快速入门nebula graph
文章目录
- 快速入门nebula graph
-
-
- 1.介绍
- 2.nebula的六种数据模型
- 3.图论中的路径
- 4.启动/连接nebula
-
-
- 启动:
- 连接:
-
- 5.nGQL示例
-
-
- 1.增
- 2.删
- 3.改
- 4.查
-
- 6.client
- 7.Nebula Algorithm
-
快速入门nebula graph
1.介绍
nubula graph 是一款开源分布式易拓展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
生态图

服务架构图

2.nebula的六种数据模型
- space:图空间,相当于一个数据库,不同的图空间数据是相互隔离的
- tag:标签,由一组事先定义的属性构成
- vertex:点,用vid标识,vid在同一个图空间唯一,相当于主键,一个点至少一个tag
- edge type:边类型,同tag,由一组事先定义的属性构成
- edge:边,nebula中只有有向边,一条边只有一个edge type,只有一个rank,rank是边的一个排序值,可用作边权,一个边由四元组<起点vid,edge type,rank,终点vid>唯一标识
- properties:属性就是键值对形式存储的信息
3.图论中的路径
路径就是一个有限或者无限的点边连成的序列,路径的类型分为3种:walk,trail,path。
- walk:点边可以重复的路径。
GO语句采用的是walk类型路径 - trail:点可以重复,边不可重复的路径。
MATCH、FIND PATH和GET SUBGRAPH语句采用的是trail类型路径
trail中还有两类特殊的路径类型:cycle和circuit。
2.1 cycle:只有起点终点重复
2.2 circuit:除了起点终点重复外,还有其他点重复 - path:点边都不重复
| 点重复 | 点不重复 | |
|---|---|---|
| 边重复 | walk | NONE |
| 边不重复 | trail | path |
4.启动/连接nebula
启动:
# 1. docker启动nebula
下载nebula:git clone -b v2.6.0 https://github.com/vesoft-inc/nebula-docker-compose.git
cd /neubla目录下
docker-compose up -d
# 2.docker启动studio
下载studio:https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/nebula-graph-studio-v3.1.0.tar.gz
cd /studio目录下
docker-compose up -d
# 3.停止命令:
docker-compose down
# 4.查看服务:
docker-compose ps
连接:
-
命令行连接
下载nebula console:https://github.com/vesoft-inc/nebula-console/releases
windows下的话修改下载的文件为nebula-console.exe方便使用,执行命令连接数据库:
nebula-console -addr ip -port 端口 -u 用户名 -p 密码

-
nebula studio 连接
启动studio后访问studio,默认是localhost:7001

输入ip:端口,用户名和密码,进入图形界面:(注意ip不能是localhost或者127.0.0.1,得是真正的IP地址)
图探索界面:

控制台执行ngql界面:
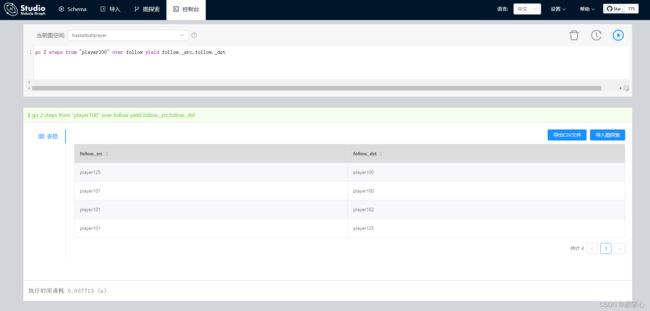
5.nGQL示例
以nba数据为例:player,team为点tag,serve,follow为边edge type
数据模型是:player-serve->team,player-follow->player
1.增
1.0 创建图空间:
create space basketballplayer(partition_num=15,replica_factor=1,vid_type=fixed_string(32));
partition_num:指定图空间的分片数量。建议设置为5倍的集群硬盘数量
replica_factor:指定每个分片的副本数量
vid_type:点ID的数据类型,可选值为FIXED_STRING()和INT64
1.1 创建tag:
create tag player(name string,age int);
1.2 创建edge type:
create edge serve(start_year int,end_year int);
1.3 创建index(match,look up等语句依赖索引去匹配数据):
create tag index player_index_0 on player();
1.4 插入点:
insert vertex player(name,age) values "player100":("Tim Duncan", 42);
1.5 插入边:
insert edge serve(start_year,end_year) values "player100"->"team204":(1997, 2016);
2.删
2.1 删除点
DELETE VERTEX "player100";
2.2 删除边
DELETE EDGE serve "player100" -> "team204"@0;
3.改
3.1 修改点:
UPDATE VERTEX ON player "player101" SET age = age + 2 WHEN name == "Tony Parker" YIELD name AS Name, age AS Age;
3.2 修改边:
UPDATE EDGE on serve "player100" -> "team204"@0 SET start_year = start_year + 1 WHEN end_year > 2010 YIELD start_year, end_year;
3.3 修改或插入点:
UPSERT VERTEX ON player "player666" SET age = 30 WHEN name == "Joe" YIELD name AS Name, age AS Age;
3.4 修改或插入边:
UPSERT EDGE on serve "player666" -> "team200"@0 SET end_year = 2021 WHEN end_year == 2010 YIELD start_year, end_year;
4.查
-
go:指定过滤条件遍历图,遍历的路径类型walk
1.1 查看指定vid所属的队伍:默认遍历出边
go from "player102" over serve
1.2 查看follow vid的点:(遍历入边)
go from "player102" over follow reversely
1.3 查看N跳的点:
go 2 steps from "player100" over follow yield follow._dst -
match:基于模式(pattern)匹配的搜索,遍历路径类型trail
2.1 查看所有player,tag player需要建好索引
match (v:player) return v
2.2 查看某个点连接的点:
match (v:player)--(v2) where id(v)=="player100" return v2
2.3 查看指定方向的点:
match (v:player)-->(v2) where id(v)=="player100" return v2
2.4 查看路径
MATCH p=(v:player{name:"Tim Duncan"})-->(v2) RETURN p;
2.5 查看指定长度的路径:
match p = (v:player{name:"Tim Duncan"})-[e:follow*2]->(v2) return p -
lookup:根据索引遍历数据,遍历路径类型trail
3.1 查看tag的所有点
lookup on player;
3.2 查看edge type的所有边
lookup on follow;
3.3 统计tag的数量
lookup on player | yield count(*) as playernum
3.4 统计边的数量
lookup on follow | yield count(*) as follownum
更详细的ngql语法参考连接:https://docs.nebula-graph.com.cn/2.6.1/3.ngql-guide/1.nGQL-overview/1.overview/
6.client
1.python client:
#安装nebula2-python:
pip install nebula2-python==2.6.0
#示例代码:
from nebula2.gclient.net import ConnectionPool
from nebula2.Config import Config
config = Config()
# 最大连接数
config.max_connection_pool_size = 10
# 连接超时时间
config.timeout = 60000
# 关闭空闲连接时间
config.idle_time = 0
# 检查空闲连接时间间隔
config.interval_check = -1
connection_pool = ConnectionPool()
ok = connection_pool.init([('10.1.92.187',9669)],config)
# print(ok)
# 连接方式一
# session = connection_pool.get_session("root","123")
# session.execute('use basketballplayer')
# result = session.execute("show tags")
# print(result)
# session.release()
# 连接方式二
with connection_pool.session_context('root','123') as sess:
sess.execute('use basketballplayer')
res = sess.execute("MATCH (v:player{name:\"Tim Duncan\"})<-[e]-(v2) RETURN e")
print(res)
1.java client参考连接:https://docs.nebula-graph.com.cn/2.6.1/14.client/4.nebula-java-client/
2.go client参考连接:https://docs.nebula-graph.com.cn/2.6.1/14.client/6.nebula-go-client/
7.Nebula Algorithm
Nebula Algorithm支持的算法:
| 算法名 | 说明 | 应用场景 |
|---|---|---|
| PageRank | 页面排序 | 网页排序、重点节点挖掘 |
| Louvain | 社区发现 | 社团挖掘、层次化聚类 |
| KCore | K 核 | 社区发现、金融风控 |
| LabelPropagation | 标签传播 | 资讯传播、广告推荐、社区发现 |
| ConnectedComponent | 联通分量 | 社区发现、孤岛发现 |
| StronglyConnectedComponent | 强联通分量 | 社区发现 |
| ShortestPath | 最短路径 | 路径规划、网络规划 |
| TriangleCount | 三角形计数 | 网络结构分析 |
| GraphTriangleCount | 全图三角形计数 | 网络结构及紧密程度分析 |
| BetweennessCentrality | 介数中心性 | 关键节点挖掘,节点影响力计算 |
| DegreeStatic | 度统计 | 图结构分析 |