CVPR 2022 | 南大&腾出提出ST++: 半监督语义分割中更优的自训练范式
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达、
作者:LeolhYang | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/476692814
在这里和大家分享一下我们被CVPR 2022录用的工作"ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation". 在本工作中,我们在半监督语义分割领域重新思考了传统的多阶段自训练(self-training)范式,并提出两点关键的改进策略,使得这种较为古老的训练流程仍能达到当前最佳的性能。
此外也非常感谢 @Pascal对我们工作的解读:Pascal:ST++: 让 Self-Training 更好地用于半监督语义分割 (CVPR'22)

ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
作者单位:南京大学、腾讯、东南大学
文章地址:https://arxiv.org/abs/2106.05095
代码地址:github.com/LiheYoung/ST-PlusPlus
Introduction
近来较多的半监督学习工作都是基于端到端的框架来做的,学生模型不断学习教师模型产生的伪标签。由于模型不断被更新,伪标签的质量也会不断提升,进而持续促进半监督学习的性能。其中比较具有代表性的有半监督分类中的FixMatch[1],半监督语义分割中的CutMix-Seg[2]、PseudoSeg[3]、CPS[4],半监督目标检测中的Unbiased Teacher[5]、Humble Teacher[6]、Soft Teacher[7]等。
尽管这些方法取得了巨大的成功,然而在训练前期,即使手动设置了置信度阈值,依然存在较多的错误伪标签会误导学生模型的学习。此外,这种在线学习的范式需要在不同epochs对同一张图像多次打出伪标签,比较耗时和耗显存(一个minibatch中需要同时包含有标签图像以及强、弱增广的无标签图像)。因此我们希望重新思考一下传统的多阶段self-training范式在半监督语义分割中的应用前景。self-training流程的优点在于,模型在有标签图像上充分训练后,对所有无标签图像只需要预测一次伪标签,且伪标签质量比较有保障。在此基础上,我们提出了两种改进方案:
在学习无标签图像时,在其上施加强数据增广,以增加学习的难度,可以学得额外的信息,并缓解对错误伪标签的过拟合
由易至难、从可靠标签到不可靠标签,渐进式地利用无标签图像及其伪标签。其中,我们提出基于第一阶段训练过程中伪标签的稳定性来选取可靠的图像,而非像素。
Background
首先介绍一下最简单的self-training范式,总共分为三个阶段:
【有监督预训练】在有标签图像上完全训练得到一个初始的教师模型
【生成伪标签】用教师模型在所有的无标签图像上预测one-hot伪标签
【重新训练】混合有标签图像和无标签图像及其伪标签,在其上重新训练一个学生模型,用于最终的测试
Method
我们的方法分为两部分,分别是ST和ST++,后者是在前者的基础上又做了进一步的渐进式选择策略的改进。
ST: 在重新训练阶段,对无标签图像进行强数据增广来学习
我们提出的ST仅需对传统的self-training范式做很小的改进,就可以显著提升其性能。
具体来说,由于第二阶段预测出的伪标签仍然是包含较多噪声的,如果在重新训练阶段直接对这些原图以及带噪声的标签进行学习,很容易过拟合其中的噪声标签;此外,由于学生模型直接学习同样结构的教师模型产生的伪标签,此过程并没有引入额外的信息,学生模型唯一在做的其实只是entropy minimization(因为我们对教师模型的预测结果取了one-hot label)。
基于上述两点动机,我们提出在重新训练阶段对无标签图像进行强数据增广来学习。首先,由于每次无标签图像输入进入模型前都进行了随机的强数据增广,也就是说尽管是同样一张图像,不同epochs见到的输入也一直在变化,也就没有固定的输入-输出的映射,模型在这种情况下不容易过拟合伪标签中的噪声;此外,学生模型是在强增广的图像上学习的,可以在教师模型的基础上学得更加丰富的表征。
这种设计使得学生模型不仅仅是在做entropy minimization,同时由于不同版本的强增广图像都受到同样的伪标签的监督(也就是教师模型生成的固定的one-hot label),此过程也可以看作是在不同的epochs之间对同一张无标签图像进行consistency regularization。因此,注入了强增广操作的self-training范式,也就是我们的ST,同时包含了半监督学习中两种主流的做法,即entropy minimization和consistency regularization。
我们在实验中采用了四种十分基本的强增广策略,包括colorjitter、blur、grayscale、以及Cutout。事实上前三种增广策略的组合就已经能够得到足够好的结果。
需要注意的是,为了尽可能的减少超参数,以及增加我们方法的普适性,我们没有根据模型预测出的置信度设置一个阈值来选取高质量的伪标签。并且根据我们的实验,这种做法也并没有在众多settings上带来稳定的提升。此外,为了尽可能减少训练时间,我们也没有进一步的迭代打伪标签并重训练(也就是用重新训练得到的学生模型重新打伪标签再训练),但是根据我们的实验,这样做可以进一步提升ST的性能。
下面可以看一下更加详细的ST伪代码,流程还是比较直观的:
 ST Pseudocode
ST Pseudocode
ST++: 由易至难、从可靠到不可靠,以图像级别选取无标签图像及其伪标签
在ST的基础上,为了进一步缓解错误的伪标签带来的负面影响,我们提出了ST++,由易至难、从可靠伪标签到不可靠伪标签,渐进式地利用无标签图像;并且不同于一般做法中选取高置信度的像素,ST++根据第一阶段训练过程中伪标签的稳定性来选取可靠的图像。

下面描述一下我们对可靠的无标签图像的选择策略。我们在实验中观察到,比较简单的图像在训练前期就会达到比较高的正确率,且训练后期伪标签变化很小;相反,对于比较困难的图像,模型在训练的不同epochs预测出的伪标签往往有较大差异。基于此观察,我们提出通过度量伪标签在不同epochs的稳定性来确定无标签图像及其伪标签的可靠性。为了这种度量策略更加稳定,我们是基于不同epochs的整图伪标签之间的meanIOU来算的。具体做法是,在第一阶段有标签图像上的预训练过程中保存K个checkpoints,考虑到往往最后一个checkpoint的质量最高,因此对于一张无标签图像 u,我们用前 K-1 个checkpoints在 u 上预测出的伪标签和第 K 个checkpoint的预测结果算meanIOU,meanIOU越大,说明他们预测出的伪标签的重合度越高,也就是伪标签在训练过程中越稳定,其质量也越可靠。形式化描述如下:
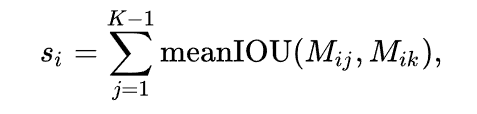
其中, si 衡量了无标签图像 ui 的稳定性和可靠性, Mij 表示第 j 个checkpoint在 ui 上预测出的伪标签。
获得了所有无标签图像的稳定性和可靠性指标 s 后,我们继续基于整图来进行选取,因为我们认为在语义分割的训练中,整图能够提供比零散的像素更加全局的语义信息。
下面是ST++的伪代码:
 ST++ Pseudocode
ST++ Pseudocode
Experiments
Comparison with State-of-the-Art Methods
我们在Pascal VOC 2012和Cityscapes这两个数据集的多种settings上验证了ST和ST++的有效性。
由于2021年之前的半监督语义分割工作大多采用的模型结构是DeepLabv2 with ResNet-101,2021年开始很多工作也增加了PSPNet with ResNet-50,DeepLabv3+ with ResNet-50/101的结果,为了更充分地与更多的工作进行公平对比,我们在Pascal VOC上报告了上述全部的四种模型的结果。可以看到我们的ST和ST++都取得了state-of-the-art performance。为了更好地展示半监督算法的意义,我们也报告了仅利用有标签图像的结果,参见每种模型下的第一行SupOnly结果,可以看到半监督算法对于SupOnly的提升十分明显。
 Pascal VOC 2012上ST和ST++的实验结果。有标签图像是选取自被扩充后的Pascal VOC数据集(总共10582张图像)
Pascal VOC 2012上ST和ST++的实验结果。有标签图像是选取自被扩充后的Pascal VOC数据集(总共10582张图像)
Pascal VOC 2012下还有另一种setting,即从原始的高质量标注的训练集(1464张图像)中选取有标签图像,我们也进行了相应的对比,如下。
 Pascal VOC 2012上ST和ST++的实验结果。有标签图像是选自原始的高质量标注的Pascal VOC训练集(1464张图像)
Pascal VOC 2012上ST和ST++的实验结果。有标签图像是选自原始的高质量标注的Pascal VOC训练集(1464张图像)
我们进一步比较了Cityscapes下的实验结果。
 Cityscapes上ST和ST++的实验结果
Cityscapes上ST和ST++的实验结果
Ablation Studies
ST中强数据增广(Strong Data Augmentation, SDA)的意义
在下表中我们首先给出了最原始的self-training的结果(第一行),通过第一行与第三行ST结果的对比,可以看出SDA对于无标签图像的作用。为了进一步验证此提升并非来自于这些增广策略本身,我们也尝试将SDA同时加在了有标签图像上(第二行),可以看出结果相较于第三行出现了下降。此结果说明SDA的作用并非在于其本身,而是为原本在无标签图像上的bootstrapping过程引入了额外的信息,以及缓解了对于噪声伪标签的过拟合。
 强数据增广(Strong Data Augmentation, SDA)的意义
强数据增广(Strong Data Augmentation, SDA)的意义
不同的SDA的作用
我们整个的SDA包含四种增广策略:colorjitter、blur、grayscale和Cutout。下图展示了这四种增广策略各自的作用,可以看到其中colorjitter的作用相对而言最大,并且前三种朴素的增广策略的组合就已经能够取得足够好的结果(下图棕色柱,73.1)。
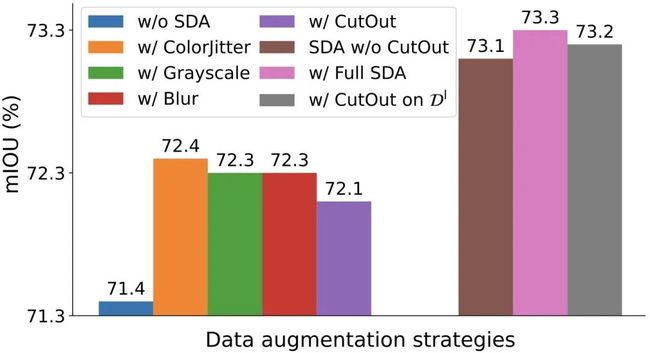 不同的强数据增广 的作用
不同的强数据增广 的作用
ST++中选取出的可靠样本和不可靠样本的伪标签质量对比

 可靠图像集合和不可靠图像集合的伪标签质量差异(紫色和棕色),以及重新给不可靠集合打伪标签后的提升(粉色)
可靠图像集合和不可靠图像集合的伪标签质量差异(紫色和棕色),以及重新给不可靠集合打伪标签后的提升(粉色)
ST++的提升是否仅仅受益于两阶段的策略?
ST++提出根据可靠/不可靠集合,把原本的重训练过程拆成两个部分。我们需要进一步验证其提升是否仅仅来自于两阶段的训练流程,而非对于可靠集合的智能选取。因此,我们随机从 Du 中选择50%的图像作为第一阶段的重训练,训练完成后再给剩下50%的图像重新赋予伪标签,最后用完整的 Du 和 Dl 训练得到最终的模型,我们将其称为random two-stage re-training。下表展示了random和我们的selective策略的性能差异,可见ST++的提升并不是来自于两阶段的策略。
 验证ST++的提升并不是来自于两阶段的重训练流程,而是对于可靠图像的智能选取
验证ST++的提升并不是来自于两阶段的重训练流程,而是对于可靠图像的智能选取
ST++中两阶段重训练的performance

 ST++中两个阶段重训练各自的performance,其中1/4,1/8,1/16表示有标签图像的不同比例
ST++中两个阶段重训练各自的performance,其中1/4,1/8,1/16表示有标签图像的不同比例
ST++中可靠图像的选取比例
我们默认选取可靠性得分前50%的图像作为可靠图像,剩下的作为不可靠图像。下表展示了不同的选取比例的影响,可以看到ST++对此处的选择比例比较鲁棒。
 可靠图像的不同选择比例
可靠图像的不同选择比例
ST++中图像级和像素级选择策略的比较
在ST++,我们提出基于图像级别选择可靠样本,而非在半监督语义分割中通常采用的像素级别样本[8]。我们认为图像级别的样本能够在语义分割中提供更好的全局语义信息,能够让分割模型更加充分的学习。为了验证这一观点,我们也比较了图像级别选择策略和像素级别选择策略,下表中展示了两者性能的差异,可以看到图像级别的选取稳定地优于像素级别的选取。
 图像级别选择策略和常规的像素级别选择策略的对比
图像级别选择策略和常规的像素级别选择策略的对比
进一步进行迭代式重新训练(iterative re-training)的效果
self-training范式往往可以通过不断的迭代式的重新训练获得进一步的性能提升,具体做法就是用重新训练得到的学生模型再为无标签图像赋予一遍伪标签,并继续重新训练。我们也尝试了ST++能否进一步受益于这种迭代式的重新训练,我们额外增加了一个阶段的重训练(下图Re-train #3),可以看到ST++仍能获得进一步的提升。
 ST++仍能受益于进一步的迭代式重训练(Re-train #3)
ST++仍能受益于进一步的迭代式重训练(Re-train #3)
Conclusion
在本工作中我们调研了传统的self-training范式在半监督语义分割中的应用前景,并提出了两个关键的改进策略,分别是在无标签图像上注入强数据增广和基于图像级别选择的渐进式重训练策略。我们发现,结合了上述改进策略后,传统的self-traininig范式可以同时享有entropy minimization和consistency regularization的优点,并且可以取得优于最新的采用端到端训练的方法的结果。
参考
^FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence, NeurIPS 2020
^Semi-supervised semantic segmentation needs strong, varied perturbations, BMVC 2020
^PseudoSeg: Designing Pseudo Labels for Semantic Segmentation, ICLR 2021
^Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision, CVPR 2021
^Unbiased Teacher for Semi-Supervised Object Detection, ICLR 2021
^Humble Teachers Teach Better Students for Semi-Supervised Object Detection, CVPR 2021
^End-to-End Semi-Supervised Object Detection with Soft Teacher, ICCV 2021
^Rethinking Pre-training and Self-training, NeurIPS 2020
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看