BERT源码解析(上)
解读源码前先大致了解下什么是Bert吧
Bert用了Transform的encoder侧网络,作为一个文本编码器,使用大规模数据进行预训练,预训练使用了两个loss,一个是LM Mask,遮蔽源端的一些字,通过上下文去预测这些字。还有一个是next sentence prediction,判断两个句子是否在文章中互为上下句,然后使用大规模的语料库去预训练。模型结构如下:
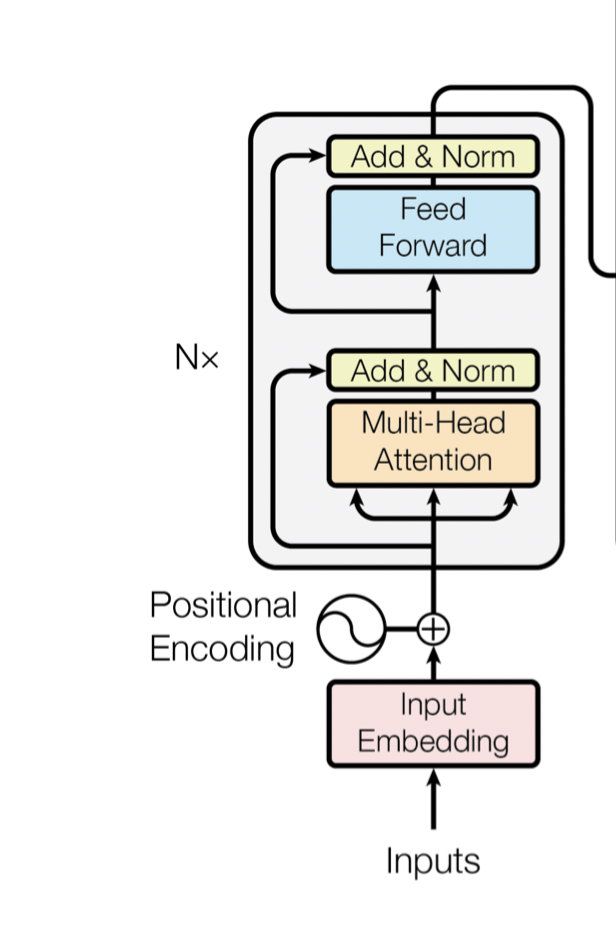
Bert base 具有12层上图所示的结构,每一层包含 multi-head Attention、Feed Forward两层子结构。
了解大致模型结构之后,开始快乐的源码解析之路~
文章目录
-
- 一、模型结构(modeling.py)
-
- 1、BertConfig
- 2、Embedding_lookup(BERT词向量token_embedding)
- 3、embedding_postprocessor(其实就是补全bert的输入)
- 4、attention_mask
- 5、Mutil-Head Attention
- 6、Transformer_model
- 7、Bert函数入口(__init__)
- 二、数据输入
-
- 2.1 分词器(tokenization.py)
-
- 2.1.1BasicTokenizer
- 2.1.2 WordpieceTokenizer
- 2.1.3 FullTokenizer
- 2.2 数据的生成(**create_pretraining_data.py** )
-
- 2.2.1 create_training_instances(构造训练数据)
- 2.2.2create_masked_lm_predictions(随机mask)
- 2.2.3write_instance_to_example_files(保存tfrecord数据)
一、模型结构(modeling.py)
这一部分是Bert里面的精髓,主要也是transformer encoder的实现
源码地址:https://github.com/google-research/bert/blob/master/modeling.py
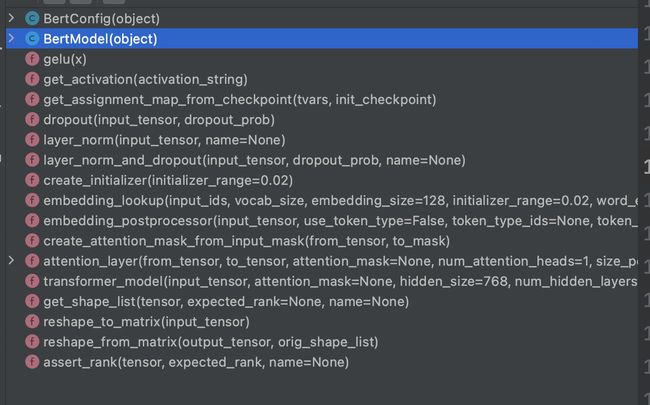
上图是文件里一些函数和类,我会挑一些比较重要的函数进行说明
1、BertConfig
关于Bert模型的一些参数配置
class BertConfig(object):
"""Configuration for `BertModel`."""
def __init__(self,
vocab_size,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
# 以下函数无非就是针对读取不同类型配置文件的适配
@classmethod
def from_dict(cls, json_object):
"""Constructs a `BertConfig` from a Python dictionary of parameters."""
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
@classmethod
def from_json_file(cls, json_file):
"""Constructs a `BertConfig` from a json file of parameters."""
with tf.gfile.GFile(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self):
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
【参数含义】
vocab_size: 输入词汇量大小
hidden_size: 隐藏层大小
num_hidden_layers: 就是上图中结构的个数(Transformer encoder中的隐藏层数)
num_attention_heads:定义multi-header attention 的head数 遵循 hidden_size % num_attention_heads == 0
intermediate_size: feed-forward layer中神经元的个数
hidden_act: 隐藏层的激活函数
hidden_dropout_prob: 隐藏层的神经元失活率
attention_probs_dropout_prob: 注意力部分的dropout
max_position_embeddings: 最大位置编码
type_vocab_size: 其实就是一个样本中输入的句子个数, 比如输入: [cls] 句A [sep] 句B [sep] 那么type_vocab_size=2
initializer_range: truncated_normal_initializer初始化方法的stdev
2、Embedding_lookup(BERT词向量token_embedding)
这个函数其实就是一个查表的功能,当给定一个one-hot的时候将one-hot与矩阵相乘,得到对应位置为1的embedding向量,或者给定词的token_id通过tf.gather()根据索引值查找embedding向量(tf.gather用法参考:https://blog.csdn.net/u012193416/article/details/86516009)
def embedding_lookup(input_ids, # [batch_size, seq_length]
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
"""Looks up words embeddings for id tensor.
Args:
input_ids: int32 Tensor of shape [batch_size, seq_length] containing word
ids.
vocab_size: int. Size of the embedding vocabulary.
embedding_size: int. Width of the word embeddings.
initializer_range: float. Embedding initialization range.
word_embedding_name: string. Name of the embedding table.
use_one_hot_embeddings: bool. If True, use one-hot method for word
embeddings. If False, use `tf.gather()`.
Returns:
float Tensor of shape [batch_size, seq_length, embedding_size].
"""
# This function assumes that the input is of shape [batch_size, seq_length,
# num_inputs].
#
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
# 初始化embedding向量
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
# 转化为1维向量
flat_input_ids = tf.reshape(input_ids, [-1])
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
output = tf.gather(embedding_table, flat_input_ids)
# 以list的形式返回input_ids的形状,这个是源码自己定义的函数
input_shape = get_shape_list(input_ids)
# input_shape[0:-1] = [batch_size, sequence], input_shape[-1]= num_inputs
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
3、embedding_postprocessor(其实就是补全bert的输入)
因为BERT模型有三个输入分别是 token embedding ,segment embedding 以
及 position embedding 目前我们已经解决了token embedding,还差segment embedding 和position embedding。
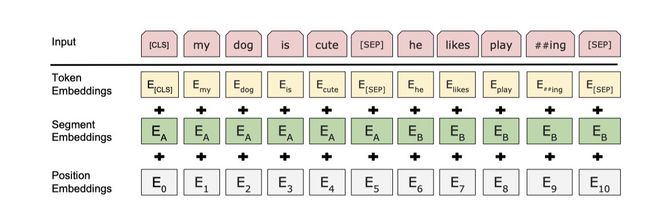
稍微解释下三个embedding的含义
token embedding: 每个字或词对应embedding,可以随机初始化通过模型不断训练
Segment embedding: 如果输入为两个句子让模型知道哪个是句子1哪个是句子2
Position embedding: 输入的位置信息,Bert是随机初始化的,然后通过训练来学,transformer是由sin/cos函数生成的固定的值
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
# 感觉命名为embedding_size会更好
width = input_shape[2]
output = input_tensor
# segment embedding信息
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary. token_type_vocab_size一般为2如果输入两个句子的话
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
# position embedding信息
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# 这里position embedding是可学习的参数,[max_position_embeddings, width
# 但是通常实际输入序列没有达到max_position_embeddings
# 所以为了提高训练速度,使用t f . s l i c e 取 出句 子长度的e m b e d d i n g
# [0,0] 起始位置 [seq_length, -1]终止位置
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# word embedding之后的tensor是[batch_size, seq_length, width]
# 因为位置编码是与输入内容无关,它的shape总 是[seq_length, width]
# 我们无法把位置position embedding加到word embedding上
# 因此我们需要扩展位置编码为[1, seq_length, width]
# 然后 就能通过b r o a d c a s t i n g 加上去了。
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
4、attention_mask
一般在一个batch里我们会把每个样本输入的长度固定一个值,那么有些句子长度小于这个固定值那么可以通过padding来补长(大于固定值进行截断),当计算self-attention的时候我们希望去除padding部分和其它词的关联,那么可以通过mask掉这部分计算出的相似度权重。
def create_attention_mask_from_input_mask(from_tensor, to_mask):
"""Create 3D attention mask from a 2D tensor mask.
Args:
from_tensor: 2D or 3D Tensor of shape [batch_size, from_seq_length, ...].
to_mask: int32 Tensor of shape [batch_size, to_seq_length].
Returns:
float Tensor of shape [batch_size, from_seq_length, to_seq_length].
"""
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_shape = get_shape_list(to_mask, expected_rank=2)
to_seq_length = to_shape[1]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
# We don't assume that `from_tensor` is a mask (although it could be). We
# don't actually care if we attend *from* padding tokens (only *to* padding)
# tokens so we create a tensor of all ones.
#
# `broadcast_ones` = [batch_size, from_seq_length, 1]
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32)
# Here we broadcast along two dimensions to create the mask.
mask = broadcast_ones * to_mask # [batch_size, from_seq_length, to_seq_length]
return mask
5、Mutil-Head Attention
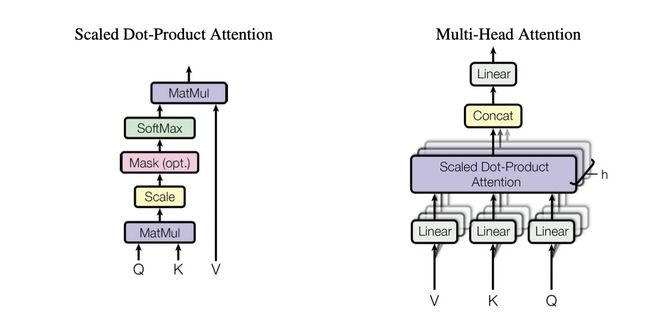
这部分主要是实现《Attention Is All You Need》论文里的self-attention想要了解原理的看官老爷请移步[2]
def attention_layer(from_tensor, # [batch_size, from_seq_length, from_width]
to_tensor, # [batch_size, to_seq_length, to_width] to_seq_length==from_seq_lengt
attention_mask=None, # [batch_size,from_seq_length,to_seq_length]
num_attention_heads=1, # attention head个数
size_per_head=512, # 每一个attention head 的维度
query_act=None, # query transform的激活函数
key_act=None, # key transform的激活函数
value_act=None, # value transform的激活函数
attention_probs_dropout_prob=0.0, # attention dropout失活率
initializer_range=0.02, # embedding随机初始化的范围
do_return_2d_tensor=False, # 返回维度是否为2D
batch_size=None,
from_seq_length=None,
to_seq_length=None):
# 输入的维度是 [batch_size, seq_length, embedding_size] 转换为[batch_size, num_heads, seq_length, size_per_head]通过拆分矩阵来计算多头注意力
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
# 把from_tensor和to_tensor 压缩成2D 张量,源码中自定义的函数
from_tensor_2d = reshape_to_matrix(from_tensor)
to_tensor_2d = reshape_to_matrix(to_tensor)
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# query_layer转成多头 :[B*F, N*H] ==> [B, F, N, H ] ==> [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# key_layer转成多头 :[B*T, N*H] ==> [B, T, N, H ] ==> [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
# 感觉这里很巧妙把除法转换为乘法,加快运算
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
# 将padding部分计算的权重的分设置成非常小的一个负数,因为当输入是一个非常小的负数是经过softmax出来就趋近于0了,相当于mask为0的地方不计算权重,很巧妙
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
上述代码有点多,总结一下self-attention流程
1)对输入的tensor进行形状的校验
2)from_tensor作为query,to_tensor作为key, value。经过一层全连接后得到query_layer、key_layer、value_layer
3) 将上述query_layer, key_layer经过transpose_for_scores转换为多头
4)根据公式计算query、key之间的点积、缩放、送入softmax得到attention_probs,然后与value加权计算:
( Q , K , V ) = s o f t m a x ( Q K T d k ) V (Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V (Q,K,V)=softmax(dkQKT)V
6、Transformer_model
这部分无非就是将attention_layer + layer_norm + feed forward + layer_norm按顺序执行,得到output
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
7、Bert函数入口(init)
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=False,
scope=None):
"""Constructor for BertModel.
Args:
config: `BertConfig` instance.
is_training: bool. true for training model, false for eval model. Controls
whether dropout will be applied.
input_ids: int32 Tensor of shape [batch_size, seq_length].
input_mask: (optional) int32 Tensor of shape [batch_size, seq_length].
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
use_one_hot_embeddings: (optional) bool. Whether to use one-hot word
embeddings or tf.embedding_lookup() for the word embeddings.
scope: (optional) variable scope. Defaults to "bert".
Raises:
ValueError: The config is invalid or one of the input tensor shapes
is invalid.
"""
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# This converts a 2D mask of shape [batch_size, seq_length] to a 3D
# mask of shape [batch_size, seq_length, seq_length] which is used
# for the attention scores.
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Run the stacked transformer.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
看懂了上面的代码理解这部分应该是很轻松的
看下源码给的一个例子吧
# Already been converted into WordPiece token ids
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
二、数据输入
2.1 分词器(tokenization.py)
先看下这个文件里面有哪些函数和类
tokenization.py主要是对原语句输入进行一些处理,主要有BasicTokenizer和WordpieceTokenizer
2.1.1BasicTokenizer
class BasicTokenizer(object):
"""Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
def __init__(self, do_lower_case=True):
"""Constructs a BasicTokenizer.
Args:
do_lower_case: Whether to lower case the input.
"""
self.do_lower_case = do_lower_case
def tokenize(self, text):
"""Tokenizes a piece of text."""
text = convert_to_unicode(text)
text = self._clean_text(text)
# This was added on November 1st, 2018 for the multilingual and Chinese
# models. This is also applied to the English models now, but it doesn't
# matter since the English models were not trained on any Chinese data
# and generally don't have any Chinese data in them (there are Chinese
# characters in the vocabulary because Wikipedia does have some Chinese
# words in the English Wikipedia.).
# 增加中文支持
text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text)
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
def _run_strip_accents(self, text):
"""Strips accents from a piece of text."""
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn":
continue
output.append(char)
return "".join(output)
def _run_split_on_punc(self, text):
"""Splits punctuation on a piece of text."""
# 用标点切分,返回list
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
def _tokenize_chinese_chars(self, text):
"""Adds whitespace around any CJK character."""
# 按字切分中文句子,就是在字两侧加入空格
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
# 判断是否为汉字
"""Checks whether CP is the codepoint of a CJK character."""
# This defines a "chinese character" as anything in the CJK Unicode block:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
#
# Note that the CJK Unicode block is NOT all Japanese and Korean characters,
# despite its name. The modern Korean Hangul alphabet is a different block,
# as is Japanese Hiragana and Katakana. Those alphabets are used to write
# space-separated words, so they are not treated specially and handled
# like the all of the other languages.
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
def _clean_text(self, text):
# 去除没有意义的字符以及空格
"""Performs invalid character removal and whitespace cleanup on text."""
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
2.1.2 WordpieceTokenizer
WordpieceTokenizer 是在WordpieceTokenizer进一步对句子进行更加细致的粒度划分,比如英文里的 taked、taking等,可能会被划分为[tak, ##ed, ##ing] 这样在一定程度上缓解未登录词对模型效果的影响,但是对中文没有影响,因为在前面BasicTokenizer里面已经切分成以字为单位的了。
class WordpieceTokenizer(object):
"""Runs WordPiece tokenziation."""
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
def tokenize(self, text):
"""Tokenizes a piece of text into its word pieces.
This uses a greedy longest-match-first algorithm to perform tokenization
using the given vocabulary.
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BasicTokenizer.
Returns:
A list of wordpiece tokens.
"""
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
def _is_whitespace(char):
"""Checks whether `chars` is a whitespace character."""
# \t, \n, and \r are technically contorl characters but we treat them
# as whitespace since they are generally considered as such.
if char == " " or char == "\t" or char == "\n" or char == "\r":
return True
cat = unicodedata.category(char)
if cat == "Zs":
return True
return False
def _is_control(char):
"""Checks whether `chars` is a control character."""
# These are technically control characters but we count them as whitespace
# characters.
if char == "\t" or char == "\n" or char == "\r":
return False
cat = unicodedata.category(char)
if cat in ("Cc", "Cf"):
return True
return False
def _is_punctuation(char):
"""Checks whether `chars` is a punctuation character."""
cp = ord(char)
# We treat all non-letter/number ASCII as punctuation.
# Characters such as "^", "$", and "`" are not in the Unicode
# Punctuation class but we treat them as punctuation anyways, for
# consistency.
if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
(cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
return True
cat = unicodedata.category(char)
if cat.startswith("P"):
return True
return False
解释下源码中的例子
比如假设输入是”unaffable”。我们跳到while循环部分,这是start=0,end=len(chars)=9,也就是先看看unaffable在不在词典里,如果在,那么直接作为一个WordPiece,如果不再,那么end-=1,也就是看unaffabl在不在词典里,最终发现”un”在词典里,把un加到结果里。接着start=2,看affable在不在,不在再看affabl,…,最后发现 ##aff 在词典里。注意:##表示这个词是接着前面的,这样使得WordPiece切分是可逆的——我们可以恢复出“真正”的词。
2.1.3 FullTokenizer
上述两种分词方式的接口
class FullTokenizer(object):
"""Runs end-to-end tokenziation."""
def __init__(self, vocab_file, do_lower_case=True):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
def tokenize(self, text):
split_tokens = []
for token in self.basic_tokenizer.tokenize(text):
for sub_token in self.wordpiece_tokenizer.tokenize(token):
split_tokens.append(sub_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
2.2 数据的生成(create_pretraining_data.py )
先看main函数再依次细分
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
# 构造tokenizer对输入语料库进行分词处理
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
input_files = []
for input_pattern in FLAGS.input_file.split(","):
input_files.extend(tf.gfile.Glob(input_pattern))
tf.logging.info("*** Reading from input files ***")
for input_file in input_files:
tf.logging.info(" %s", input_file)
rng = random.Random(FLAGS.random_seed)
# 构造训练训练instances
instances = create_training_instances(
input_files, tokenizer, FLAGS.max_seq_length, FLAGS.dupe_factor,
FLAGS.short_seq_prob, FLAGS.masked_lm_prob, FLAGS.max_predictions_per_seq,
rng)
output_files = FLAGS.output_file.split(",")
tf.logging.info("*** Writing to output files ***")
for output_file in output_files:
tf.logging.info(" %s", output_file)
# TFRecord格式保存数据
write_instance_to_example_files(instances, tokenizer, FLAGS.max_seq_length,
FLAGS.max_predictions_per_seq, output_files)
2.2.1 create_training_instances(构造训练数据)
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
"""Create `TrainingInstance`s from raw text."""
# all_documents 是list的list ,第一层list 表示document ,
# 第二层list表示document里的多个句子。
all_documents = [[]]
# 输入文件格式:
# (1) 每行一个句子。理想情况下,这些应该是实际的句子,而不是
# 整个段落或任意范围的文本。 (因为我们使用“下一句预测”任务的句子边界)。
# (2) 文档之间的空行。需要文档边界,所以“下一句预测”任务不跨越文档。
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
while True:
line = tokenization.convert_to_unicode(reader.readline())
if not line:
break
line = line.strip()
# 空行表示分割文档
if not line:
all_documents.append([])
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# Remove empty documents
all_documents = [x for x in all_documents if x]
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys())
instances = []
# 重复dupe_factor次,一个句子可以mask不同的位置
for _ in range(dupe_factor):
for document_index in range(len(all_documents)):
instances.extend(
create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
rng.shuffle(instances)
return instances
# 来实现从一个文档中抽取多个训练样本
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""Creates `TrainingInstance`s for a single document."""
document = all_documents[document_index]
# Account for [CLS], [SEP], [SEP]
max_num_tokens = max_seq_length - 3
# We *usually* want to fill up the entire sequence since we are padding
# to `max_seq_length` anyways, so short sequences are generally wasted
# computation. However, we *sometimes*
# (i.e., short_seq_prob == 0.1 == 10% of the time) want to use shorter
# sequences to minimize the mismatch between pre-training and fine-tuning.
# The `target_seq_length` is just a rough target however, whereas
# `max_seq_length` is a hard limit.
target_seq_length = max_num_tokens
# 以short_seq_prob 的概率随机生成(2 ~ max_num_tokens)的长度
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
# We DON'T just concatenate all of the tokens from a document into a long
# sequence and choose an arbitrary split point because this would make the
# next sentence prediction task too easy. Instead, we split the input into
# segments "A" and "B" based on the actual "sentences" provided by the user
# input.
instances = []
current_chunk = []
current_length = 0
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
# 将句子依次加入current_chunk 中,直到加完或者达到限制的最大长度
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
# ` a_end ` 是第一个句子A结束的下标
a_end = 1
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# Random next
# 随机构建下一句
is_random_next = False
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
# 随机的挑选另外一篇文档的随机开始的句子
# 但是理论上有可 能随机到的文档就是当前文档,因此需要一个w h i l e 循环
# 这里只 w h i l e 循环1 0 次,理论上还是有重复 的可 能性 ,但是我们忽 略
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# 对于上述构建的随机下一句 ,我们并没有真正地使用它们
# 所以为了避免数据浪费,我们将其“ 放回”
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# 构建真实的next
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
# 随机去掉一些
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
tokens = []
segment_ids = []
# 处理句子A
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
# 句子A结束,加上[SEP]
tokens.append("[SEP]")
segment_ids.append(0)
# 处理句子B
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
# 句子A结束,加上[SEP]
tokens.append("[SEP]")
segment_ids.append(1)
# # 调用create_masked_lm_predictions来随机对某些T o k e n 进行m a s k
(tokens, masked_lm_positions,
masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances
描述下上诉代码过程
1)算法首先会维护一个chunk,不断加入document中的元素,也就是句子(segment),
直到加载完或者chunk中token数大于等于最大限制,这样做的目的是使得padding的尽
量少,训练效率更高。
2)现在chunk建立完毕之后,假设包括了前三个句子,算法会随机选择一个切分点,比如
2。接下来构建 predict next 判断: (1) 如果是正样本,前两个句子当成是句子A,
后一个句子当成是句子B; (2) 如果是负样本,前两个句子当成是句子A,无关的句子从
其他文档中随机抽取。
3)得到句子A和句子B之后,对其填充tokens和segment_ids,这里会加入特殊的[CLS]和
[SEP]标记。
4)对句子进行mask操作。
2.2.2create_masked_lm_predictions(随机mask)
对Tokens进行随机mask是BERT的一大创新点。使用mask的原因是为了模型训练的过程中可以看到下文”。于是,文章中选取的策略是对输入序列中15%的词使用[MASK]标记掩盖掉,然后通过上下文去预测这些被mask的token。但是为了防止模型过拟
合地学习到【MASK】这个标记,对15%mask掉的词进一步优化:
以80%的概率用[MASK]替换:
hello world, i am bert. ----> hello world, i am [MASK].
以10%的概率随机替换:
hello world, i am bert. ----> hello world, i am Elmo.
以10%的概率不进行替换:
hello world, i am bert. ----> hello world, i am bert.
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
"""Creates the predictions for the masked LM objective."""
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
# Whole Word Masking means that if we mask all of the wordpieces
# corresponding to an original word. When a word has been split into
# WordPieces, the first token does not have any marker and any subsequence
# tokens are prefixed with ##. So whenever we see the ## token, we
# append it to the previous set of word indexes.
#
# Note that Whole Word Masking does *not* change the training code
# at all -- we still predict each WordPiece independently, softmaxed
# over the entire vocabulary.
if (FLAGS.do_whole_word_mask and len(cand_indexes) >= 1 and
token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index_set in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
# If adding a whole-word mask would exceed the maximum number of
# predictions, then just skip this candidate.
if len(masked_lms) + len(index_set) > num_to_predict:
continue
is_any_index_covered = False
for index in index_set:
if index in covered_indexes:
is_any_index_covered = True
break
if is_any_index_covered:
continue
for index in index_set:
covered_indexes.add(index)
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
assert len(masked_lms) <= num_to_predict
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
2.2.3write_instance_to_example_files(保存tfrecord数据)
就上述处理的数据保存为tfrecord格式
def write_instance_to_example_files(instances, tokenizer, max_seq_length,
max_predictions_per_seq, output_files):
"""Create TF example files from `TrainingInstance`s."""
writers = []
for output_file in output_files:
writers.append(tf.python_io.TFRecordWriter(output_file))
writer_index = 0
total_written = 0
for (inst_index, instance) in enumerate(instances):
input_ids = tokenizer.convert_tokens_to_ids(instance.tokens)
input_mask = [1] * len(input_ids)
segment_ids = list(instance.segment_ids)
assert len(input_ids) <= max_seq_length
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
masked_lm_positions = list(instance.masked_lm_positions)
masked_lm_ids = tokenizer.convert_tokens_to_ids(instance.masked_lm_labels)
masked_lm_weights = [1.0] * len(masked_lm_ids)
while len(masked_lm_positions) < max_predictions_per_seq:
masked_lm_positions.append(0)
masked_lm_ids.append(0)
masked_lm_weights.append(0.0)
next_sentence_label = 1 if instance.is_random_next else 0
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writers[writer_index].write(tf_example.SerializeToString())
writer_index = (writer_index + 1) % len(writers)
total_written += 1
if inst_index < 20:
tf.logging.info("*** Example ***")
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in instance.tokens]))
for feature_name in features.keys():
feature = features[feature_name]
values = []
if feature.int64_list.value:
values = feature.int64_list.value
elif feature.float_list.value:
values = feature.float_list.value
tf.logging.info(
"%s: %s" % (feature_name, " ".join([str(x) for x in values])))
for writer in writers:
writer.close()
tf.logging.info("Wrote %d total instances", total_written)
还有Bert的预训练、Finetune由于篇幅过长打算再开一篇文章!!!!!!!!!!
参考资料:
[1] https://github.com/google-research/bert
[2] https://arxiv.org/abs/1706.03762
[3] NLP大杀器BERT模型解读:https://blog.csdn.net/Kaiyuan_sjtu/article/detail
s/83991186