下,EnlightenGAN不仅成功地学会了增强暗区,还保留了纹理细节,避免了过度曝光的伪影。更多的结果在补充资料中显示。
4.3.2、人类的主观评价
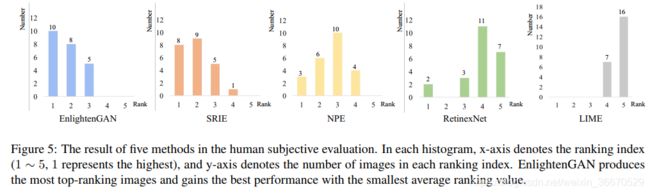
我们进行了人的主观研究,比较了EnlightenGAN和其他方法的性能。我们从测试集中随机选取23张图像,每一张图像首先采用5种增强方法(LIME, RetinexNet, NPE, SRIE,和iEnlightenGAN)。然后我们让9个受试者以两两比较的方式独立地比较这5个输出。具体地说,就是每一次向受试者展示从五个输出中随机抽取的一对图像,并要求受试者评估哪一张的质量更好。指导受试者考虑:1)、图像是否含有可见噪声;2)、图像是否存在曝光过度或曝光不足的伪影;3)、图像是否显示不真实的颜色或纹理扭曲。接下来,我们拟合一个Bradley-Terry模型来估计数字主观评分,以便使用与之前作品[47]完全相同的方法对五种方法进行排序。结果,每一种方法在该图像上的等级为1-5。我们对所有23张图像重复上述操作。
图5显示了5个直方图,每个直方图描述了一个方法在23张图像上接收到的秩分布。例如,EnlightGAN已经排名第一(即(主观评分最高)在23张图片中有10张,第二张是8张,第三张是5张。通过对五幅直方图的比较,可以看出,总体来说,阿德启发gan得到的结果是最受人类受试者喜爱的,在23幅图像中平均排名为1.78。RetinexNet和LIME得分不高,因为造成许多过度曝光,有时放大噪音。
4.3.3、无参考图像质量评估
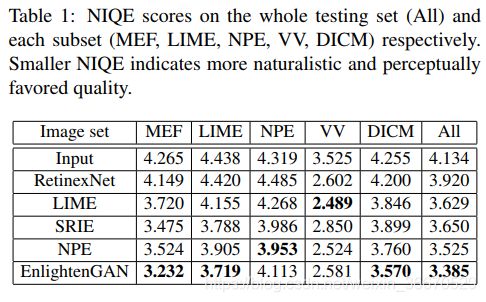
我们采用自然图像质量评价器(Natural Image Quality Evaluator, NIQE),一种著名的无参考图像质量评价方法来评价真实图像的恢复,而不考虑ground-truth情况,提供定量的比较。表1报告了之前作品使用的五个公开图像集(MEF、NPE、LIME、VV和DICM)的NIQE结果:NIQE值越低,说明视觉质量越好。EnlightenGAN在五局三局中获胜,并且在总体平均NIQE方面是最好的。这进一步证明了在产生高质量的视觉结果方面,与当前的先进方法相比,EnlightenGAN的优越性。
4.4、在真实图像上的适配
域适配是实现可推广的现实图像增强不可缺少的因素。通过unpaired训练策略,我们可以直接学习如何从不同的域增强现实世界的弱光图像。在这些弱光图像中,并没有配对的正态光训练数据,甚至没有来自同一域的正态光数据。我们使用来自真实驾驶数据集Berkeley Deep driving (BBD-100k
)[1]的低光图像进行实验,以展示实践中使用的这一独特优势。
我们从BBD-100k集合中选取950张夜间照片(像素强度平均值小于45)作为微光训练图像,另外选取50张微光图像进行遮挡测试。这些低光图像受到严重的伪影和高ISO噪声的影响。然后,我们比较了在不同法线光图像集上训练的两种EnlightenGAN版本,包括:1)、第4.1节中所述的预训练的EnlightenGAN模型,不适应于BBD-100k;2)、EnlightenGAN-N:EnlightenGAN的域适配改编版本,它使用来自于BBD-100k数据集的BBD-100k弱光图像进行训练,而正常光图像仍然是我们4.1节未配对数据集的高质量图像。我们还包括了传统的方法,自适应直方图均衡(AHE),和一个预先训练的LIME模型进行比较。
如图6所示,LIME的结果存在严重的噪声放大和过度曝光伪影,而AHE的亮度增强不够。最初的EnlightenGAN也导致了在这个未被看到的图像领域明显的伪影。相比之下,EnlightenGAN-N产生了最赏心悦目的结果,在亮度和伪影/噪声抑制之间取得了令人印象深刻的平衡。由于unpaired training,可以很容易地将EnlightenGAN改编成EnlightenGAN-N,而不需要在新领域中使用任何监督/配对数据,这极大地促进了其在现实世界中的普遍化。
4.5、改进分类的预处理
图像增强作为改善后续高水平视觉任务的预处理,最近受到了越来越多的关注[28,49,50],并进行了一些基准测试。我们研究了光增强对极暗(ExDark)数据集的影响,[53]是专门为微光图像识别任务而建立的。光照增强后的分类结果可以作为语义信息保存的一种间接措施,如[28,47]所示。
ExDark数据集包含7363张弱光图像,其中训练集3000张,验证集1800张,测试集2563张,注释为12个目标类。我们只使用它的测试集,使用我们预先训练好的开明gan作为预处理步骤,然后通过另一个ImageNet预先训练好的ResNet-50分类器。既不进行域适配,也不进行联合训练。高层级性能作为增强结果的固定语义感知指标。
在弱光测试集中,采用EnlightenGAN作为预处理,增强后分类准确率从22.02% (top-1)和39.46% (top-5)提高到23.94% (top-1)和40.92% (top-5)。这提供了一个侧面的证据,表明EnlightenGAN除了产生视觉上令人愉悦的结果外,还保留了语义上的细节。我们还用LIME和AHE进行了实验。LIME将准确率提高到23.32% (top-1)和40.60% (top-5), AHE得到23.04% (top-1)和40.37% (top-5)。
5、结论
在这篇论文中,我们用一个新颖而灵活的无监督框架来解决弱光增强问题。在不需要任何配对训练数据的情况下,所提出的EnlightenGAN操作和推广效果良好。在各种低光数据集上的实验结果表明,我们的方法在主观和客观指标下优于多种最新的方法。此外,我们证明了EnlightenGAN可以很容易地适应真正的噪声低光图像,并产生视觉上令人满意的增强图像。我们未来的工作将探索如何在一个统一的模型中根据用户输入来控制和调整光增强级别。由于光增强的复杂性,我们也期望集成算法与传感器的创新。