mmpose教程
mmpose是商汤开源的一款基于 PyTorch 的姿态分析的开源工具箱,是 OpenMMLab 项目的成员之一。 主分支代码目前支持 PyTorch 1.5 以上的版本 ,目前官方已有中文教程
主要特性包括:
-
支持多种人体姿态分析相关任务
MMPose 支持当前学界广泛关注的主流姿态分析任务:主要包括 2D多人姿态估计、2D手部姿态估计、2D人脸关键点检测、133关键点的全身人体姿态估计、3D人体形状恢复、服饰关键点检测、动物关键点检测等。 具体请参考 功能演示。
-
更高的精度和更快的速度
MMPose 复现了多种学界最先进的人体姿态分析模型,包括“自顶向下”和“自底向上”两大类算法。MMPose 相比于其他主流的代码库,具有更高的模型精度和训练速度。 具体请参考 基准测试。
-
支持多样的数据集
MMPose 支持了很多主流数据集的准备和构建,如 COCO、 MPII 等。 具体请参考 数据集准备。
-
模块化设计
MMPose 将统一的人体姿态分析框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的人体姿态分析模型。
-
详尽的单元测试和文档
MMPose 提供了详尽的说明文档,API 接口说明,全面的单元测试,以供社区参考。
安装
conda create -n open-mmlab python=3.7 -y conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.2 -c pytorch pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
环境要求: Linux, python 3.6+, pytorch 1.5+, cuda 10.2+, gcc 5+, mmcv最新版,numpy, cv2,json_traicks, xtcocotools,可选
- mmdet (to run pose demos)
- mmtrack (to run pose tracking demos)
- pyrender (to run 3d mesh demos)
- smplx (to run 3d mesh demos)
pip3 install -r requirements.txt
python3 setup.py develop数据准备
推荐把数据集软链接到$MMPOSE/data,如果你的文件结构与下面不同,可能需要调制整配置文件里相应的路径,以coco为例,结构如下图所示:
mmpose
├── mmpose
├── docs
├── tests
├── tools
├── configs
`── data
│── coco
│-- annotations
│ │-- person_keypoints_train2017.json
│ |-- person_keypoints_val2017.json
│ |-- person_keypoints_test-dev-2017.json
|-- person_detection_results
| |-- COCO_val2017_detections_AP_H_56_person.json
| |-- COCO_test-dev2017_detections_AP_H_609_person.json
│-- train2017
│ │-- 000000000009.jpg
│ │-- 000000000025.jpg
│ │-- 000000000030.jpg
│ │-- ...
`-- val2017
│-- 000000000139.jpg
│-- 000000000285.jpg
│-- 000000000632.jpg
│-- ...快速开始
使用预训练模型推理
我们提供了一些测试脚本来评估预训练模型在COCO数据集上的性能,并且提供了一些高级API以遍迁移到其他的项目中去
你可以使用如下的命令来测试一个数据集
# 单 GPU 测试
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--fuse-conv-bn] \
[--eval ${EVAL_METRICS}] [--gpu_collect] [--tmpdir ${TMPDIR}] [--cfg-options ${CFG_OPTIONS}] \
[--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}]
# 多 GPU 测试
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] \
[--gpu-collect] [--tmpdir ${TMPDIR}] [--options ${OPTIONS}] [--average-clips ${AVG_TYPE}] \
[--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}]请其中CONFIG_FILE是配置文件,CHECKPOINT_FILE是训练好模型的路径,EVAL_METRICS是评估指标,如果需要覆盖配置文件的参数可以使用CFG_OPTIONS
假设你已经下载了训好的模型,并且放在了checkpoints文件夹下
1.在 COCO 数据集下测试 ResNet50(不存储测试结果为文件),并验证 mAP 指标
./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py checkpoints/SOME_CHECKPOINT.pth 1 --eval mAP2.使用 8 块 GPU 在 COCO 数据集下测试 ResNet。在线下载模型权重,并验证 mAP 指标
./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth 8 --eval mAP此外,我们还提供了丰富的脚本,方便大家快速运行演示。 下面是 多人人体姿态估计 的演示示例,此处我们使用了人工标注的人体框作为输入。
${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
--img-root ${IMG_ROOT} --json-file ${JSON_FILE} --out-img-root ${OUTPUT_DIR} \
[--show --device ${GPU_ID}] [--kpt-thr ${KPT_SCORE_THR}]例如:
python demo/top_down_img_demo.py configs/body/2D_Kpt_SV_RGB_Img/topdown_hm/coco/hrnet_w48_coco_256x192.py https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json --out-img-root vis_results如果使用mmdet检测结果作为输入,我们提供了mmdet检测人的代码
python demo/top_down_img_demo_with_mmdet.py \
${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \
${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
--img-root ${IMG_ROOT} --img ${IMG_FILE} \
--out-img-root ${OUTPUT_DIR} \
[--show --device ${GPU_ID}] \
[--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}]例如:
python demo/top_down_img_demo_with_mmdet.py mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
configs/top_down/hrnet/coco/hrnet_w48_coco_256x192.py \
hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
--img-root tests/data/coco/ \
--img 000000196141.jpg \
--out-img-root vis_results训练模型
使用MMDistributedDataParallel和MMDataParallel实现了分布式和单机训练
所有的输出都放在work_dir里,这可以在配置文件中指定
默认每个epoch之后都会做一次评估,你可以在配置文件中改变这个行为evaluation = dict(interval=5) # This evaluate the model per 5 epoch.
根据线性缩放准则,你需要根据使用的GPU数量和batch大小调整学习率, lr=0.01 for 4 GPUs * 2 video/gpu and lr=0.08 for 16 GPUs * 4 video/gpu.
- 单GPU训练: python tools/train.py ${CONFIG_FILE} [optional arguments]
- 多GPU训练: ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
- 多机训练: ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
单台机器起多个任务:
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4如果使用slurm提交任务,需要修改配置文件使用不同的端口
config1.py: dist_params = dict(backend='nccl', port=29500)
config2.py: dist_params = dict(backend='nccl', port=29501)
评估:使用python tools/benchmark_inference.py ${MMPOSE_CONFIG_FILE}可以得到不包括IO和预处理的只有网络前传的速度
教程参见: finetune model, add new dataset, add new modules.
训练数据可视化是调试网络非常重要的一部分,可惜其没有给出代码实现,这里给出
import math
import cv2
import mmcv
import argparse
import torchvision
import numpy as np
from tqdm import tqdm
from mmpose.datasets import build_dataloader, build_dataset
def parse_args():
parser = argparse.ArgumentParser(description='mmpose test model')
parser.add_argument('--config', default='configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py')
args = parser.parse_args()
return args
def main():
args = parse_args()
cfg = mmcv.Config.fromfile(args.config)
dataset = build_dataset(cfg.data.train)
skeltons = [0,0,0,1,2,0,0,5,6,7,8,0,0,11,12,13,14]
data_loader = build_dataloader(dataset,samples_per_gpu=48, workers_per_gpu=0, dist=False, shuffle=False)
# mean = np.array(cfg.train_pipeline[6]['mean'])
# std = np.array(cfg.train_pipeline[6]['std'])
for line in cfg.train_pipeline:
if 'mean' in line:
mean = np.array(line['mean'])
std = np.array(line['std'])
nrow = 8
padding = 2
for i, data_batch in enumerate(tqdm(data_loader)):
batch_image = data_batch["img"].data
metas = data_batch["img_metas"].data[0]
file_name = "work_dirs/gt/"+str(i)+".jpg"
grid = torchvision.utils.make_grid(batch_image, nrow, padding, True)
ndarr = grid.mul(255).clamp(0, 255).byte().permute(1, 2, 0).cpu().numpy()
ndarr = ndarr.copy()
nmaps = batch_image.size(0)
xmaps = min(nrow, nmaps)
ymaps = int(math.ceil(float(nmaps) / xmaps))
height = int(batch_image.size(2) + padding)
width = int(batch_image.size(3) + padding)
k = 0
for y in range(ymaps):
for x in range(xmaps):
if k >= nmaps:
break
joints = metas[k]["joints_3d"]
joints_vis = metas[k]['joints_3d_visible']
for j,joint in enumerate(joints):
joint_vis = joints_vis[j]
jx = int(x * width + padding + joint[0])
jy = int(y * height + padding + joint[1])
joint = joint.astype(np.int32)
if joint_vis[0]:
cv2.circle(ndarr, (jx, jy), 2, [0, 255, 0], 2)
cv2.putText(ndarr, str(j),(jx, jy),1,1,(0,0,255))
sp = skeltons[j]
jp_vis = joints_vis[sp]
if joint_vis[0] and jp_vis[0]:
jp = joints[sp]
jpx = int(x * width + padding + jp[0])
jpy = int(y * height + padding + jp[1])
cv2.line(ndarr, (jx,jy),(jpx ,jpy), (255,0,255))
k = k + 1
cv2.imwrite(file_name, ndarr)
if __name__=="__main__":
main()
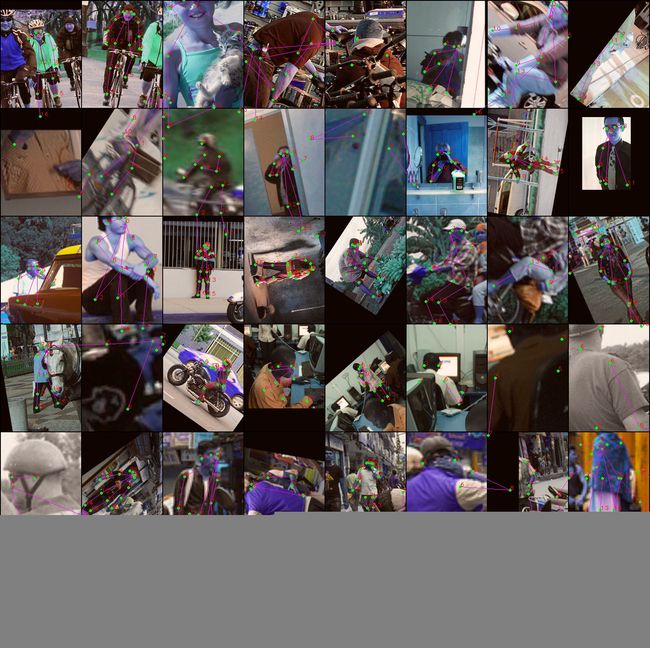
如何找到检测错误的样本并分析错误原因是提升算法性能的重要手段,代码如下
import os
import cv2
import shutil
import numpy as np
import warnings
from tqdm import tqdm
from argparse import ArgumentParser
from xtcocotools.coco import COCO
from mmpose.apis import (inference_top_down_pose_model, init_pose_model, vis_pose_result)
from mmpose.datasets import DatasetInfo
def get_args():
parser = ArgumentParser()
parser.add_argument('--pose_config', default="configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py")
parser.add_argument('--pose_checkpoint', default='https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth')
parser.add_argument('--img-root', default='data/coco/val2017')
parser.add_argument('--json-file', default='data/coco/annotations/person_keypoints_val2017.json')
parser.add_argument('--out-img-root', default='vis_coco',)
parser.add_argument('--device', default='cuda:0')
parser.add_argument('--kpt-thr', type=float, default=0.3)
args = parser.parse_args()
return args
def main():
args = get_args()
coco = COCO(args.json_file)
# build the pose model from a config file and a checkpoint file
pose_model = init_pose_model(
args.pose_config, args.pose_checkpoint, device=args.device.lower())
dataset = pose_model.cfg.data['test']['type']
dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
if dataset_info is None:
warnings.warn(
'Please set `dataset_info` in the config.'
'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
DeprecationWarning)
else:
dataset_info = DatasetInfo(dataset_info)
img_keys = list(coco.imgs.keys())
# optional
return_heatmap = False
skeleton = dataset_info.skeleton
pose_link_color = dataset_info.pose_link_color
sigmas = dataset_info.sigmas*100
# e.g. use ('backbone', ) to return backbone feature
output_layer_names = None
error_sts = np.zeros((17),dtype=np.float64)
error_cnts = np.zeros((17),dtype=np.int)
# process each image
for i in tqdm(range(len(img_keys))):#
# get bounding box annotations
image_id = img_keys[i]
image = coco.loadImgs(image_id)[0]
image_name = os.path.join(args.img_root, image['file_name'])
ann_ids = coco.getAnnIds(image_id)
# make person bounding boxes
person_results = []
keypoints = []
for ann_id in ann_ids:
person = {}
ann = coco.anns[ann_id]
# bbox format is 'xywh'
person['bbox'] = ann['bbox']
person_results.append(person)
keypoints.append(ann['keypoints'])
if len(person_results) == 0:
#print("empty img", image_name)
continue
# test a single image, with a list of bboxes
pose_results, returned_outputs = inference_top_down_pose_model(
pose_model,
image_name,
person_results,
bbox_thr=None,
format='xywh',
dataset=dataset,
dataset_info=dataset_info,
return_heatmap=return_heatmap,
outputs=output_layer_names)
img = cv2.imread(image_name)
img_h, img_w, _ = img.shape
valid_instance = 0
for i in range(len(keypoints)):
show = img#.copy()
error_num = 0
preds = pose_results[i]['keypoints']
pts = np.array(keypoints[i]).reshape(-1,3)
valid_num = np.sum(pts[:,2] == 2)
if valid_num < 10:
continue
valid_instance += 1
error = np.linalg.norm(pts[:,:2] - preds[:,:2],axis=1)
error[pts[:,2] < 2] = 0
for sk_id, sk in enumerate(skeleton):
pos1 = (int(pts[sk[0], 0]), int(pts[sk[0], 1]))
pos2 = (int(pts[sk[1], 0]), int(pts[sk[1], 1]))
if (pos1[0] > 0 and pos1[0] < img_w and pos1[1] > 0
and pos1[1] < img_h and pos2[0] > 0 and pos2[0] < img_w
and pos2[1] > 0 and pos2[1] < img_h
and pts[sk[0], 2] > args.kpt_thr
and pts[sk[1], 2] > args.kpt_thr):
r, g, b = pose_link_color[sk_id]
cv2.line(show, pos1, pos2, (int(r),int(g),int(b)))
for j in range(len(pts)):
pt = pts[j]
pred = preds[j]
if pt[2] > args.kpt_thr:
cv2.circle(show,(pt[0], pt[1]),3,(0,255,0),-1)
if error[j] > sigmas[j] * 2:
error_num += 1
color = (255,0,255)
else:
color = (255,0,0)
cv2.circle(show,(int(pred[0]), int(pred[1])),2,color)
error_sts += error
error_cnts += error > 0
if valid_num > 0:
error_sum = np.sum(error) / valid_num
else:
error_sum = np.sum(error)
dstname = image_name.split('/')[-1].split('.')[0]+".jpg"
out_file = os.path.join(args.out_img_root, dstname)
if valid_instance > 0:
cv2.imwrite(out_file, show)
if error_num > 3:
print("error ", dstname, valid_num, error_sum, error_num)
if os.path.exists(out_file):
shutil.move(out_file,'error/'+dstname)
for i,st in enumerate(error_sts):
print(i, st/error_cnts[i])
if __name__ == '__main__':
main() 

不难看出遮挡、侧身和截断是制约算法性能的主要因素。
如何对算量分析是进行模型优化的关键一步,mmpose给出了get_flops对网络的参数大小和FLOPs进行剖析,但是输出略显繁杂,抓不到重点
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,8,3)
self.conv2 = nn.Conv2d(8,16,3)
self.conv3 = nn.Conv2d(16,32,3)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
def mmcv_flops(model, input_shape):
from mmcv.cnn import get_model_complexity_info
flops, params = get_model_complexity_info(model, input_shape)
split_line = '=' * 30
print(f'{split_line}\nInput shape: {input_shape}\n'f'Flops: {flops}\nParams: {params}\n{split_line}')
def mrcv_flops(model, input_shape):
from pt_flops import get_model_summary
print(get_model_summary(model,input_shape))
if __name__=="__main__":
#model = Net()
from mmpose.models.backbones.alexnet import AlexNet
model = AlexNet()
from mmpose.models.backbones.hrnet import HRNet
extra = dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(32, 64)),
stage3=dict(
num_modules=4,
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(32, 64, 128)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(32, 64, 128, 256)))
model = HRNet(extra)
input_shape = (3, 256, 192)
mmcv_flops(model, input_shape)
mrcv_flops(model, input_shape)输出如下,注意这里的G并没有和通常似的处于1024,而是以1000为单位,比较时注意差异
==============================
Input shape: (3, 256, 192)
Flops: 7.7 GFLOPs
Params: 28.54 M
==============================
Model Summary
Name Input Size Output Size Parameters Multiply Adds (Flops)
--------------------------------------------------------------------------------------------------------
Conv2d_1 [1, 3, 256, 192] [1, 64, 128, 96] 1728 0.006 21233664 0.276
BatchNorm2d_1 [1, 64, 128, 96] [1, 64, 128, 96] 128 0.000 1572864 0.020
Conv2d_2 [1, 64, 128, 96] [1, 64, 64, 48] 36864 0.129 113246208 1.474
BatchNorm2d_2 [1, 64, 64, 48] [1, 64, 64, 48] 128 0.000 393216 0.005
Conv2d_3 [1, 64, 64, 48] [1, 64, 64, 48] 4096 0.014 12582912 0.164
BatchNorm2d_3 [1, 64, 64, 48] [1, 64, 64, 48] 128 0.000 393216 0.005
Conv2d_4 [1, 64, 64, 48] [1, 64, 64, 48] 36864 0.129 113246208 1.474
BatchNorm2d_4 [1, 64, 64, 48] [1, 64, 64, 48] 128 0.000 393216 0.005
Conv2d_5 [1, 64, 64, 48] [1, 256, 64, 48] 16384 0.057 50331648 0.655
BatchNorm2d_5 [1, 256, 64, 48] [1, 256, 64, 48] 512 0.002 1572864 0.020
Conv2d_6 [1, 64, 64, 48] [1, 256, 64, 48] 16384 0.057 50331648 0.655
BatchNorm2d_6 [1, 256, 64, 48] [1, 256, 64, 48] 512 0.002 1572864 0.020
Conv2d_7 [1, 256, 64, 48] [1, 64, 64, 48] 16384 0.057 50331648 0.655
BatchNorm2d_7 [1, 64, 64, 48] [1, 64, 64, 48] 128 0.000 393216 0.005
Conv2d_8 [1, 64, 64, 48] [1, 64, 64, 48] 36864 0.129 113246208 1.474
BatchNorm2d_8 [1, 64, 64, 48] [1, 64, 64, 48] 128 0.000 393216 0.005
Conv2d_9 [1, 64, 64, 48] [1, 256, 64, 48] 16384 0.057 50331648 0.655
BatchNorm2d_9 [1, 256, 64, 48] [1, 256, 64, 48] 512 0.002 1572864 0.020
...
Conv2d_280 [1, 128, 16, 12] [1, 128, 16, 12] 147456 0.517 28311552 0.369
BatchNorm2d_280 [1, 128, 16, 12] [1, 128, 16, 12] 256 0.001 49152 0.001
Conv2d_281 [1, 128, 16, 12] [1, 128, 16, 12] 147456 0.517 28311552 0.369
BatchNorm2d_281 [1, 128, 16, 12] [1, 128, 16, 12] 256 0.001 49152 0.001
Conv2d_282 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_282 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_283 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_283 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_284 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_284 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_285 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_285 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_286 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_286 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_287 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_287 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_288 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_288 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_289 [1, 256, 8, 6] [1, 256, 8, 6] 589824 2.067 28311552 0.369
BatchNorm2d_289 [1, 256, 8, 6] [1, 256, 8, 6] 512 0.002 24576 0.000
Conv2d_290 [1, 64, 32, 24] [1, 32, 32, 24] 2048 0.007 1572864 0.020
BatchNorm2d_290 [1, 32, 32, 24] [1, 32, 32, 24] 64 0.000 49152 0.001
Conv2d_291 [1, 128, 16, 12] [1, 32, 16, 12] 4096 0.014 786432 0.010
BatchNorm2d_291 [1, 32, 16, 12] [1, 32, 16, 12] 64 0.000 12288 0.000
Conv2d_292 [1, 256, 8, 6] [1, 32, 8, 6] 8192 0.029 393216 0.005
BatchNorm2d_292 [1, 32, 8, 6] [1, 32, 8, 6] 64 0.000 3072 0.000
--------------------------------------------------------------------------------------------------------
Total Parameters: 27.214M (28,535,552) Total Multiply Adds: 7.154GFLOPs (7681459200)
Number of Layers
Conv2d : 292 layers BatchNorm2d : 292 layers ReLU : 261 layers Bottleneck : 4 layers BasicBlock : 104 layers Upsample : 28 layers HRModule : 8 layers