深度学习网络结构笔记----Depthwise卷积与Pointwise卷积--深度可分卷积-- GoogleNet,Xception,MobileNetv1--v3
目录
1,常规卷积操作
1,什么是Depthwise Convolution
3,什么是Pointwise Convolution
4 ,参数对比
5,Depthwise Separable Convolution(深度可分卷积)
5.1 GoogleNet
5.2 Xception
5.2.1 Xception的演变过程
5.2.2 Xception架构
5.3 MobileNet结构
5.3.1 MobileNet V1的基本结构
5.3.2 MobileNet v2
5.3.3 MobileNet v3
1,常规卷积操作
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。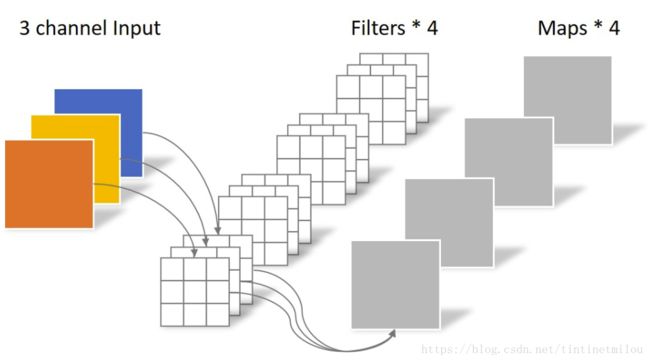
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
1,什么是Depthwise Convolution
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
3,什么是Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。

简而言之,
Depthwise :就是在depth上面做文章,就是常说的channel ,对不同的channel使用不同的卷积核卷积提取特征
Pointwise:就是正常的卷积方式啦,但是是point的,就是对某一点,某一像素,所以kernel=[1,1]
下图可以看到这两种网络的明显的区别:
4 ,参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
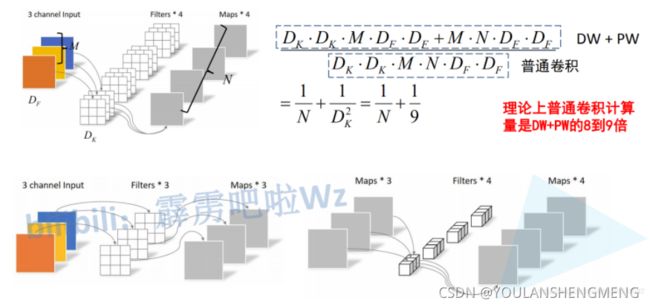
那Depthwise Separable Convolution(深度可分卷积)与传统的卷积相比有到底能节省多少计算量呢,下图对比了这两个卷积方式的计算量,其中Df是输入特征矩阵的宽高(这里假设宽和高相等),Dk是卷积核的大小,M是输入特征矩阵的channel,N是输出特征矩阵的channel,卷积计算量近似等于卷积核的高 x 卷积核的宽 x 卷积核的channel x 输入特征矩阵的高 x 输入特征矩阵的宽(这里假设stride等于1),在我们mobilenet网络中DW卷积都是是使用3x3大小的卷积核。所以理论上普通卷积计算量是DW+PW卷积的8到9倍(公式来源于原论文)
5,Depthwise Separable Convolution(深度可分卷积)
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
通常DW卷积和PW卷积是放在一起使用的,一起叫做Depthwise Separable Convolution(深度可分卷积)
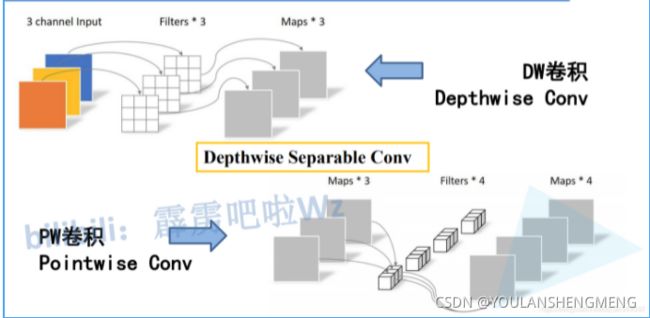
使用DW卷积后输出特征矩阵的channel是与输入特征矩阵的channel相等的,如果想改变/自定义输出特征矩阵的channel,那只需要在DW卷积后接上一个PW卷积即可。
5.1 GoogleNet
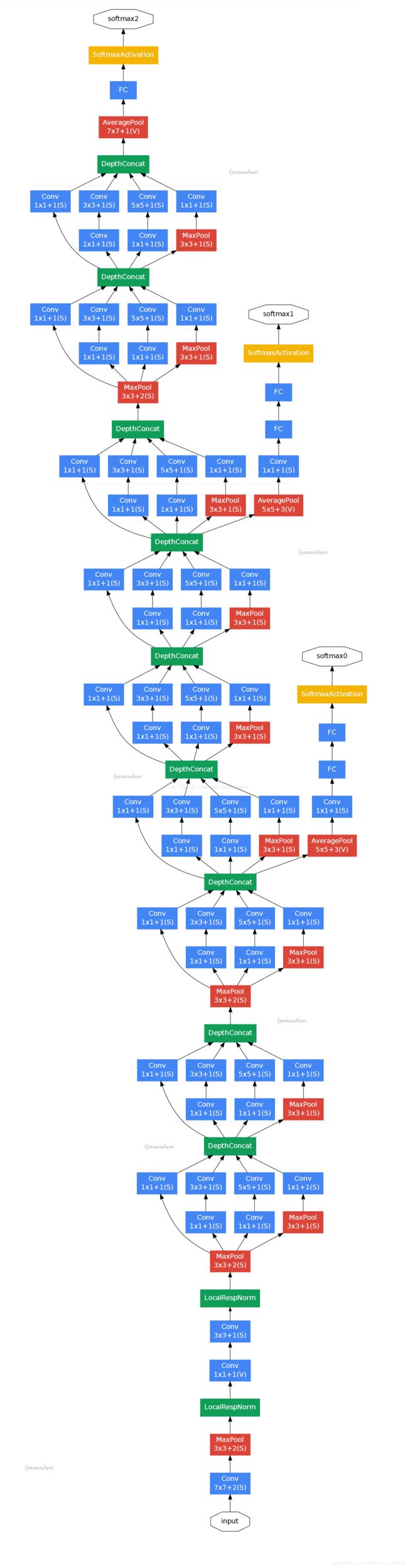
在GoogLeNet中第三层为inception module,采用不同尺度的卷积核来处理问题。第二层到第三层的四个分支分别为:
(1)64个1x1的卷积核,进行ReLU计算后得到28X28X64
(2)96个1X1的卷积核作为3x3卷积核之前的reduce,变成28x28x96,进行ReLU计算后,在进行128个3x3的卷积,pad为1,变为28x28x128.
(3)16个1x1的卷积核作为5x5卷积核之前的reduce,变为28x28x96,进行ReLU计算后,在进行32个5x5的卷积,pad为2,变为28x28x32.
(4)pool层,3x3的卷积核,pad为1,输出为28x28x192,进行32个1x1的卷积,变为28x28x32。
最后将四个结果进行拼接,输出为28x28x256
5.2 Xception
5.2.1 Xception的演变过程
基 于Inception系列网络结构的基础上,结合depthwise separable convolution, 就是Xception。 下图从左到右是Inception V1~IncVeption V3

Xception是Google出品,属于2017年左右的东东。它在Google家的MobileNet v1之后,MobileNet v2之前。它的主旨与MobileNet系列很像即推动Depthwise Conv + Pointwise Conv的使用。只是它直接以Inception v3为模子,将里面的基本inception module替换为使用Depthwise Conv + Pointwise Conv,又外加了residual connects,
最终模型在ImageNet等数据集上都取得了相比Inception v3与Resnet-152更好的结果。当然其模型大小与计算效率相对Inception v3也取得了较大提高。
从Inception module到Separable Conv的演变之路
1)从Inception v3到简化后了的inception module
inception module中使用了大量的1x1 conv来重视学习channels之间的关联,然后再分别使用3x3/5x5(两个3x3)等去学习其不同维度上的单个channel内的空间上的关联;若我们基于以上inception中用到的关联关系分离假设而只使用3x3 convs来表示单个channel内的空间关联关系,得到简化后的inception module
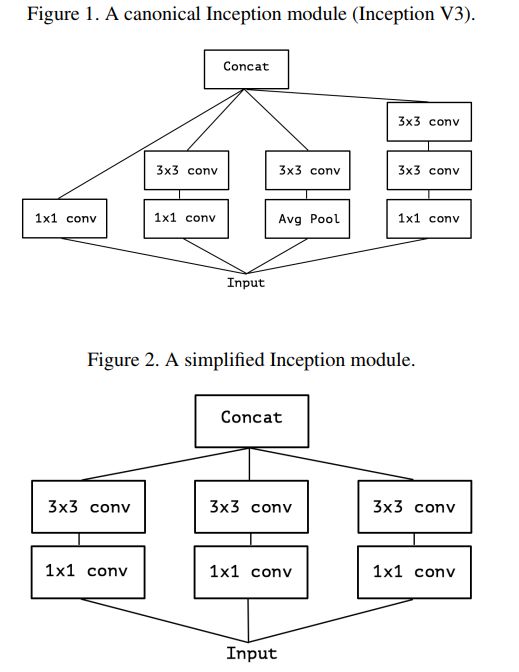
2)使用新的方法表示简化后了的inception module
上图2中表示的简化版Inception模块又可被表示为下图3中的形式。可以看出实质上它等价于先使用一个1x1 conv来学习input feature maps之上channels间特征的关联关系,然后再将1x1 conv输出的feature maps进行分割,分别交由下面的若干个3x3conv来处理其内的空间上元素的关联关系。

3)将每一channel分别使用一个相应的conv 3x3产生的Separable conv
更进一步,何不做事做绝将每个channel上的空间关联分别使用一个相应的conv 3x3来单独处理呢。 这样就产生了的Separable conv
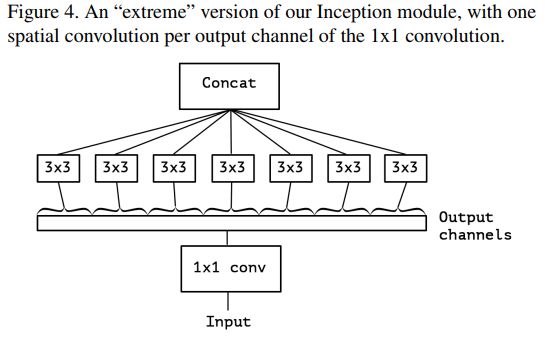
5.2.2 Xception架构
下图中为Xception结构的表示。它就是由Inception v3直接演变而来。其中引入了Residual learning( 残差学习)的结构。其基本结构如下图所示:
对应的总的网络结构为:

Entry flow主要是用来不断下采样,减小空间维度;中间则是不断学习关联关系,优化特征;最终则是汇总、整理特征,用于交由FC来进行表达
5.3 MobileNet结构
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。
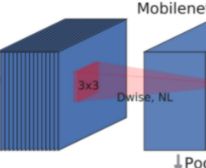
要说MobileNet网络的优点,无疑是其中的Depthwise Convolution结构(大大减少运算量和参数数量)。下图展示了传统卷积与DW卷积的差异,在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算)。而在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数)
刚说了使用DW卷积后输出特征矩阵的channel是与输入特征矩阵的channel相等的,如果想改变/自定义输出特征矩阵的channel,那只需要在DW卷积后接上一个PW卷积即可,如下图所示,其实PW卷积就是普通的卷积而已(只不过卷积核大小为1)。通常DW卷积和PW卷积是放在一起使用的,一起叫做Depthwise Separable Convolution(深度可分卷积)。
5.3.1 MobileNet V1的基本结构
depthwise +BN ReLU + pointwise + BN ReLU
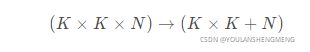

左侧的表格是mobileNetv1的网络结构,表中标Conv的表示普通卷积,Conv dw代表刚刚说的DW卷积,s表示步距,根据表格信息就能很容易的搭建出mobileNet v1网络。在mobilenetv1原论文中,还提出了两个超参数,一个是α一个是β。α参数是一个倍率因子,用来调整卷积核的个数,β是控制输入网络的图像尺寸参数,下图右侧给出了使用不同α和β网络的分类准确率,计算量以及模型参数:

5.3.2 MobileNet v2
在MobileNet v1的网络结构表中能够发现,网络的结构就像VGG一样是个直筒型的,不像ResNet网络有shorcut之类的连接方式。而且有人反映说MobileNet v1网络中的DW卷积很容易训练废掉,效果并没有那么理想。所以我们接着看下MobileNet v2网络。
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。刚刚说了MobileNet v1网络中的亮点是DW卷积,那么在MobileNet v2中的亮点就是Inverted residual block(倒残差结构),如下下图所示,左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的到残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
倒残差结构
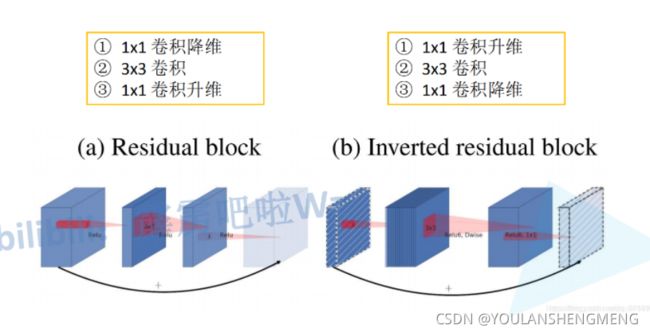
在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。
下图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。

5.3.3 MobileNet v3
MobileNetV3 一种轻量级网络,它的参数量还是一如既往的小。
它综合了以下四个特点:
1、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
2、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
3、轻量级的注意力模型。
4、利用h-swish代替swish函数。
MobileNetV3(large)的整体结构
第一列Input代表mobilenetV3每个特征层的shape变化;
第二列Operator代表每次特征层即将经历的block结构,我们可以看到在MobileNetV3中,特征提取经过了许多的bneck结构;
第三、四列分别代表了bneck内逆残差结构上升后的通道数、输入到bneck时特征层的通道数。
第五列SE代表了是否在这一层引入注意力机制。
第六列NL代表了激活函数的种类,HS代表h-swish,RE代表RELU。
第七列s代表了每一次block结构所用的步长。

bneck结构如下图所示:

它综合了以下四个特点:
a、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
b、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。在输入1x1卷积进行升维度后,进行3x3深度可分离卷积。
c、轻量级的注意力模型。这个注意力机制的作用方式是调整每个通道的权重

d、利用h-swish代替swish函数。
在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。

网络实现代码:
https://blog.csdn.net/weixin_44791964/article/details/104068321
参考博文:
Depthwise卷积与Pointwise卷积_干巴他爹的小本本-CSDN博客